Zhipu AI's GLM-Image uses "semantic tokens" to teach AI the difference between a face and a font

Chinese AI company Zhipu AI combines an autoregressive language model with a diffusion decoder. The 16-billion-parameter model excels at rendering text in images and knowledge-heavy content.
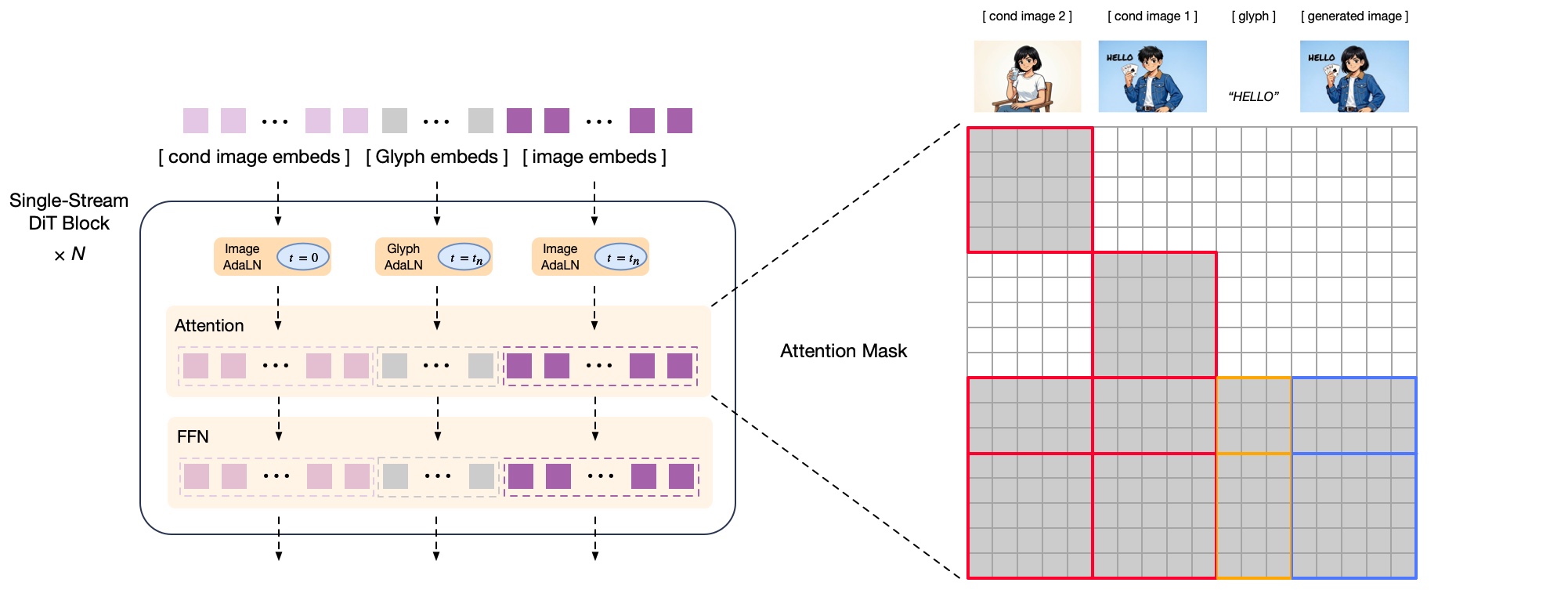
The architecture splits image generation into two specialized modules. A 9-billion-parameter autoregressive module based on the GLM-4 language model first creates a semantic representation of the image. It works like word prediction in language models: token by token, it builds a structure that determines the image's content and layout. A 7-billion-parameter diffusion decoder then refines this into a high-resolution image between 1024 and 2048 pixels.

Semantic tokens help the model learn faster
What sets GLM-Image apart from its competitors is how it breaks down images. Rather than relying on classic VQVAE tokens (Vector Quantized Variational Autoencoder), which prioritize visual reconstruction, the model uses what Zhipu AI calls semantic tokens. These carry both color information and meaning, identifying whether an area represents text, a face, or background. Zhipu AI says this approach speeds up training and produces more reliable outputs.
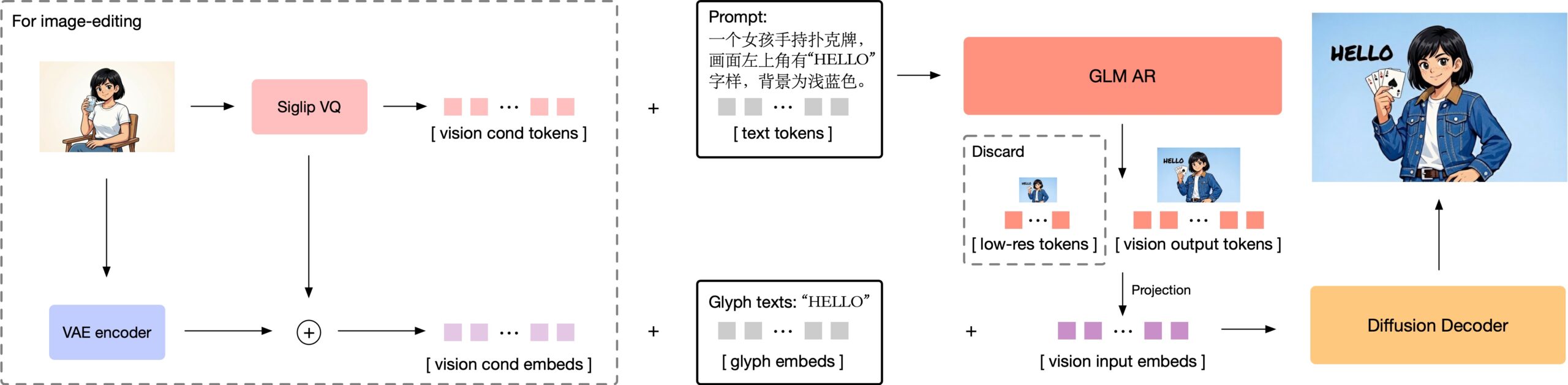
For higher resolutions, GLM-Image first generates a compact preview with around 256 tokens before creating the full 1024 to 4096 tokens for the final image. This preview locks in the basic layout. Zhipu AI says generating high-resolution images directly causes the model to lose controllability.
For text rendering, GLM-Image integrates a Glyph-byT5 module that processes text areas character by character. Zhipu AI says this significantly improves how text looks, especially for Chinese characters. Since the semantic tokens already carry enough meaning, the decoder doesn't need a separate large text encoder - cutting memory requirements and compute.
Split training improves content and visuals independently
After pre-training, Zhipu AI fine-tunes both modules separately using reinforcement learning. The autoregressive module gets feedback on aesthetics and content accuracy, whether the image matches the prompt, and whether text is readable.
The diffusion decoder trains for visual quality: Are textures right? Are hands rendered correctly? Zhipu AI built a specialized evaluation model for the latter. Splitting these two aspects lets the team tweak each one without messing up the other.

For image editing and style transfer, GLM-Image processes both the semantic tokens and the image data from the original. The model takes a more efficient approach than Qwen-Image-Edit: instead of fully cross-referencing the reference and target images, GLM-Image caches intermediate results from reference images and reuses them. Zhipu AI says this saves compute without noticeably hurting detail preservation.
Running the model isn't easy: Zhipu AI says it requires either a GPU with more than 80 gigabytes of memory or a multi-GPU setup. Consumer hardware won't cut it. GLM-Image is available under an MIT license on Hugging Face and GitHub.
Chinese hardware-only training signals growing chip independence
Zhipu AI claims GLM-Image is the first open image model trained entirely on Chinese hardware. The company likely used Huawei's Ascend Atlas 800T A2 chips instead of Nvidia's H100 accelerators.
The timing matters. US export restrictions on AI chips have pushed China to limit purchases of even permitted Nvidia hardware to boost domestic chip production. Zhipu AI sees GLM-Image as proof that powerful multimodal models can be built without Western silicon - a political statement as much as a technical one.
The company, which openly names OpenAI as a competitor, recently became one of the first Chinese AI companies to go public. Its stock has since jumped more than 80 percent.
The release adds to Zhipu AI's growing lineup of open-weight models. In December, the company shipped GLM-4.7, a model built for autonomous programming that hit 73.8 percent on the SWE-bench Verified benchmark, matching commercial offerings from OpenAI and Anthropic.
GLM-Image's focus on text rendering reflects a broader push among Chinese image models. In August, Alibaba released Qwen-Image, a 20-billion-parameter model built for more natural-looking results and text precise enough for PowerPoint slides. Meituan followed in December with LongCat-Image, a 6-billion-parameter model that aims to beat larger competitors on text rendering.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.