Study: "Reinforcement learning via self-play" is key to reasoning in language models

A team of researchers from MIT, Cornell University, the University of Washington and Microsoft Research developed a framework called "Reinforcement Learning via Self-Play" (RLSP) that teaches large language models to spend more time working through problems. The approach mirrors techniques used in successful AI models like OpenAI's o1, o3, Deepseek's R1 and Google's Gemini.
RLSP works in three stages: First, the model learns from examples of human or AI reasoning (SFT). Then, it's rewarded for exploring different approaches to problems (RL). Finally, the system checks answers to ensure accuracy and prevent shortcuts (Verifier).
Testing shows promising results. When applied to Llama models, RLSP improved scores on the MATH 500 dataset by 23%. The Qwen2.5-32B-Instruct model saw a 10% boost on AIME 2024 math problems. Even with basic rewards for showing work, the models developed interesting behaviors like backtracking, exploring multiple solutions, and double-checking their answers.
These results are largely in line with findings reported by the team behind Deepseek R1 and R1-Zero, as well as recently by researchers from IN.AI, Tsinghua University and Carnegie Mellon University.
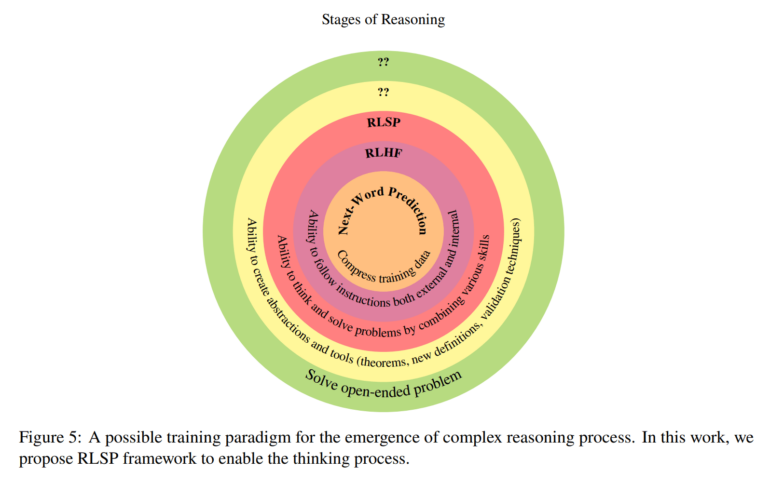
The most notable finding isn't just better test scores - it's how the models learn to solve problems. Even without specific training examples, but with small rewards for exploration, the models developed several useful behaviors across different types of problems.
Why RLSP works
The researchers think they know why this works: Recent studies show that "chain-of-thought" reasoning - where models write out their thinking step by step - gives them more computational power to solve problems. RLSP encourages models to create new reasoning paths through "self-play," similar to how AI learned to master games like chess and Go.
The reward system encourages models to show all their work, even when some approaches don't lead to the right answer. When a model finds the correct solution through a longer reasoning process, it gets full credit. This generates new examples of step-by-step reasoning that help the model improve.
Questions for future research
The team notes several remaining challenges. They want to know how models could adjust their thinking time based on problem difficulty - spending less time on simple math and more on complex proofs. They're also curious about how context length affects reasoning and whether these behaviors truly go beyond what models see in training data.
Other open questions include whether pure reinforcement learning without exploration rewards could improve reasoning in larger models, and what additional training methods might help models develop higher-level thinking skills like forming theorems and tackling open-ended problems.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.