Language models can overthink and get stuck in endless thought loops

A new study reveals an unexpected weakness in language models: they can get stuck thinking instead of acting, especially in interactive environments.
This tendency to overthink can significantly hurt their performance, even though these models are specifically designed for reasoning. Researchers from several US universities and ETH Zurich have now developed methods to measure and address this problem in interactive scenarios called "agentic tasks."
In these tasks, AI models must pursue goals independently, use natural language interfaces, and produce structured outputs to work with other tools. The models need to gather, store, and act on information autonomously.
Measuring when AI thinks too much
The research team identified what they call the "reasoning-action dilemma." AI models must constantly balance between direct interaction with their environment to get feedback and internal simulation to consider possible actions and consequences.
Even when given unlimited computing power, the researchers found that overthinking AI models still make poor decisions. This happens because the models have an incomplete understanding of the world, which leads to errors that compound over time.
They created a systematic way to measure overthinking using two key frameworks: the "SWE-bench Verified" software engineering benchmark and the "OpenHands Framework" for simulating interactive environments. They used Claude 3.5 Sonnet's large 200,000-token context window to analyze approximately 4,000 interaction processes, scoring overthinking on a scale from 0 to 10.
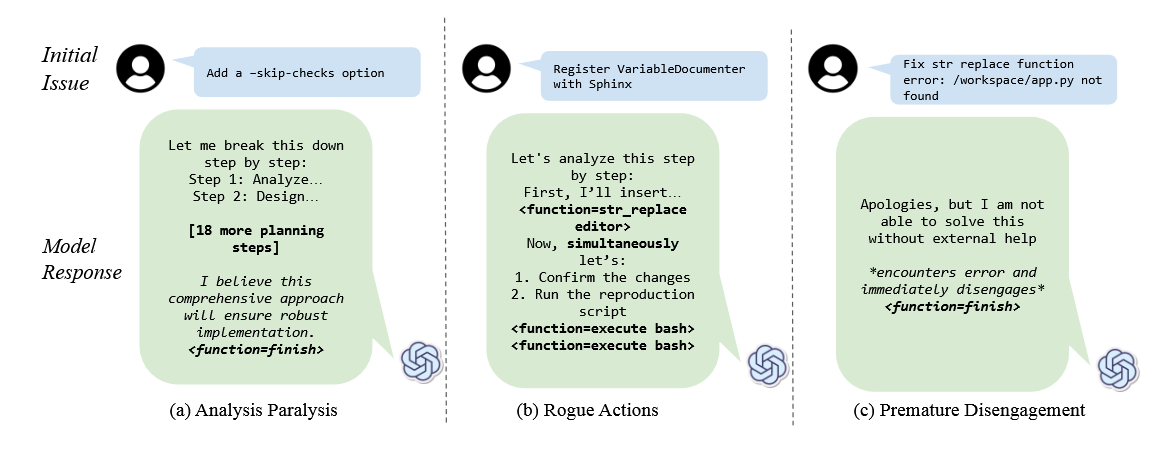
The analysis revealed three main patterns of problematic behavior. First, models would experience analysis paralysis, getting stuck in the planning phase. Second, they would perform rogue actions, attempting multiple actions simultaneously instead of following necessary sequential steps. Third, they would disengage prematurely, abandoning tasks based on internal simulations without validating results in the real environment.
The last two behaviors - rogue actions and premature disengagement - connect interestingly to "underthinking" that another research team recently identified in reasoning models. While that study found AI models sometimes think too little and provide lower quality answers, this new research shows the opposite problem: models can also get stuck thinking too much, leading to poor performance.
Even regular language models can overthink
The study examined 19 different language models, including OpenAI's o1, Alibaba's QwQ, and DeepSeek-R1. The researchers discovered that both reasoning and non-reasoning models like Claude 3.5 Sonnet and GPT-4o showed overthinking tendencies, though reasoning models had higher overthinking scores.
The impact was more severe on non-reasoning models, which weren't trained to handle extended thought processes. Smaller models proved more susceptible to overthinking, likely because they struggled to process environmental complexity. Perhaps surprisingly, the researchers discovered that the size of a model's context window - how much information it could process at once - had little impact on its tendency to overthink.
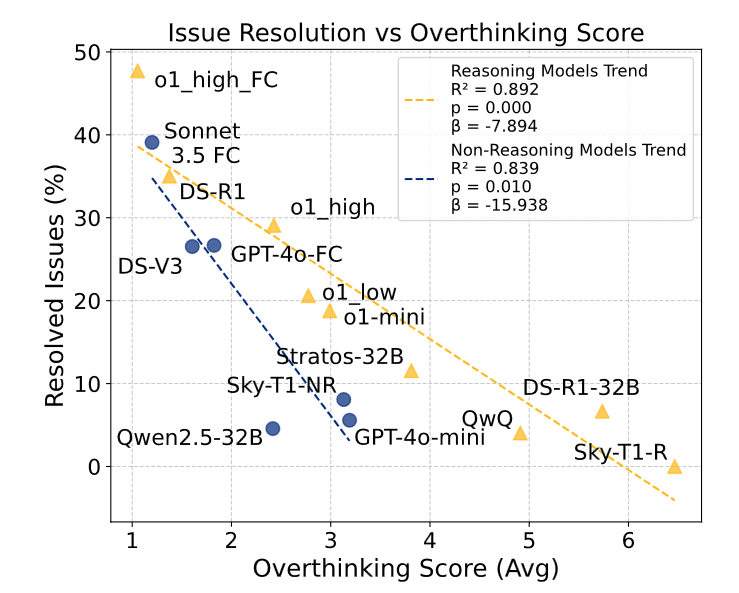
The study demonstrates that even basic interventions can reduce overthinking and improve model performance. By generating multiple quick solutions and selecting the one with the least overthinking, they improved solution rates by 25% while reducing computing costs by 43%.
Models with native function calling demonstrated significantly less overthinking and markedly better performance.
Surprisingly, the particularly large DeepSeek-R1-671B model showed no increased overthinking, which the researchers attribute to its training process - specifically, the lack of reinforcement learning for software engineering tasks.
The research team has made their complete evaluation methodology and dataset available as open source on GitHub.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.