OpenAI's GPT-5.2 Pro solves math problems that stumped every AI model before it
OpenAI has a new math champion. GPT-5.2 Pro just set a record on the notoriously difficult FrontierMath benchmark, according to testing by Epoch AI. The model hit 31 percent on the hardest tier (Tier 4) - a major leap from Gemini 3 Pro's previous best of 19 percent. Epoch AI ran the tests manually through the ChatGPT website because of API issues.
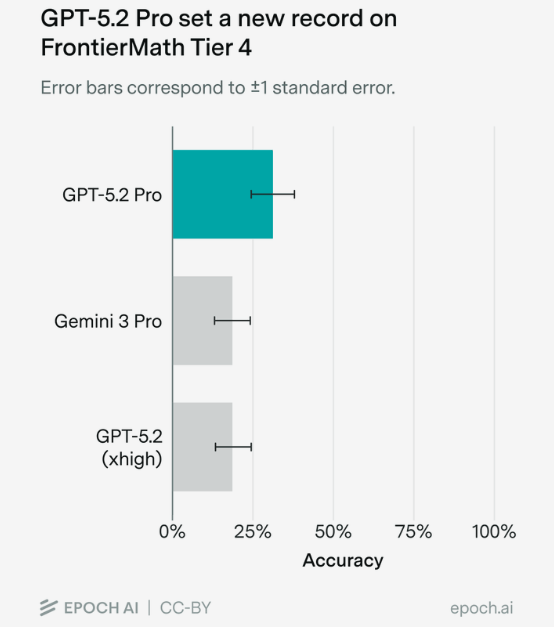
GPT-5.2 Pro cracked 15 of 48 tasks, including four problems no model had solved before. Several mathematicians gave the solutions mostly positive reviews, though some criticized the lack of precision in certain explanations.
The benchmark results line up with recent reports about AI models—particularly GPT-5-Thinking and -Pro—proving genuinely useful for tackling mathematical problems. GPT-5 has reportedly solved Erdős problems on its own and helped researchers work through others. Still, renowned mathematician Terence Tao cautions against drawing premature conclusions.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now