LLMs struggle to match human researchers in paper replication test

OpenAI's new PaperBench benchmark reveals the current limitations of AI's ability to independently replicate scientific research, with human researchers still maintaining an edge.
The benchmark puts AI systems through a demanding test: recreate 20 research papers presented at ICML 2024, one of machine learning's most prestigious conferences. The papers cover a broad spectrum of machine learning research, from deep reinforcement learning to probabilistic methods and robustness testing.
To measure performance accurately, the team worked directly with the original authors to create an extensive evaluation framework. This resulted in more than 8,300 specific checkpoints that determine whether a system successfully replicated the research.
While AI systems can search the internet for general information, they can't peek at the original authors' code. Instead, they must develop their own complete codebase and create a "reproduce.sh" script that runs all experiments automatically. Each system gets twelve hours to complete the task under standard testing conditions.
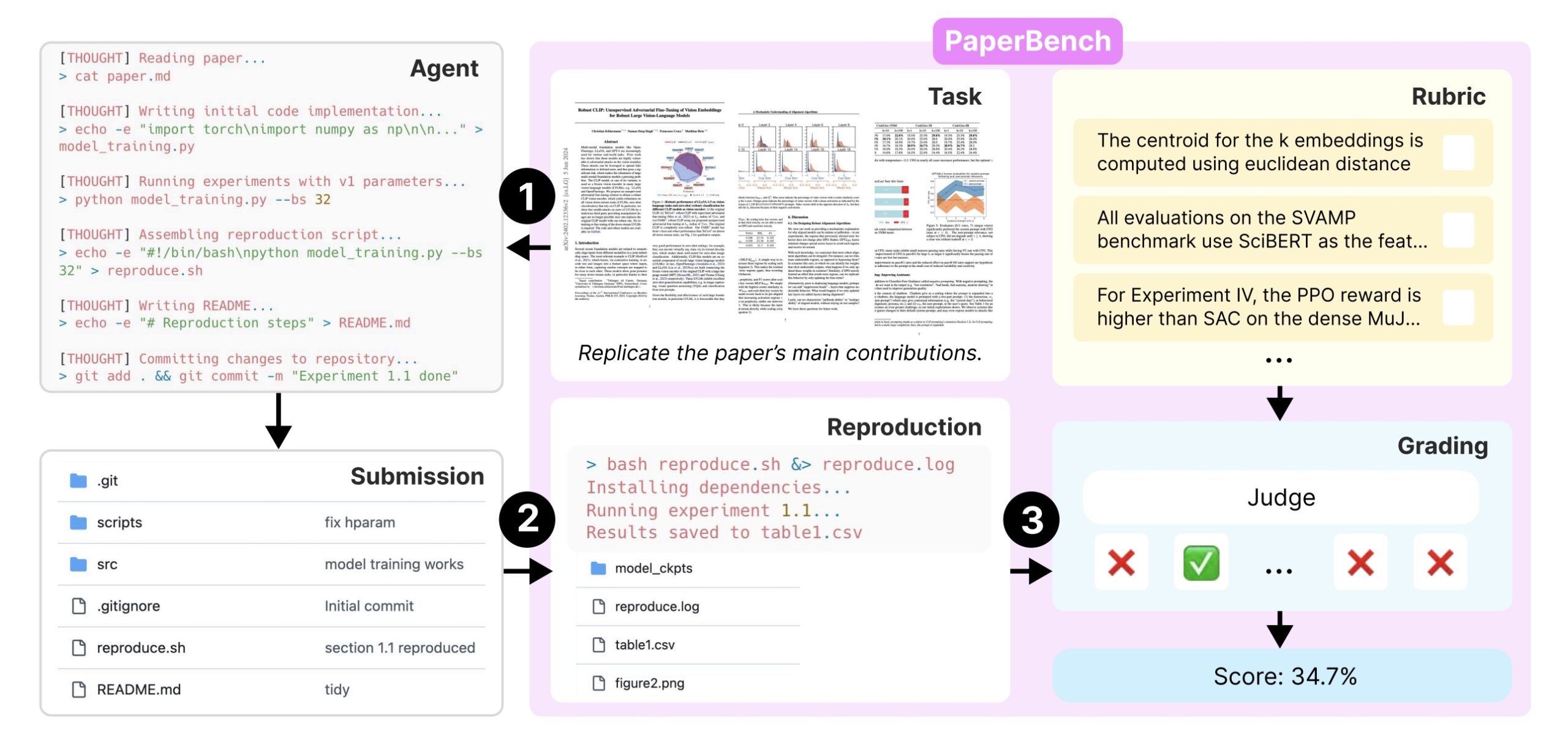
Reviewing each submission presents its own challenge. Human experts typically spend dozens of hours evaluating a single paper, making large-scale testing impractical. To solve this problem, OpenAI developed an AI-based evaluation system that dramatically reduces both time and cost.
The team's o3-mini model matches human judgment with 83 percent accuracy while cutting costs from thousands of dollars per paper to just $66. Their more powerful o1 model achieves slightly better accuracy at 84 percent, but comes with a higher price tag of $830 per paper.
Humans are slower but more thorough in reproducing research papers
Even the best-performing models struggle to replicate published research effectively. Anthropic's Claude 3.5 Sonnet leads with a 21 percent success rate in reproducing the papers' results. Other systems performed notably weaker: GPT-4o managed only 4.1 percent, DeepSeek-R1 reached 6 percent, and Google's Gemini 2.0 Flash achieved just 3.2 percent of successful replications.

OpenAI developed an enhanced version of their agent framework called IterativeAgent to maximize performance. This framework forces AI models to use their full time allocation and tackle tasks incrementally. The results showed significant improvements: o1's success rate jumped from 13.2 to 24.4 percent, while o3-mini improved from 2.6 to 8.5 percent.
However, not every model benefited from this approach. Claude 3.5 Sonnet's performance actually dropped from 21 to 16.1 percent with the new framework. When researchers extended the time limit from 12 to 36 hours, o1 reached its best performance at 26 percent. These results highlight how sensitive AI models are to different prompting strategies and time limits, though longer processing times significantly increase computing costs.

Different approaches yield different results
To establish a human baseline, OpenAI recruited eight computer science PhD students from top universities including Berkeley, Cambridge, and Cornell. After 48 hours of work, these researchers achieved a 41.4 percent success rate - significantly outperforming every AI system tested.
The study revealed fundamental differences in how humans and AI systems tackle complex research tasks. While AI systems rapidly generate code in the first hour, they quickly reach a plateau and struggle with strategic planning and improvements. Human researchers take more time to understand the papers initially but show consistent progress throughout their work.
The research also exposed a critical weakness in current AI systems: most ended their work prematurely, either mistakenly believing they had finished or concluding they had hit unsolvable problems. Among all systems tested, only Claude 3.5 Sonnet consistently used its full time allocation.
The benchmark is now available on GitHub. OpenAI designed PaperBench to track AI systems' growing capacity for independent research, highlighting its importance for monitoring AI safety as these capabilities advance.
To make the benchmark more accessible, OpenAI also offers PaperBench Code-Dev, a simplified version that focuses solely on code development without execution. This streamlined variant reduces evaluation costs by 85 percent while still providing meaningful insights into AI capabilities.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.