
Google Gemini 1.5 offers a context window with up to one million tokens to process entire books or even movies in one prompt. But is it accurate?
After all, what is the point of summarizing a text or analyzing an annual report if you have to assume that important details are missing.
This is currently the case for other language models with large context windows, such as GPT-4 Turbo with 128K or Claude 2 with up to 200K.
In daily practice, I have found that even models with "small" context windows of 8K to 32K can miss relevant details, especially in the middle of text.
This can happen even when they are fed only small amounts of text, such as 500 words, and are explicitly instructed in the prompt to pay attention to every detail in the source text.
This LLM phenomenon is known as "lost in the middle," and it's exacerbated by larger context windows. LLMs skipping content is by far their worst drawback, even worse than hallucinations in my opinion. So fixing this would be huge.
And if you read social media these days, it looks like Google may have fixed it. But their technical paper doesn't support that.
It is true that when searching for a single, specific piece of information in the "needle in a haystack" test, Gemini 1.5 achieves a hit rate of up to 100 percent over the entire context length, according to Google.
But in Google's benchmarks, GPT-4 Turbo also achieves perfect accuracy up to 128K. However, we know from theory and practice that GPT-4 Turbo 128K does not work reliably with long summaries and analyses.

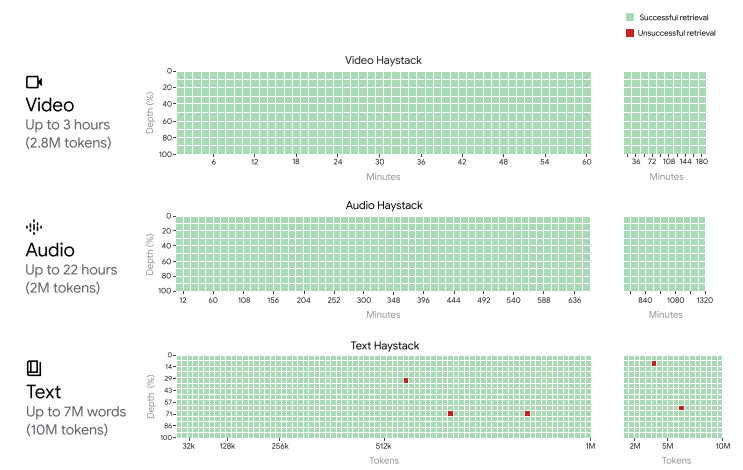
If you dig a little deeper into Google's technical report for Gemini 1.5, you will find a graphic that shows that Google has not yet solved the lost-in-the-middle problem.
The more complex retrieval task "multiple needles in a haystack" test, in which up to 100 specific pieces of information are extracted from the text, shows an average accuracy of between 60 and 70 percent, with numerous outliers below the 60 percent mark.
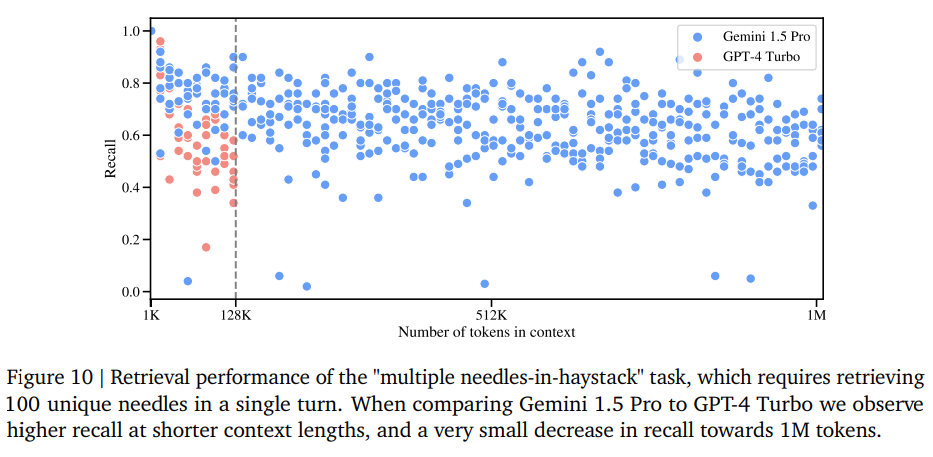
This seems to be an improvement over GPT-4 Turbo up to 128K, and the accuracy appears to be fairly evenly distributed across the context window, which is good.
But would you hire a text analyst to summarize a document if you knew they'd probably ignore 30 percent of the content?
Moreover, even the "multiple needles in a haystack" test is simplistic compared to most real-world application scenarios, where you are not looking for specific information in a set of data, but rather solving complex tasks such as summaries and analyzes.
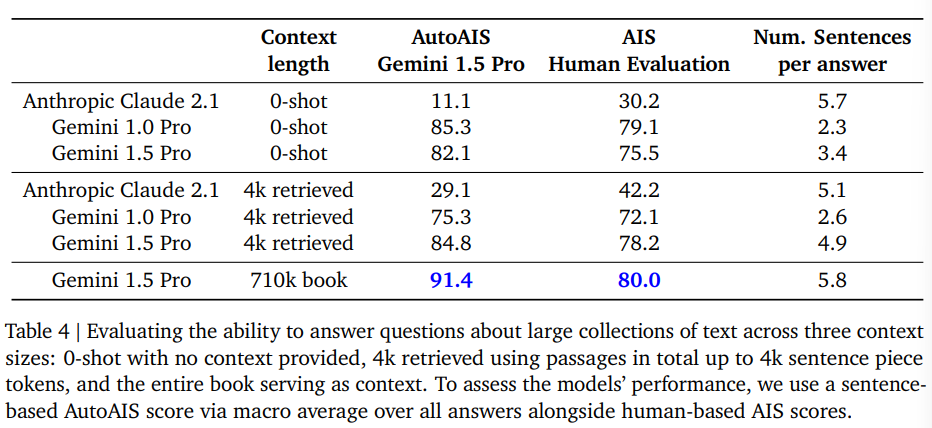
Google conducted a more complex test on 'Les Misérables' by Victor Hugo. They asked 100 questions, totaling 710,000 tokens, and evaluated the answers using the 'Attributable to Identified Sources' method. In the human evaluation, 80% of the answers could be attributed to the source document, while in the machine evaluation, 91% could be attributed to the source.
However, this benchmark does not say anything about the completeness of the statements and their nuances. It cannot be used to judge whether the book and characters are rendered as Victor Hugo intended. In addition, Gemini 1.5 Pro lagged behind Gemini 1.0 with an additional knowledge base (RAG) for prompts without additional context (0-shot).
Although there are many positive reviews on social media from those who have access to Gemini 1.5, these reviews seemingly often only cover functional testing and lack in-depth analysis.
While these reviews demonstrate the model's ability to analyze the entire context window, determining the accuracy of a summary requires excellent knowledge of the source material.
If information retrieval is not highly reliable, even for complex queries, a large context window may be an impressive technical benchmark, but in practice, it is likely to be of little value or may even reduce information quality if used carelessly or with too much trust.


