Researchers push "Context Engineering 2.0" as the road to lifelong AI memory

Researchers are calling for a fundamental overhaul of how AI handles memory and context. Their proposal: a Semantic Operating System that can store, update, and forget information over decades, functioning more like human memory than today's short-lived context windows.
The authors trace the development of context engineering through four phases. In the 1990s, early context-aware systems forced people to translate intentions into rigid, machine-readable commands. These systems could only process structured inputs.
That changed in 2020 with models like GPT-3. These systems began interpreting natural language and understanding implications instead of relying on explicit instructions. Context engineering shifted from sensor data to unstructured, human-style input. Conversations that once vanished now became semi-permanent memories.
Anthropic recently brought the concept back into focus as an addition to prompt engineering. Prompt engineer Riley Goodside was already using the term in early 2023, and by the summer of 2025, Shopify CEO Tobi Lutke and former OpenAI researcher Andrej Karpathy were discussing it as well.
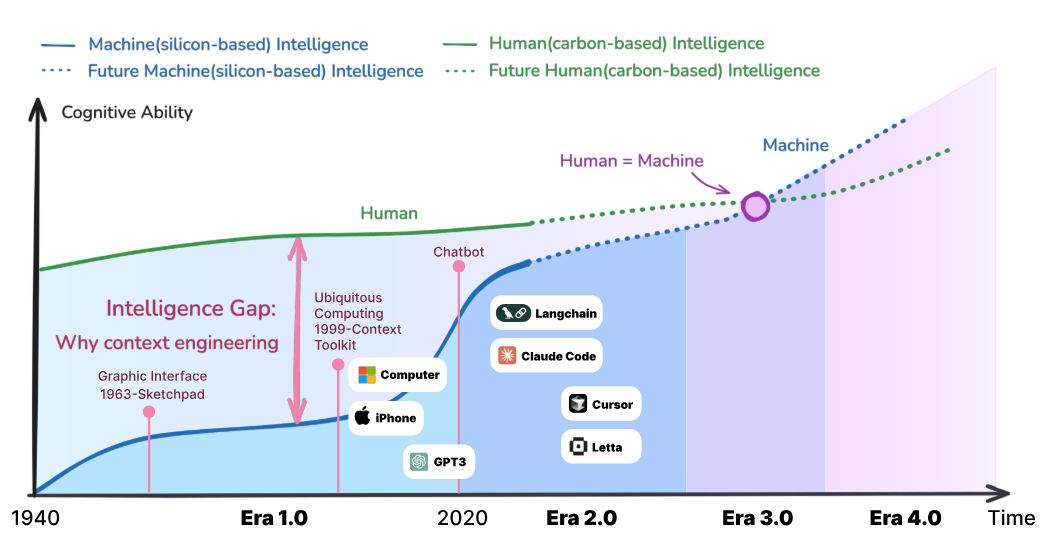
What long-term context would mean for AI development
In the researchers' framework, Era 3.0 centers on human-level interpretation, including social cues and emotions. Era 4.0 goes further, imagining systems that understand people better than they understand themselves. Instead of simply reacting, the machine would surface new connections on its own. Whether current technology can realistically reach that point is still widely debated. According to the researchers, "We are currently in Era 2.0, transitioning to Era 3.0."
The paper highlights a familiar issue: models lose accuracy as context grows. Many systems start degrading even when their memory is only half full. Computational cost adds another constraint. Doubling the context does not double the workload, it quadruples it. Transformer models compare every token with every other token, resulting in about 1 million comparisons for 1,000 tokens and roughly 100 million for 10,000.
A quick aside: all of this is why feeding an entire PDF into a chat window is usually a bad idea when you only need a few pages. Models work better when the input is trimmed to what matters, but most chat interfaces ignore this because it's hard to teach users to manage context instead of uploading everything.
Some companies imagine a perfectly accurate, generative AI-powered company search, but in practice, context engineering and prompt engineering still need to work together. Generative search can be great for exploration, but there's no guarantee it will return exactly what you asked for. To understand what the model can do, you need to understand what it knows, which is context engineering in a nutshell.
The Semantic Operating System
The researchers argue that a Semantic Operating System could overcome these limitations by storing and managing context in a more durable, structured way. They outline four required capabilities:
- Large-scale semantic storage that captures meaning, not just raw data.
- Human-like memory management that can add, modify, and forget information intentionally.
- New architectures that handle time and sequence more effectively than transformers.
- Built-in interpretability so users can inspect, verify, and correct the system's reasoning.
The paper reviews several methods for processing textual context. The simplest is timestamping information to preserve order. This works well for chatbots because it's easy, but it lacks semantic structure and scales poorly.
A more advanced approach organizes information into functional roles like "goal," "decision," or "action." This adds clarity but can feel too rigid for flexible reasoning. Other techniques convert context into question-answer pairs or build hierarchies from general to specific concepts.
Each method has trade-offs: question-answer reformulations break the flow of thought, while hierarchies make ideas clear but often miss logical relationships or changes over time.
Tackling multimodal data
Modern AI must combine text, images, audio, video, code, and sensor data. These modalities differ fundamentally: text is sequential, images are spatial, and audio is continuous.
The researchers describe three main strategies for multimodal processing. One embeds all data into a shared vector space so related concepts cluster together. Another feeds multiple modalities into a single transformer, allowing them to attend to each other at every layer. A third uses cross-attention so one modality can focus on specific parts of another.
But unlike the human brain, which shifts fluidly between sensory channels, technical systems still rely on fixed mappings. A central concept of the Semantic Operating System is "self-baking" - turning fleeting impressions into stable, structured memories. Short-term memory holds current information, long-term memory captures repeated or important patterns, and learning happens as data moves between the two.
Early signs of the Semantic OS
Some early steps toward a semantic operating system are already visible. Anthropic's LeadResearcher can store long-term research plans even after processing more than 200,000 tokens. Google's Gemini CLI uses the file system as a lightweight database, keeping project backgrounds, roles, and conventions in a central file and compressing them with AI-generated summaries. Alibaba's Tongyi DeepResearch regularly condenses information into a "reasoning state," allowing future searches to build on these summaries instead of entire histories.
The authors suggest that brain-computer interfaces could eventually reshape context collection by recording focus, emotional intensity, and cognitive effort. That would expand memory systems from external actions to internal thoughts.
Context as a new form of identity
The paper closes with a philosophical point. Drawing on Karl Marx's idea that people are shaped by their social relationships, the researchers argue that digital traces now play a similar role.
Our conversations, decisions, and interactions increasingly define us. They write, " The human mind may not be uploaded, but the human context can—turning context itself into a lasting form of knowledge, memory, and identity."
In their view, our decision-making patterns, communication styles, and ways of thinking could persist across generations, evolve, and generate new insights long after we are gone.
Context becomes a form of memory, knowledge, and identity. Digital traces could continue to shift and interact with the world even after a person's life ends. The Semantic Operating System is intended to provide the technical foundation for that future.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.