Meta releases first multimodal Llama-4 models, leaves EU out in the cold
Meta has released the first two models in its Llama 4 series, marking the company’s initial deployment of a multimodal architecture built from the ground up.
Both models—Llama 4 Scout and Llama 4 Maverick—use a Mixture-of-Experts (MoE) design, where only a subset of parameters is activated per input, reducing computational overhead.
According to Meta, these are the first Llama models capable of processing both text and images within a shared architecture. The company says the models were trained on a wide range of images and videos to support broad visual understanding. During pre-training, the system processed up to 48 images simultaneously. In post-training evaluations, it demonstrated strong performance with up to eight images as input.
Llama 4 Scout targets single-GPU multimodal tasks
The smaller of the two models, Llama 4 Scout, uses 17 billion active parameters from a total of 109 billion, distributed across 16 experts. It is optimized to run on a single H100 GPU and is designed for tasks such as long-form text processing, visual question answering, code analysis, and multi-image understanding.
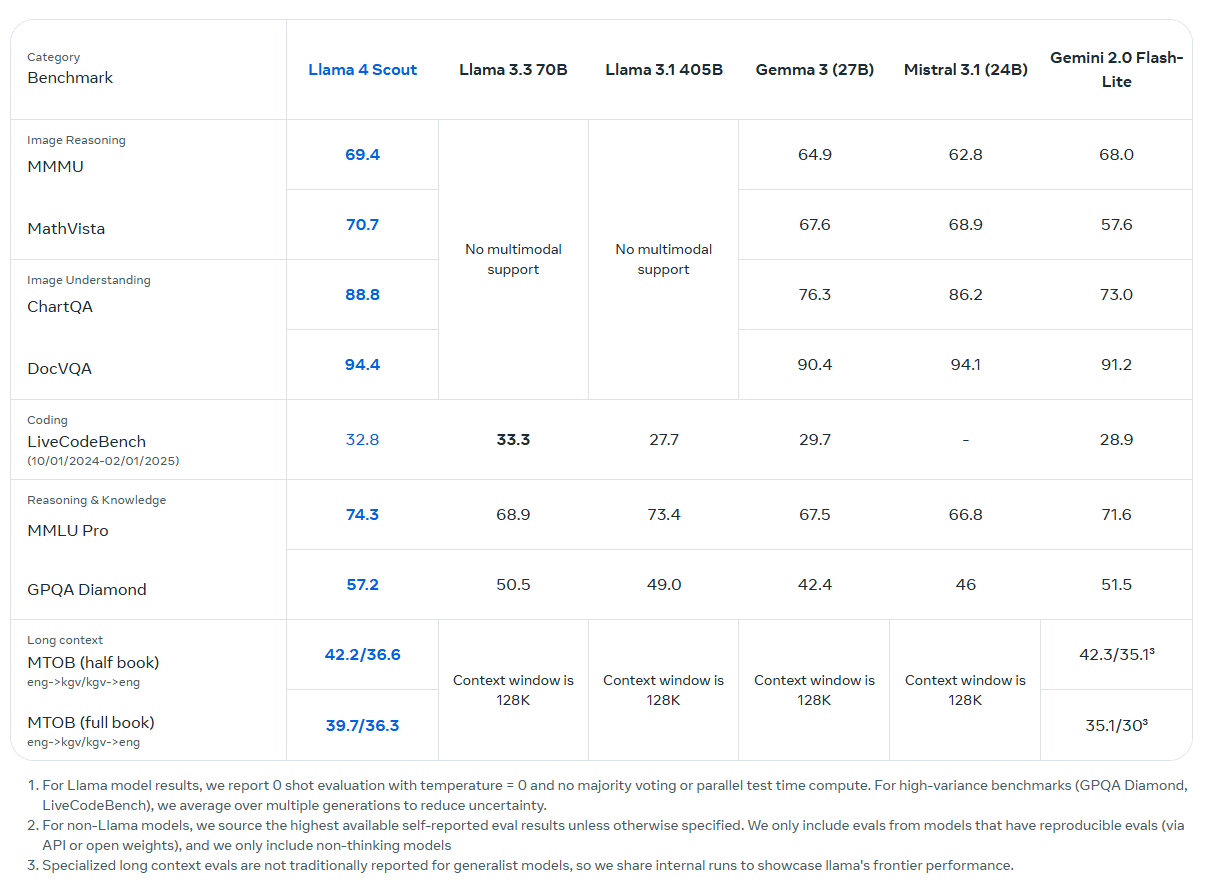
Scout features a 10-million token context window - approximately 5 million words and longer. While impressive in scale, Meta hasn't addressed how effectively it processes complex queries beyond simple word searches. The company's use of the outdated "Needle in the Haystack" benchmark for context window testing suggests limitations, especially given the availability of more sophisticated benchmarks. All language models still show limitations across both text and image understanding.
In addition, the model was trained with a context length of only 256K tokens during both pre-training and post-training. The advertised 10-million-token window is based on length generalization rather than direct training.
Llama 4 Maverick expands scalability and performance
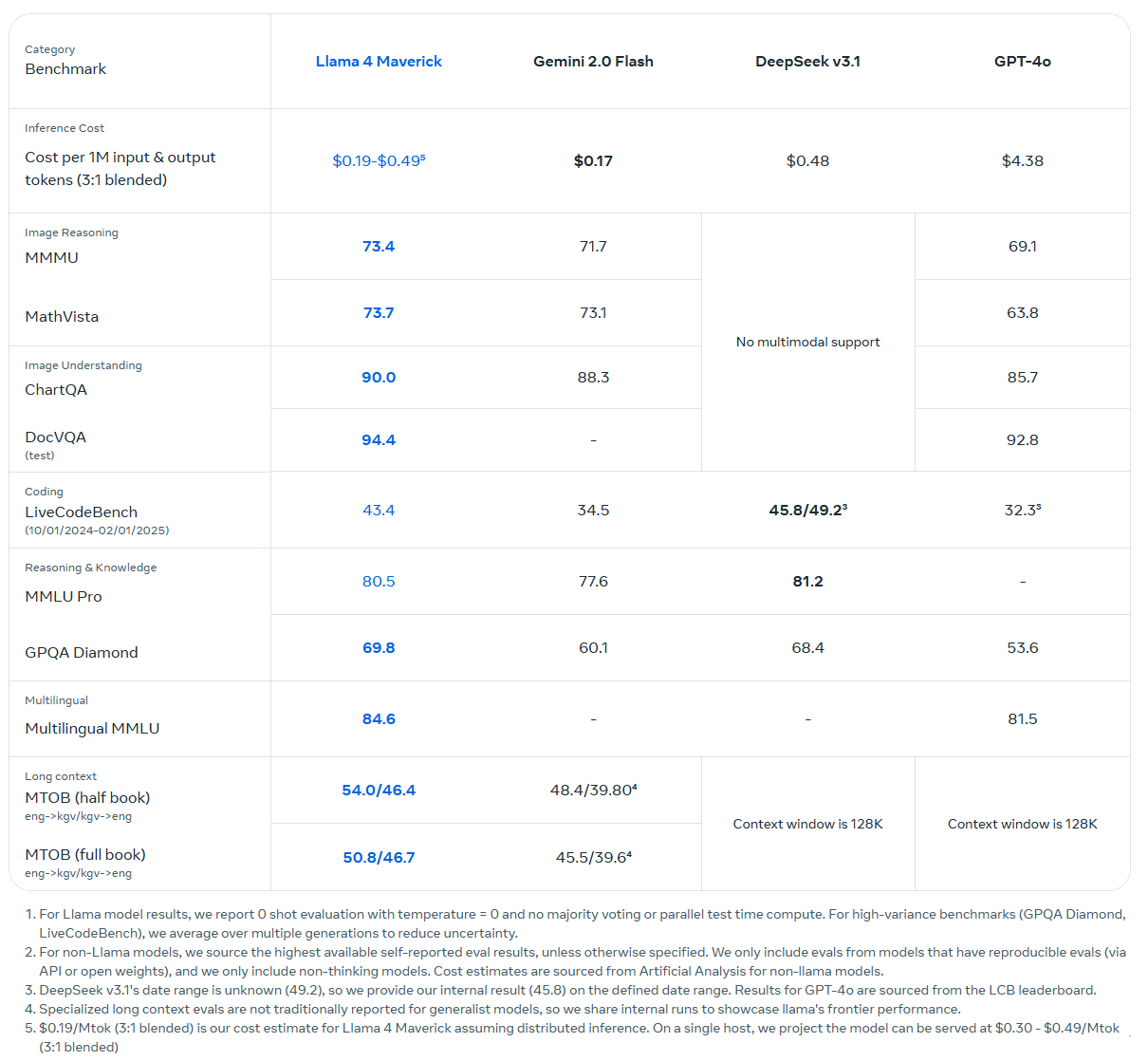
Llama 4 Maverick also uses 17 billion active parameters, but draws from a total of 400 billion distributed across 128 experts. Like Scout, it uses a mixture-of-experts architecture, which reduces computational overhead by activating only a subset of experts for each input. Despite these efficiency gains, the model still requires a full H100 host for deployment due to its scale. It supports context windows of up to one million tokens.
Meta reports that Llama 4 Maverick outperforms OpenAI’s GPT-4o and Google’s Gemini 2.0 Flash across several benchmark evaluations. The model also achieves results comparable to Deepseek-V3 in reasoning and code generation tasks, despite using less than half the number of active parameters. In its experimental chat configuration, Maverick scores 1417 on the LMArena ELO ranking.
Both Scout and Maverick are available as open-weight models via llama.com and Hugging Face. Meta has also integrated them into products including WhatsApp, Messenger, Instagram Direct, and Meta.ai. Additional Llama 4 models are expected to be announced at LlamaCon on April 29. Registration is available here.
Llama 4 "Behemoth" serves as teacher model
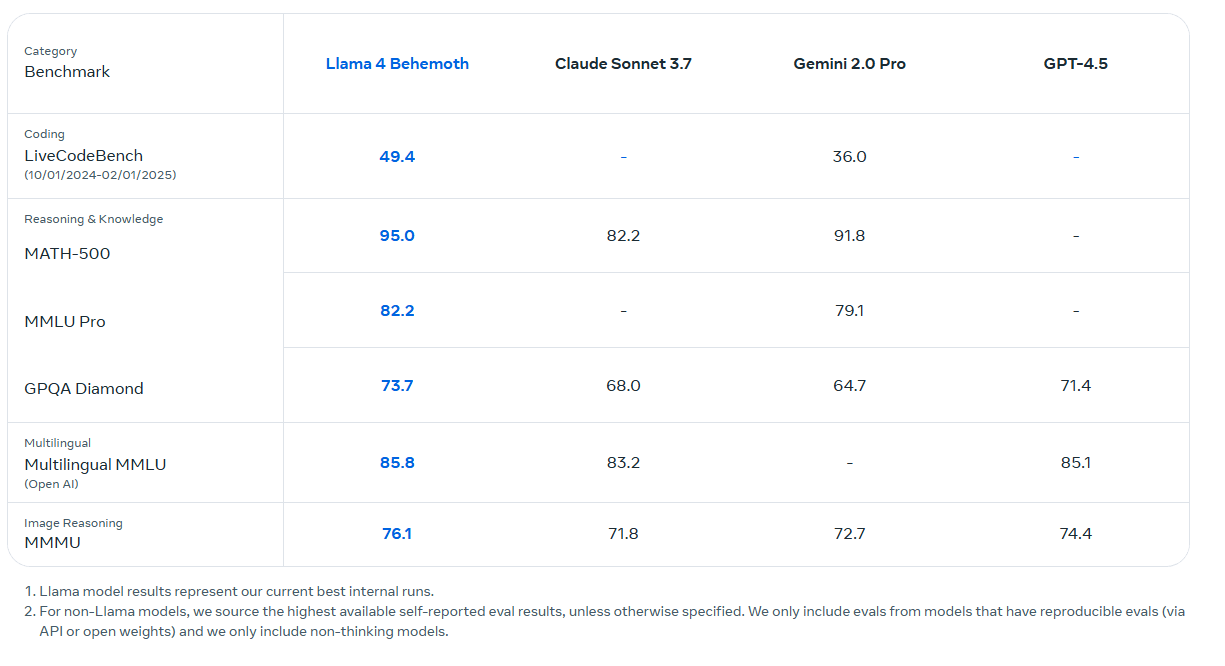
Scout and Maverick were trained using Llama 4 Behemoth, a larger internal model with 288 billion active parameters out of a total of 2 trillion, distributed across 16 experts. Behemoth acts as a teacher model and, according to Meta, surpasses GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro in mathematical and scientific benchmarks.
However, Meta has not published a comparison with Google’s more recent Gemini 2.5 Pro, which currently leads in reasoning evaluations. Behemoth is still in training and is expected to be released at a later stage. A dedicated Llama model for reasoning has not yet been released, though Meta CEO Mark Zuckerberg said in January that one is on the way.
After pre-training, Meta applies multiple post-training stages to improve model performance. This includes supervised fine-tuning with curated examples, followed by online reinforcement learning, using a new asynchronous system that reportedly increases training efficiency tenfold.
Direct Preference Optimization is then used to refine output quality, with an emphasis on removing trivial examples. According to Meta, more than half of Maverick’s training set and 95 percent of Behemoth’s were filtered out to focus the models on more difficult tasks.
EU excluded from using Llama 4 multimodal models
Meta is releasing the Llama 4 models under its standard Llama license, but with a new limitation: companies and individuals based in the EU are excluded from using the multimodal models. This restriction does not apply to end users.

According to Meta, the move is due to "regulatory uncertainties" surrounding the EU AI Act. The decision reflects ongoing tensions between Meta and EU policymakers, with Meta pushing either for clearer guidance or less restrictive regulations, depending on interpretation.
Developers elsewhere must display a visible "Built with Llama" label and may only use model names prefixed with "Llama." Platforms with over 700 million monthly active users must obtain special permission from Meta.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.