Google upgrades Gemini 2.5 Pro with a new Deep Think mode for advanced reasoning abilities
Google is testing a new experimental mode for Gemini 2.5 Pro that adds deeper reasoning capabilities and native audio output.
The new mode, called "Deep Think," is designed to help the model evaluate multiple hypotheses before answering a prompt. According to Google, it’s based on new research methods and is currently being tested with a limited group of Gemini API users.
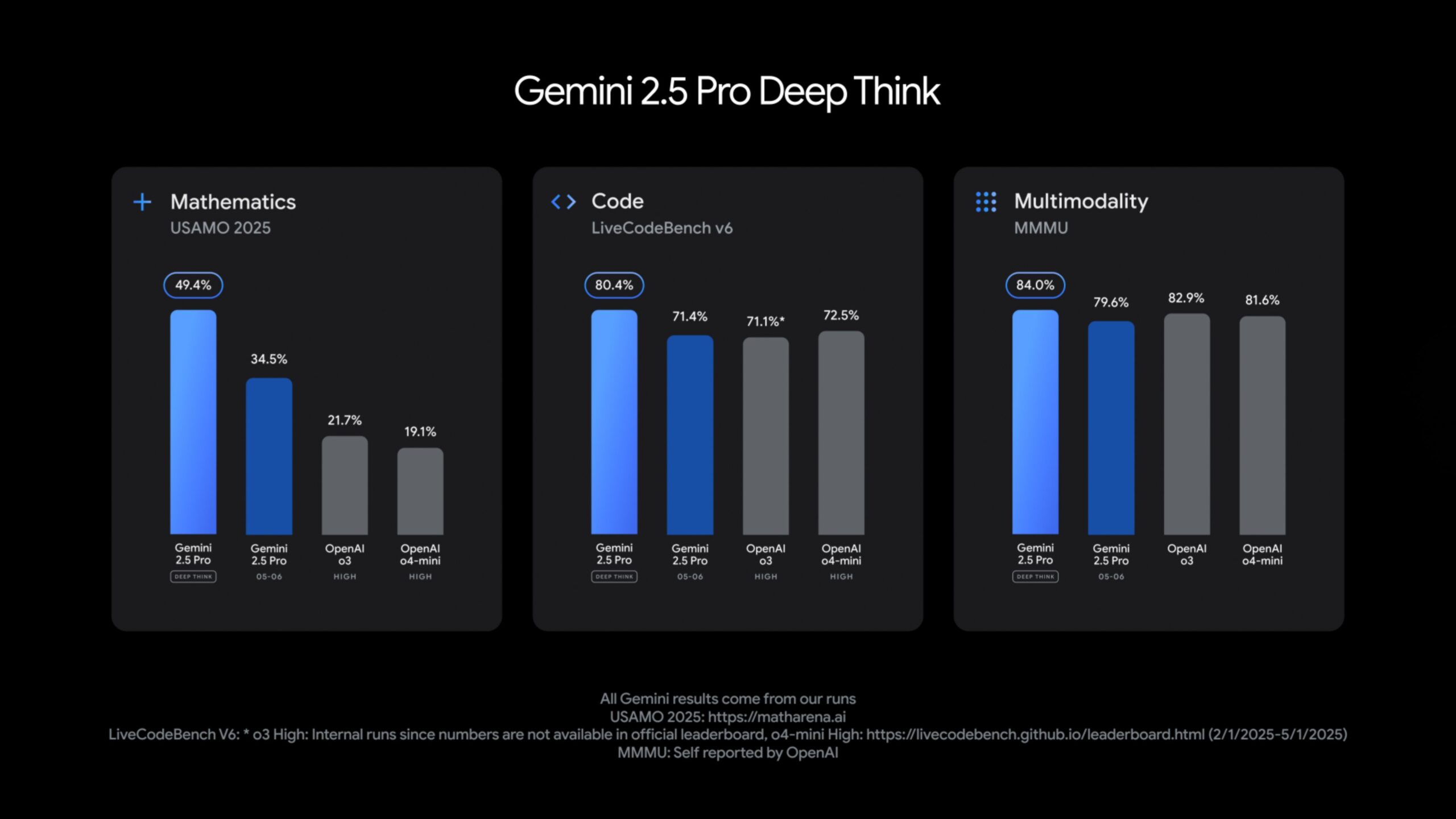
Google says Gemini 2.5 Pro with Deep Think beats OpenAI’s o3 model on several tasks, including the USAMO 2025 math test, the LiveCodeBench programming benchmark, and MMMU, a test for multimodal reasoning.
Google has also upgraded its 2.5 Flash model, which is optimized for speed and efficiency. The latest version performs better on reasoning, multimodal tasks, and code generation, while using 20 to 30 percent fewer tokens for the same output.
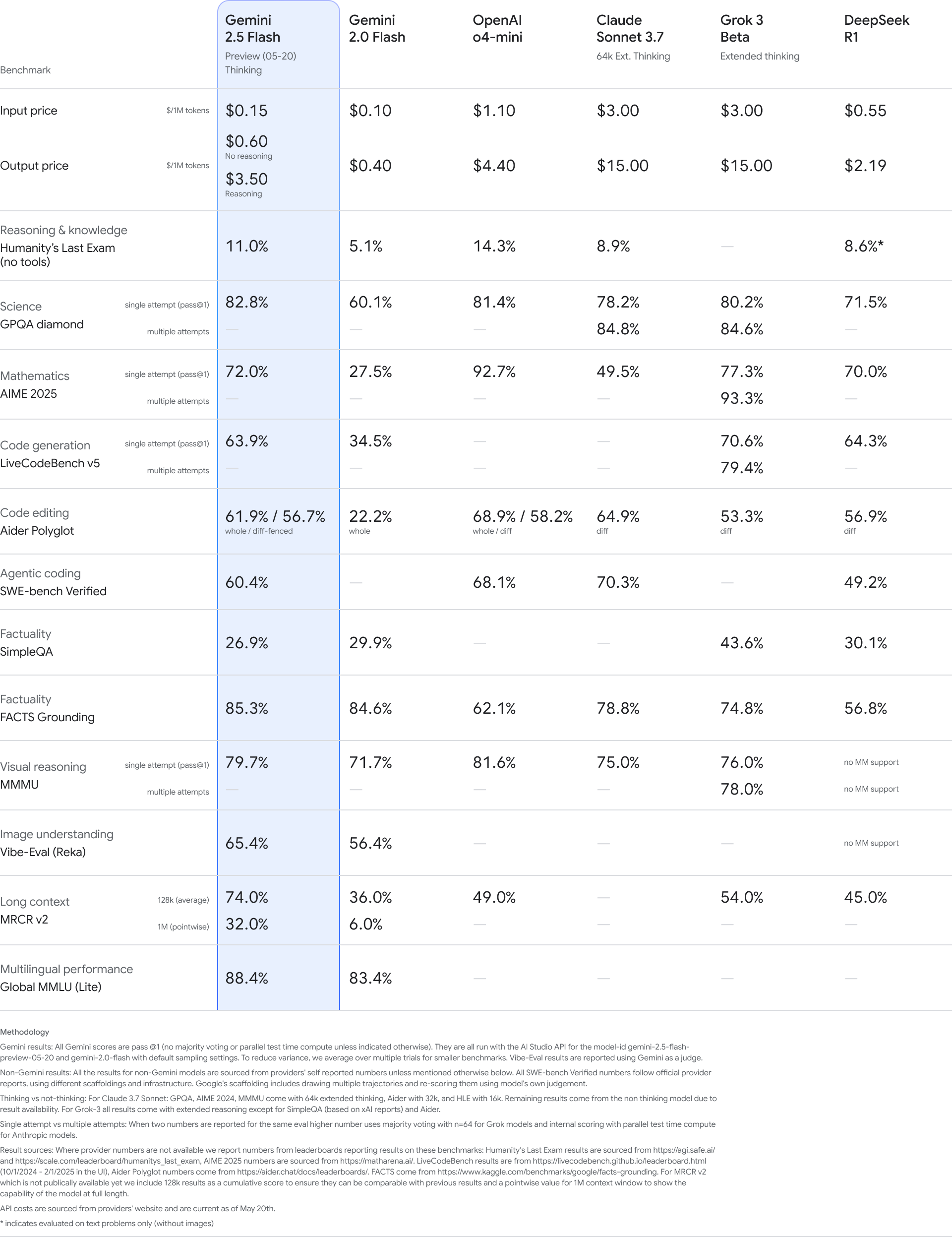
Gemini 2.5 Flash is now available in Google AI Studio, Vertex AI, and the Gemini app. General availability for production use is expected in early June.
New audio features and computer control
Both Gemini 2.5 Pro and Flash now support native text-to-speech with multiple speaker profiles. The voice output can capture subtle effects like whispers and emotional tone, and supports more than 24 languages. Developers can control accent, tone, and speaking style through the Live API.
Two new features—"Affective Dialogue" and "Proactive Audio"—aim to make voice interactions feel more natural. Affective Dialogue allows the model to detect emotion in a user's voice and respond accordingly—whether that’s neutrally, empathetically, or in a cheerful tone.
Proactive Audio helps filter out background conversations, so the AI only responds when it's directly addressed. The goal is to reduce accidental interactions and make voice control more reliable.
Google is also bringing features from Project Mariner into the Gemini API and Vertex AI, allowing the model to control computer applications like a web browser.
For developers, Gemini now includes "thought summaries", a structured view of the model’s internal reasoning and the actions it takes. To manage performance, developers can configure "thinking budgets" to limit or disable the number of tokens the model uses for reasoning.
The Gemini API also now supports Anthropic's Model Context Protocol (MCP), which could make it easier to integrate with open-source tools. Google is exploring hosted MCP servers to support agent-based application development.
Google's open-source model Gemma goes multimodal
Google has added a new entry to its AI lineup with Gemma 3n, a lightweight, open-source model built specifically for mobile devices like smartphones, tablets, and laptops. The model is based on a new architecture developed in collaboration with hardware partners including Qualcomm, MediaTek, and Samsung.
Gemma 3n is designed to deliver powerful multimodal capabilities while keeping resource usage low. The 5B and 8B parameter versions require just 2 to 3 GB of RAM, making them suitable for on-device applications.
The model supports text, audio, and image processing, and can handle tasks like transcription, translation, and processing of mixed inputs across different modalities. A key feature is "Mix-n-Match," which allows developers to extract smaller sub-models from the main architecture depending on the use case.
Google has also improved Gemma 3n’s multilingual capabilities, particularly for languages like German, Japanese, Korean, Spanish, and French. A preview version of the model is now available through Google AI Studio and the AI Edge Toolkit for local development.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.