OpenAI develops six-layer context system to help employees navigate 600 petabytes of data

Key Points
- OpenAI has built an internal AI data agent that makes over 70,000 datasets and 600 petabytes of data searchable using natural language.
- A method called "Codex Enrichment" gives the agent access to the code that generates tables, letting it spot distinctions that metadata alone can't reveal.
- The agent uses six layers of context and can cut analysis time from days to minutes - one test query dropped from 22 minutes to under 90 seconds.
OpenAI has developed an internal AI data agent that lets employees run complex data analyses using natural language. A key technique called "Codex Enrichment" crawls the codebase to understand what tables actually contain.
Finding the right table across 70,000 datasets and 600 petabytes of data is no small task. Many tables look similar on the surface, and figuring out the differences eats up significant time.
In a technical report, engineers Bonnie Xu, Aravind Suresh, and Emma Tang explain how they taught the agent to develop a deeper understanding of data. The key lies in the code that generates the tables.
Metadata and SQL queries describe what a table looks like and how it's used - but they don't reveal what's actually inside. OpenAI solves this with a method the team calls "Codex Enrichment." The agent crawls the codebase using Codex and derives a deeper definition of each table from the code itself. Pipeline logic captures assumptions, freshness guarantees, and business intent that never show up in SQL or metadata.
Similar schemas can hide critical differences
The problem OpenAI is trying to solve is common when dealing with large amounts of data. Many tables look similar on the surface but differ in critical ways. One table might only include logged-in users, while another includes logged-out users too. One captures only first-party ChatGPT traffic, another captures everything.
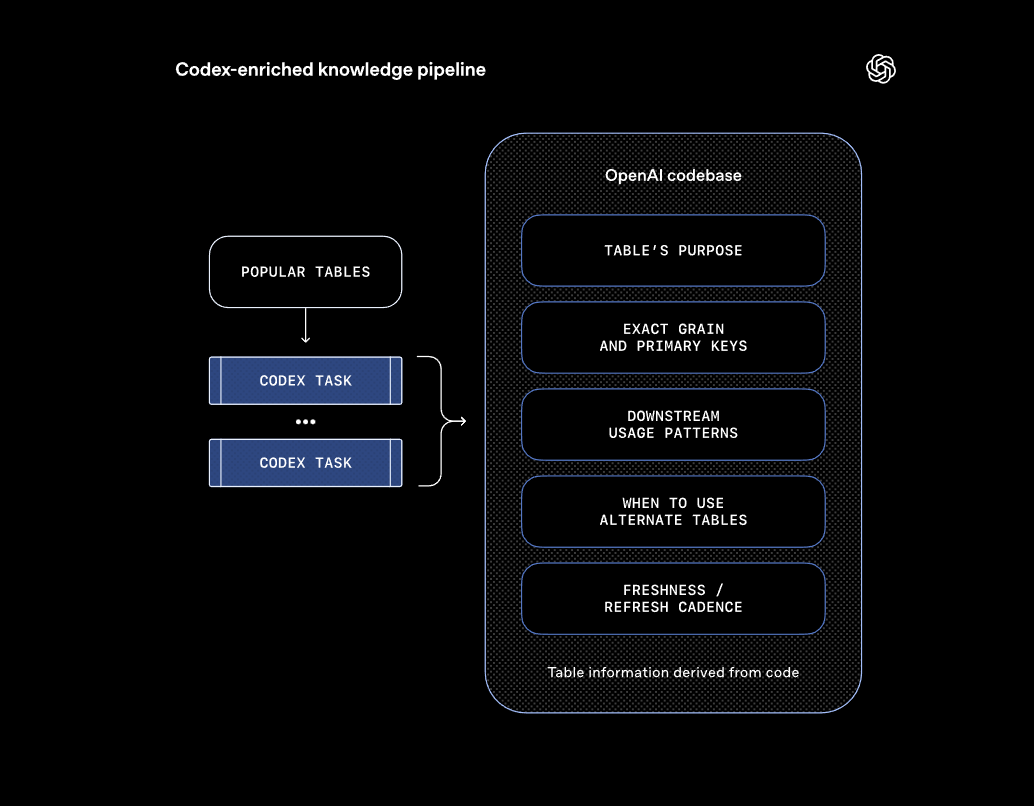
Through code-level analysis, the agent can spot these differences. It understands not just what columns a table has, but how the data was filtered, transformed, and aggregated. This lets it answer questions about table contents and appropriate use cases far more accurately than database signals alone.
When the code that generates a table changes, Codex Enrichment adapts without any manual maintenance.
Six layers of context power the system
Codex Enrichment is one of six context layers that OpenAI's data agent uses. The first layer includes schema metadata like column names and data types, along with historical queries that show which tables are typically used together. The second layer consists of curated descriptions from domain experts that capture semantics, business meaning, and known limitations. The third layer is Codex Enrichment.
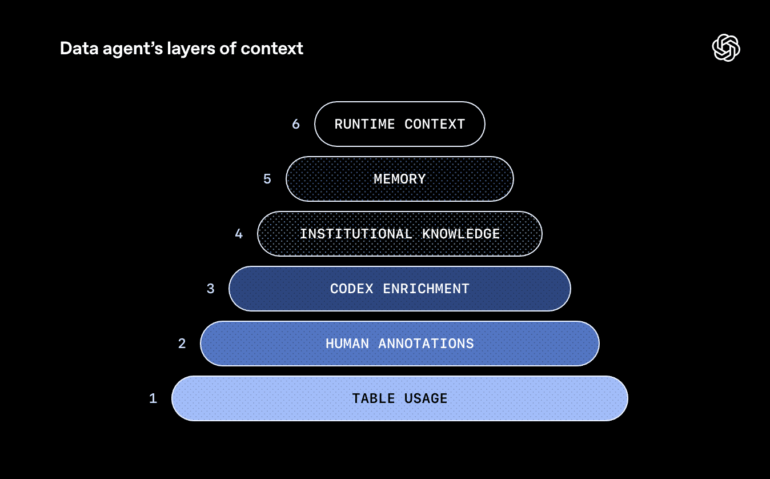
The fourth layer taps into institutional knowledge. The agent searches Slack messages, Google Docs, and Notion documents for information about product launches, technical incidents, and canonical metric definitions. The fifth layer is a learning memory that stores corrections and nuances from previous conversations and applies them to future requests. The sixth layer enables live queries to the data warehouse when no prior information exists or existing data is outdated.
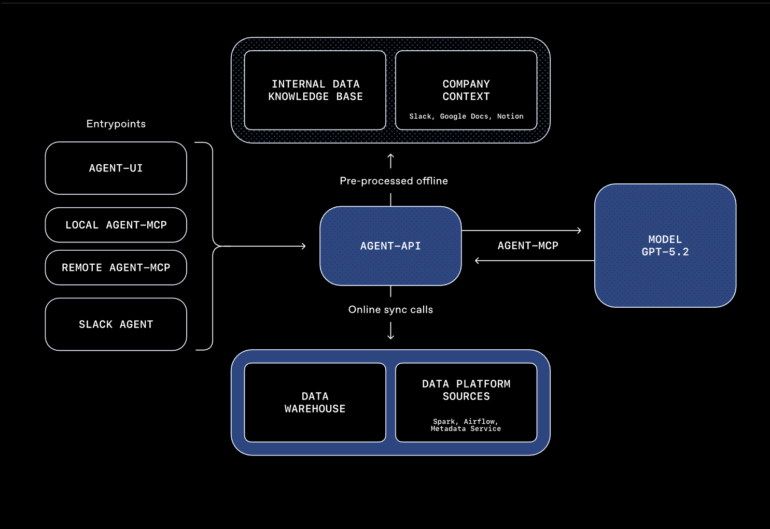
OpenAI tested the system on a simple question about daily active users of ChatGPT Image Gen. Without memory, the agent took over 22 minutes. With memory enabled, that dropped to one minute and 22 seconds. The company says the combination of all six context layers can cut analysis time for some queries from days to minutes.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now