Sesame releases CSM-1B AI voice generator as open source
Update March 14, 2025:
AI company Sesame has released its base model CSM-1B as open source. The code is now available on Github.
The billion-parameter model operates under the Apache 2.0 license, enabling broad commercial use with minimal restrictions. Anyone can test the audio generation capabilities directly. A fine-tuned version of CSM-1B also drives Maya's AI voice system (see below).
Sesame's safety approach consists of guidelines requesting developers and users to avoid unauthorized voice cloning, misleading content creation, or other "harmful" activities. That's it. The model can clone voices with just one minute of source audio, which could enable various forms of voice-based fraud.
This open-source release represents another example of how proprietary AI companies struggle to maintain competitive advantages, with significant implications for AI safety. While OpenAI previously chose not to release similar technology due to safety concerns, the rapid pace of open-source development has made such protective measures largely ineffective.
Original article from March 6, 2025:
Sesame AI shows off impressive voice assistant, has open-source plans
Sesame AI, a California-based startup, is taking an unconventional approach to voice AI by deliberately incorporating imperfections into its speech output. Their new model represents an early step toward more authentic dialogues and what they call "voice presence" in AI systems.
According to early testing, Sesame's most impressive features are subtle elements like micro-pauses, emphasis variations, and laughter during conversations. In one interaction, Sesame's avatar Maya responded in real-time to a user's sudden giggle demonstrating emotional awareness.
The system intentionally incorporates human-like behaviors such as mid-sentence self-corrections, apologies for interruptions, and filler words. Techradar specifically praised these deliberate imperfections, noting how they differ from the polished corporate tone of ChatGPT or Gemini.
In simulated scenarios, like discussions about work stress or party planning, the system provided contextually appropriate responses and questions rather than falling back on generic phrases.
Sesame AI uses semantic and acoustic tokens
While a formal paper hasn't been released yet, Sesame's blog post offers insights into their architecture. Their CSM uses a two-part transformer structure, combining a backbone transformer (1-8 billion parameters) for basic processing with a smaller decoder (100-300 million parameters) for audio generation.
The system processes speech using semantic tokens for linguistic properties and phonetics, alongside acoustic tokens for sound characteristics like pitch and emphasis. To optimize training, the audio decoder trains on just one-sixteenth of the audio frames, while semantic processing uses the complete dataset.
The model trained on one million hours of English audio data across five epochs. It can process sequences of up to 2,048 tokens (about two minutes of audio) in an end-to-end architecture. This approach differs from traditional text-to-speech systems through its integrated processing of text and audio.
While not directly stated in the blog post, the demo voice reveals that it uses a 27-billion parameter version of Google's open-source LLM Gemma.
Testing reveals near-human performance
In blind tests with Sesame, participants couldn't distinguish between CSM and real humans during short conversation snippets. However, longer dialogues still revealed limitations like occasional unnatural pauses and audio artifacts.
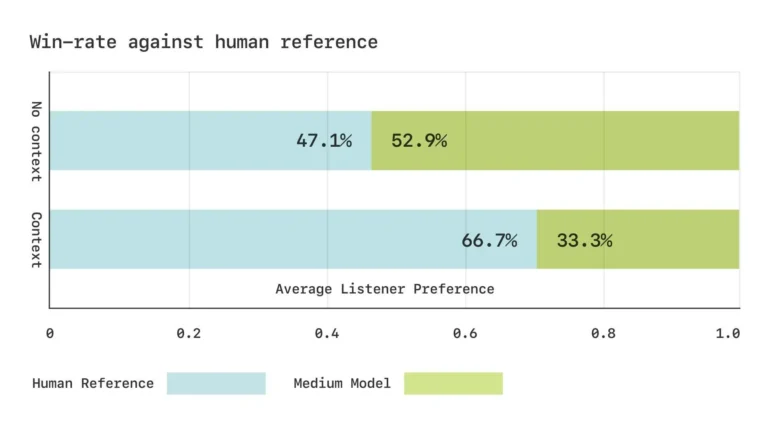
Sesame developed custom phonetic benchmarks to measure model performance. In listening tests, participants rated the generated speech as equivalent to real recordings when heard without context, though they still preferred the original when context was provided.
Future developments and open source plans
Sesame plans to release key components of their research as open source under the Apache 2.0 license. In coming months, they aim to scale up both model size and training scope, with plans to expand to over 20 languages.
The company is focusing particularly on integrating pre-trained language models and developing fully duplex-capable systems that can learn conversation dynamics like speaker transitions, pauses, and pacing directly from data. This development would require fundamental changes throughout the processing pipeline, from data curation to post-training methods.
"Building a digital companion with voice presence is not easy, but we are making steady progress on multiple fronts, including personality, memory, expressivity and appropriateness," the developers note.
Founded by former Oculus CTO Brendan Iribe and his team, Sesame AI secured significant Series A funding led by Andreessen Horowitz. A demo is available.
The impact of natural AI voices on assistant adoption was demonstrated by the excitement around ChatGPT's Advanced Voice Mode. Voice assistants powered by LLMs are likely to become increasingly prevalent, as suggested by Amazon's release of Alexa+.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.