Snap's SnapGen++ generates high-resolution AI images on iPhone in under two seconds

Key Points
- Snap Inc. has developed SnapGen++, a compact diffusion transformer that generates high-resolution images directly on smartphones in under two seconds.
- The model is the first to use an architecture that was previously reserved for large server models, now running efficiently on mobile devices.
- Despite its small size, SnapGen++ outperforms significantly larger competitors like Flux.1-dev and Stable Diffusion 3.5 in image quality tests, even though those models have up to 30 times more parameters.
Snapchat's parent company introduces a compact diffusion transformer that brings server-quality text-to-image generation to mobile devices. The 0.4 billion parameter model beats competitors 30 times its size.
Snap Inc. has built an efficient diffusion transformer that generates high-resolution images directly on smartphones. According to the research paper, SnapGen++ creates 1024 x 1024 pixel images in just 1.8 seconds on an iPhone 16 Pro Max.
Previous on-device models like SnapGen used U-Net architectures, but SnapGen++ is the first to bring the more powerful diffusion transformer architecture to smartphones. This same architecture powers large server models like Flux and Stable Diffusion 3, but until now its massive computational demands made it impractical for mobile devices.

Diffusion transformers represent a major leap in image generation. They combine the transformer architecture's strengths, especially its ability to understand complex text prompts and scale efficiently, with the proven diffusion approach. The result is more coherent and detailed images than U-Net-based predecessors could produce.
New attention method slashes computational demands
The core challenge with diffusion transformers is their massive computational requirements, which grow quadratically as image resolution increases. The team solved this with a new attention method that dramatically cuts the processing load.
Rather than processing all image regions at once, the model combines a rough overview with fine local details. This approach drops latency per inference step from 2,000 milliseconds to under 300 milliseconds without sacrificing generation quality.
The team also developed what they call Elastic Training. A single training run produces three model variants: a Tiny version with 0.3 billion parameters for budget Android devices, a Small version with 0.4 billion for high-end smartphones, and a Full version with 1.6 billion parameters for servers or quantized on-device use.

All three variants share parameters and train together. The authors say this lets them adapt to different hardware without training separate models.
Small model beats competitors 30 times its size
SnapGen++ delivers strong benchmark results. The small version with just 0.4 billion parameters consistently outperforms Flux.1-dev, which has 12 billion parameters, making it 30 times larger, in both image quality and text-image alignment tests. SD3.5-Large with 8.1 billion parameters also falls short of Snap's largest model.
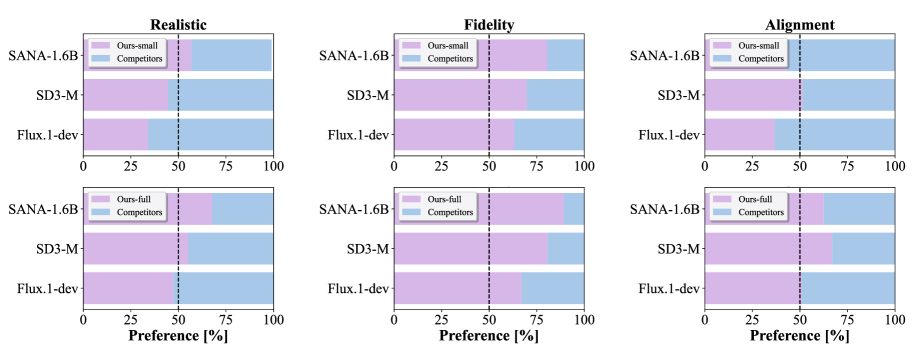
The team built a specialized distillation method for efficient on-device generation. It cuts the required inference steps from 28 to just four while preserving nearly the same quality. Total latency on the iPhone 16 Pro Max for the small version comes in at around 1.8 seconds with four inference steps.
The race for mobile AI image generation
Snap previously released SnapGen, a U-Net-based approach that enabled 1024-pixel images on smartphones but couldn't match the quality of large server models. Other companies like Google are also working on efficient diffusion models for mobile devices. But according to the research paper, SnapGen++ is the first to ship an efficient diffusion transformer for high-resolution on-device generation.
Snap has been steadily investing in AI features for its messaging app. Beyond its in-house chatbot "My AI," the company announced a $400 million partnership with Perplexity AI in November 2024. The AI search engine will be integrated into Snapchat by default this year.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now