Sakana AI's ALE AI agent cracks the top 21 among 1,000 code experts

Japanese company Sakana AI built an AI agent that can tackle complex optimization problems used in industry. In a live competition, their AI went head-to-head with more than 1,000 human programmers.
Sakana AI's ALE agent landed in 21st place at the 47th AtCoder Heuristic Contest, proving AI systems can hold their own against human experts in demanding programming challenges. AtCoder runs Japanese programming competitions where participants solve complex mathematical problems through code. These "NP-hard" problems don't have known efficient solutions, making them particularly challenging.
The tasks mirror real industrial headaches: planning delivery routes, organizing work shifts, managing factory production, and balancing power grids. Human contestants typically spend weeks refining their solutions.
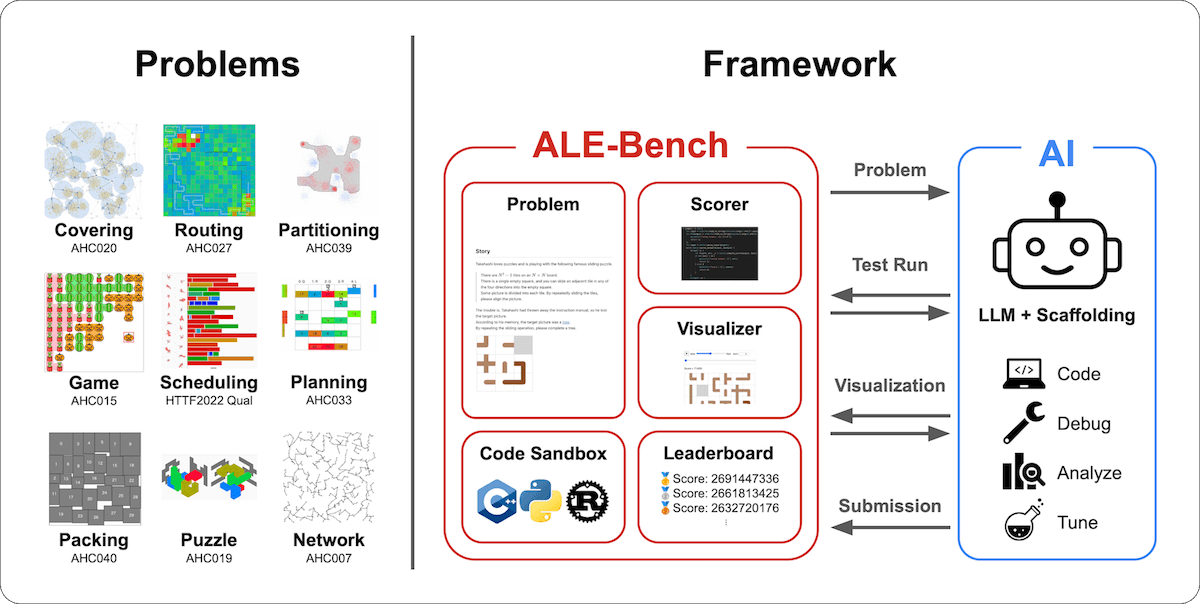
The work builds on ALE-Bench, what Sakana AI calls the first benchmark for score-based algorithmic programming. The benchmark pulls from 40 tough optimization problems from past AtCoder contests. Unlike traditional tests that just mark answers right or wrong, ALE-Bench demands continuous improvement over extended periods.
AI Agent mixes expert knowledge with smart search
The ALE agent runs on Google's Gemini 2.5 Pro and combines two main strategies. First, it bakes expert knowledge about proven solution methods directly into its instructions. This includes techniques like simulated annealing, which tests random changes to solutions and sometimes accepts worse results to escape local dead ends.
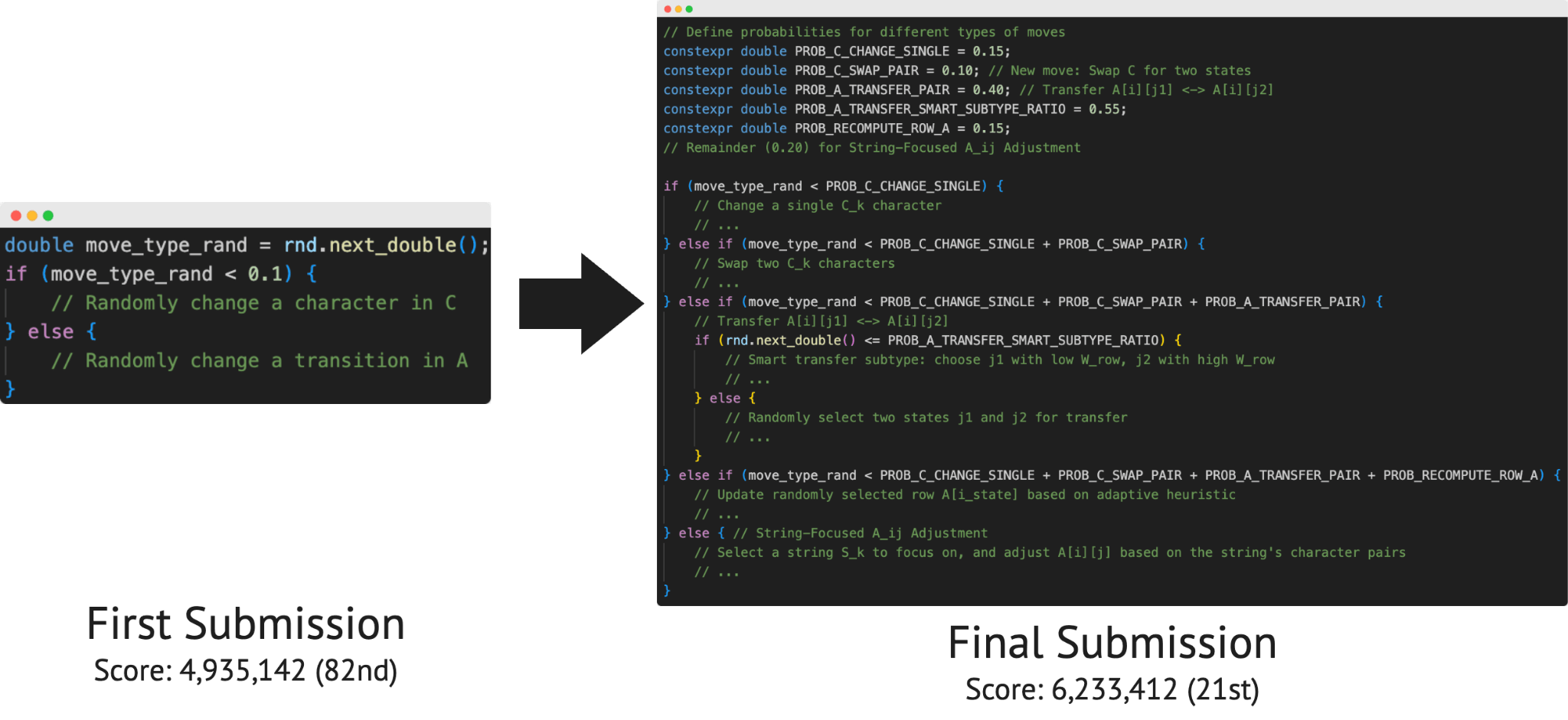
Second, the system uses a systematic search algorithm called "best-first search" that always picks the most promising partial solution and develops it further. The agent expands this with a "beam search"-like approach, pursuing 30 different solution paths simultaneously. It also uses a "taboo search" mechanism that remembers previously tested solutions to avoid repeating them.
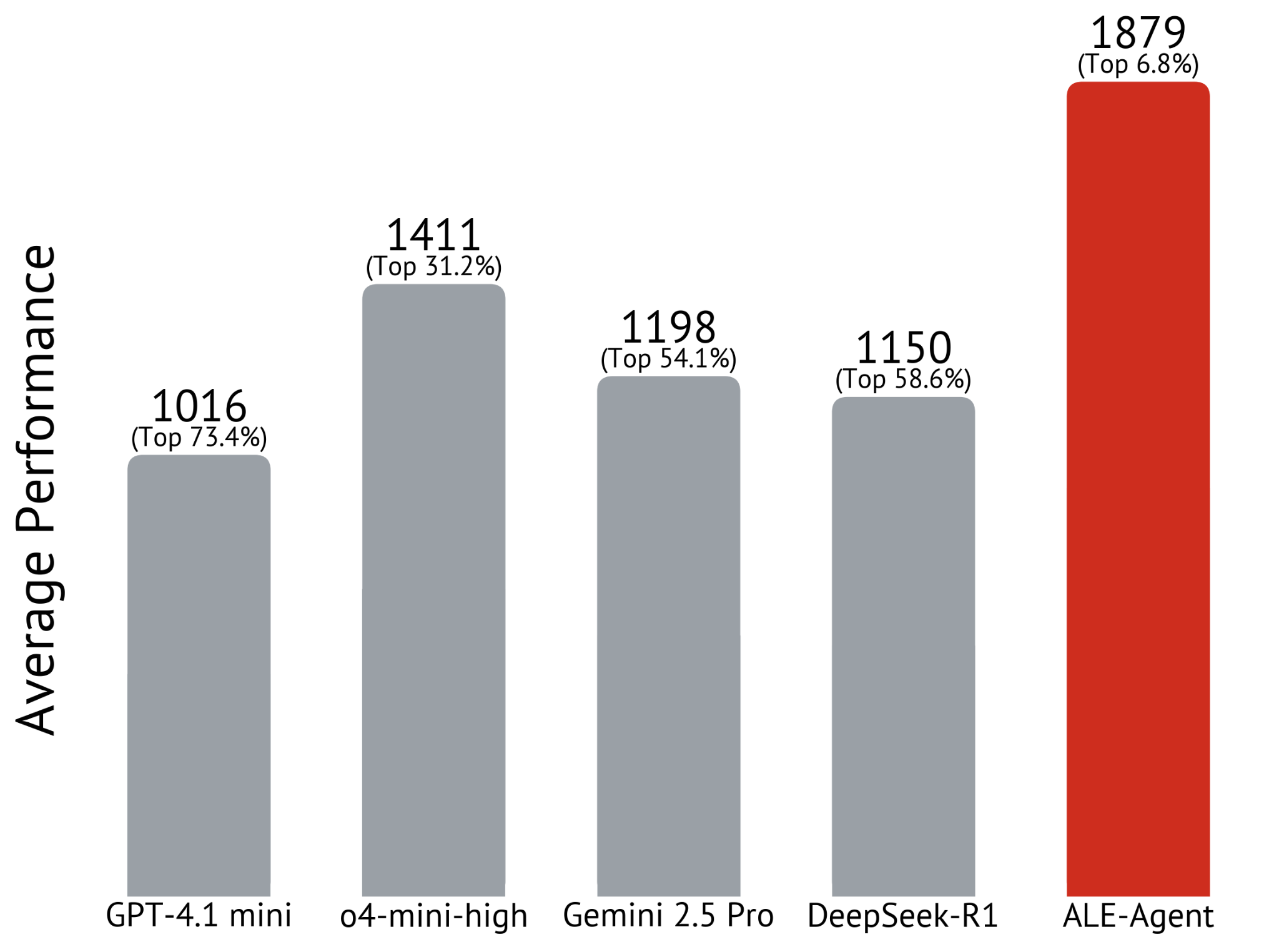
In testing, the best model (o4-mini-high) hit 1,411 points with sequential improvements. Under identical conditions, GPT-4.1 mini scored 1,016 points, Deepseek-R1 reached 1,150 points, and Gemini 2.5 Pro achieved 1,198 points.
The full ALE agent beat these results with 1,879 points, landing it in the top 6.8 percent. On one specific problem, the agent scored 2,880 points, which would have earned 5th place in the original competition.
One major difference between the AI and human contestants shows up in their approach. While humans might test a dozen different solutions during a four-hour competition, Sakana's AI can cycle through around 100 versions in the same timeframe. The ALE agent actually churned out hundreds or thousands of potential solutions - something no human could match.
Sakana AI released ALE-Bench as a Python library with a built-in "code sandbox" for safe testing. The framework works with C++, Python, and Rust, running on standard Amazon cloud infrastructure. The company developed the benchmark with AtCoder Inc. The data from 40 competition problems is available on Hugging Face, and the code is publicly accessible on GitHub.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.