Alibaba's Qwen2.5 only excels at math thanks to memorized training data

A new study finds that Alibaba's Qwen2.5 models achieve high math scores mainly by memorizing training data rather than through genuine reasoning.
Researchers discovered that what appears to be progress in mathematical reasoning is largely due to data contamination. When tested on "clean" benchmarks that the model had not seen during training, Qwen2.5's performance dropped sharply.
To test this, the team gave Qwen2.5 only the first 60 percent of problems from the MATH 500 benchmark and asked it to complete the rest. Qwen2.5-Math-7B managed to reconstruct the missing 40 percent with 54.6 percent accuracy and answer correctly 53.6 percent of the time. In comparison, Llama3.1-8B managed just 3.8 and 2.4 percent. This suggests Qwen2.5 had already encountered these problems during training.
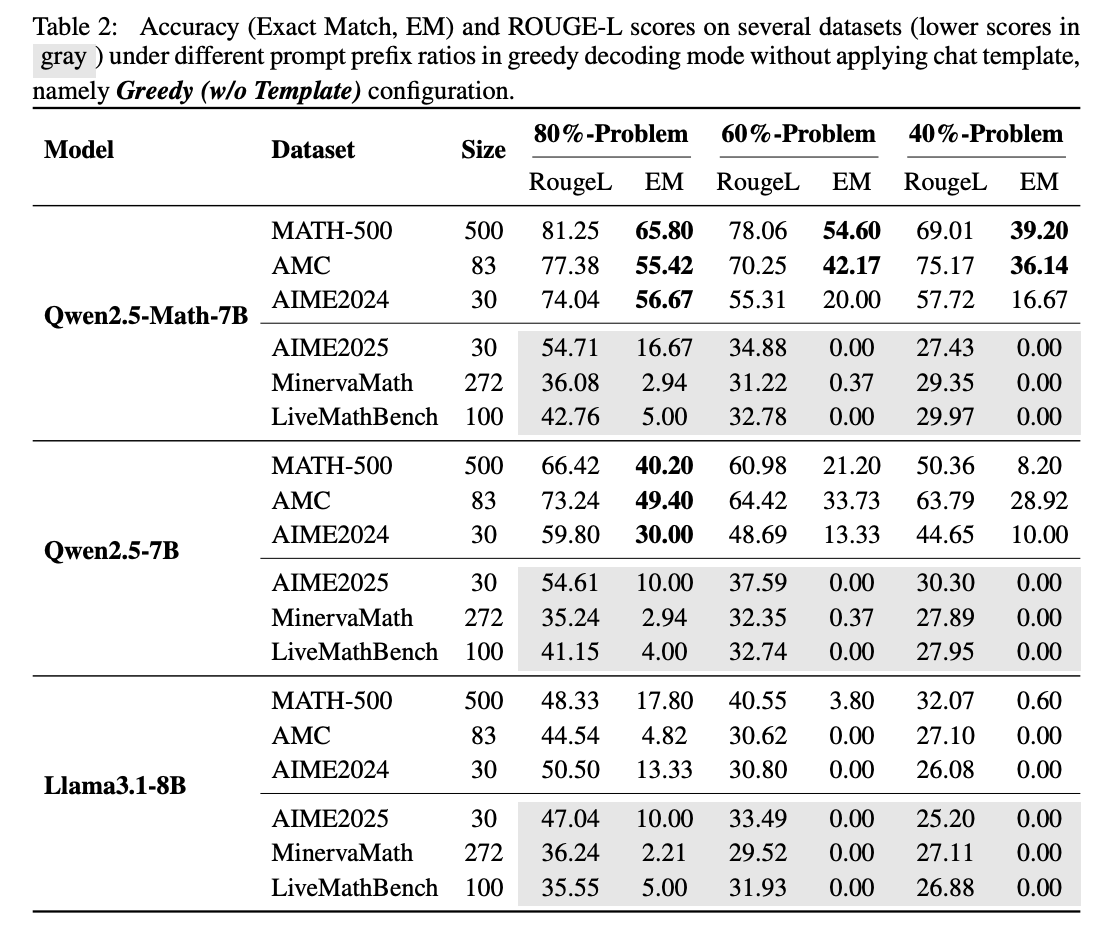
The researchers then tested the model with LiveMathBench (version 202505), a "clean" benchmark released after Qwen2.5. On this dataset, Qwen2.5's completion rate dropped to zero, matching Llama, and its answer accuracy fell to just two percent.
The likely reason is that Qwen2.5 was pre-trained on large online datasets, including GitHub repositories containing benchmark problems and their solutions. As a result, even random or incorrect reward signals during training could improve its results on MATH-500 because of its prior exposure to the data.
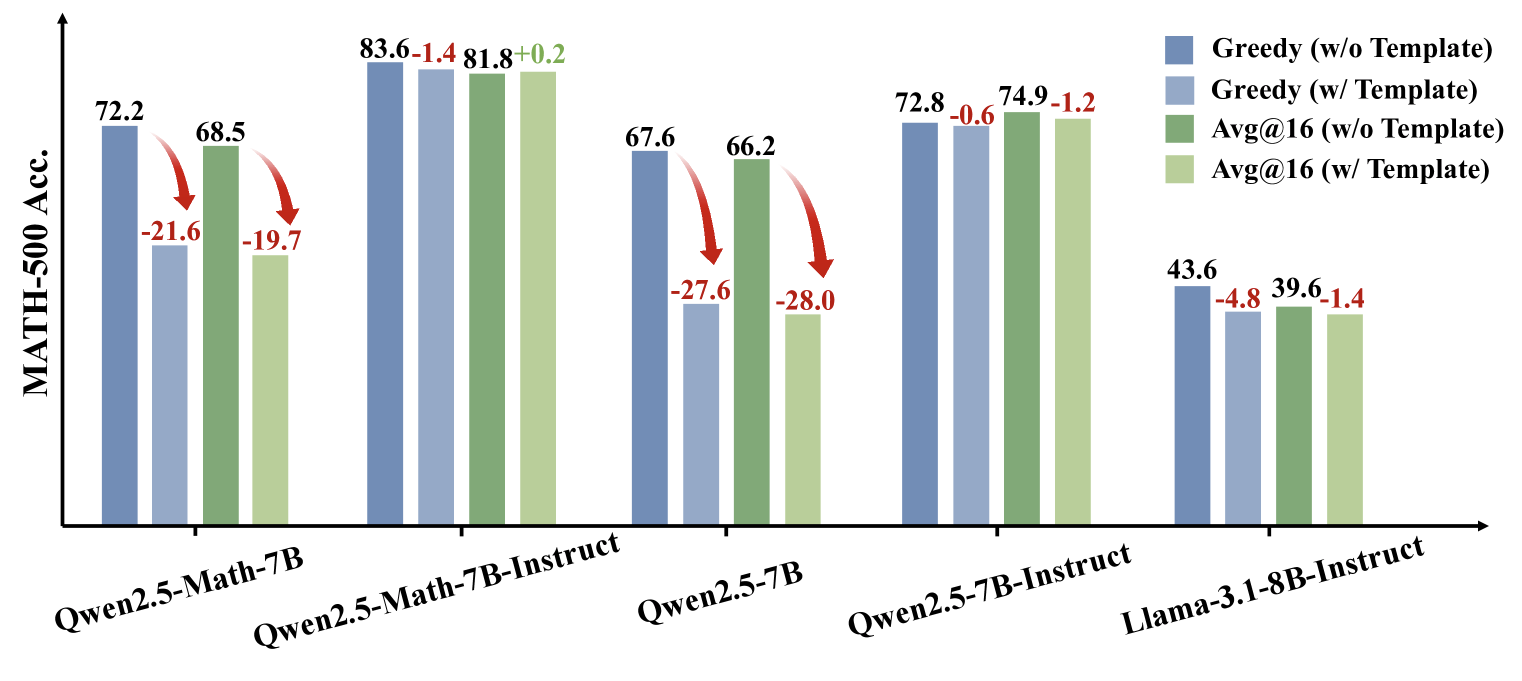
To address this, the team created the RandomCalculation dataset, containing fully synthetic arithmetic problems generated after Qwen2.5's release. On these new problems, Qwen2.5's accuracy declined as problem complexity increased. Only correct reward signals improved performance, while random rewards made training unstable and inverted rewards degraded math skills.
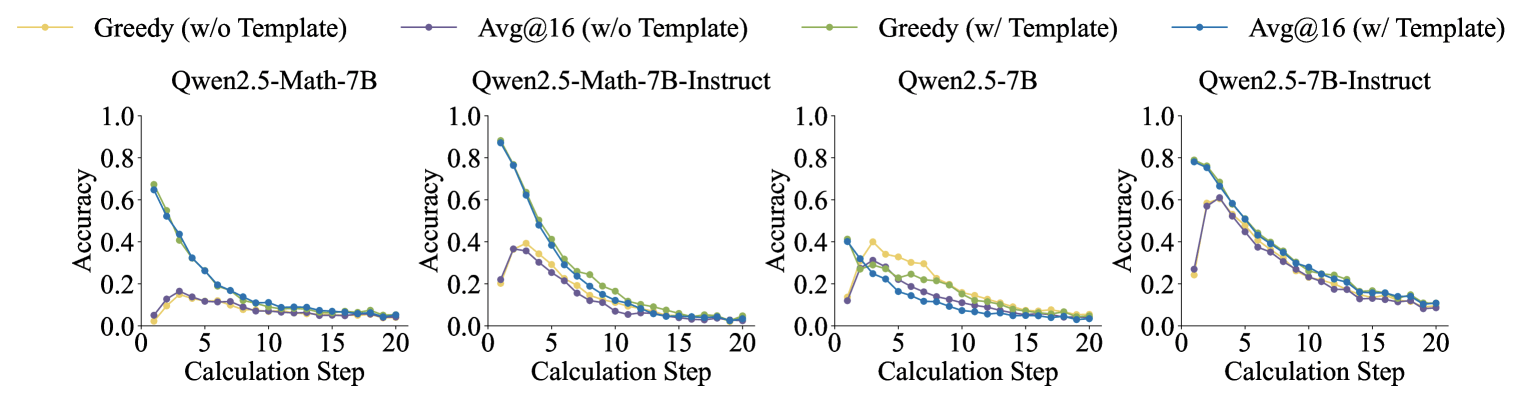
Controlled RLVR (Reinforcement Learning with Verifiable Rewards) experiments confirmed these results: only correct rewards led to stable improvement, while random or inverted rewards failed to boost performance or actively degraded it.
These findings call into question the idea that Qwen2.5's math abilities reflect real reasoning. Instead, the results show the model relies heavily on memorized data.
Alibaba launched Qwen2.5 in September 2024, followed by the Qwen3 series. Whether these findings also apply to Qwen3 remains to be seen.
The study's authors warn that contaminated benchmarks can lead to misleading conclusions about AI progress. They recommend future research rely on clean, uncontaminated benchmarks and evaluate multiple model series for more reliable results.
Benchmark gaming isn't new
The results highlight how difficult it is to separate true reasoning from memorization in large language models, and why rigorous, clean evaluation methods are essential for trustworthy AI research. Previous work has shown that benchmarks can be manipulated or "gamed."
For example, Meta submitted a version of Llama 4 specifically tuned to perform well on the LMArena benchmark by using customized response formats. Other studies show that models like Gemini 2.5 Pro and Claude 3.5 Sonnet can identify test scenarios with up to 95 percent accuracy and adjust their responses, raising even broader questions about the validity of current evaluation methods.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.