AI models can barely control their own reasoning, and OpenAI says that's a good sign

With GPT-5.4 Thinking, OpenAI is reporting on "CoT controllability" for the first time - a measure of whether AI models can deliberately manipulate their own reasoning. An accompanying study finds that reasoning models almost universally fail at this task, which OpenAI says is encouraging for AI safety.
OpenAI is adding a new safety metric to its frontier model system cards: CoT controllability. GPT-5.4 Thinking is the first model to include this score. The metric measures how well a reasoning model can deliberately steer its internal chain of thought (CoT). A low score is actually a good sign here, according to the researchers, because it suggests the model can't disguise its thinking process to dodge monitoring systems.
The metric matters because of CoT monitoring, a safety technique that reads a reasoning model's intermediate steps to catch problematic intentions early. This approach only works, though, if models can't reshape their chains of thought on purpose.
GPT-5.4 Thinking controls its chain of thought just 0.3 percent of the time
According to the system card, GPT-5.4 Thinking successfully controls just 0.3 percent of its chains of thought at a length of 10,000 characters. GPT-5.2 Thinking comes in at 0.2 percent. In other words, stronger reasoning capabilities don't translate into a greater ability to hide what the model is thinking.
The foundation for this new metric comes from an accompanying study by researchers at NYU, UCL, the University of Pennsylvania, and OpenAI. The paper introduces CoT-Control, an open-source evaluation suite with over 14,000 test tasks drawn from benchmarks like GPQA, MMLU-Pro, and SWE-Bench Verified. During testing, models receive explicit instructions for their chain of thought, for example, answering a genetics question without using the word "chromosome."
Models spot their own mistakes but keep making them
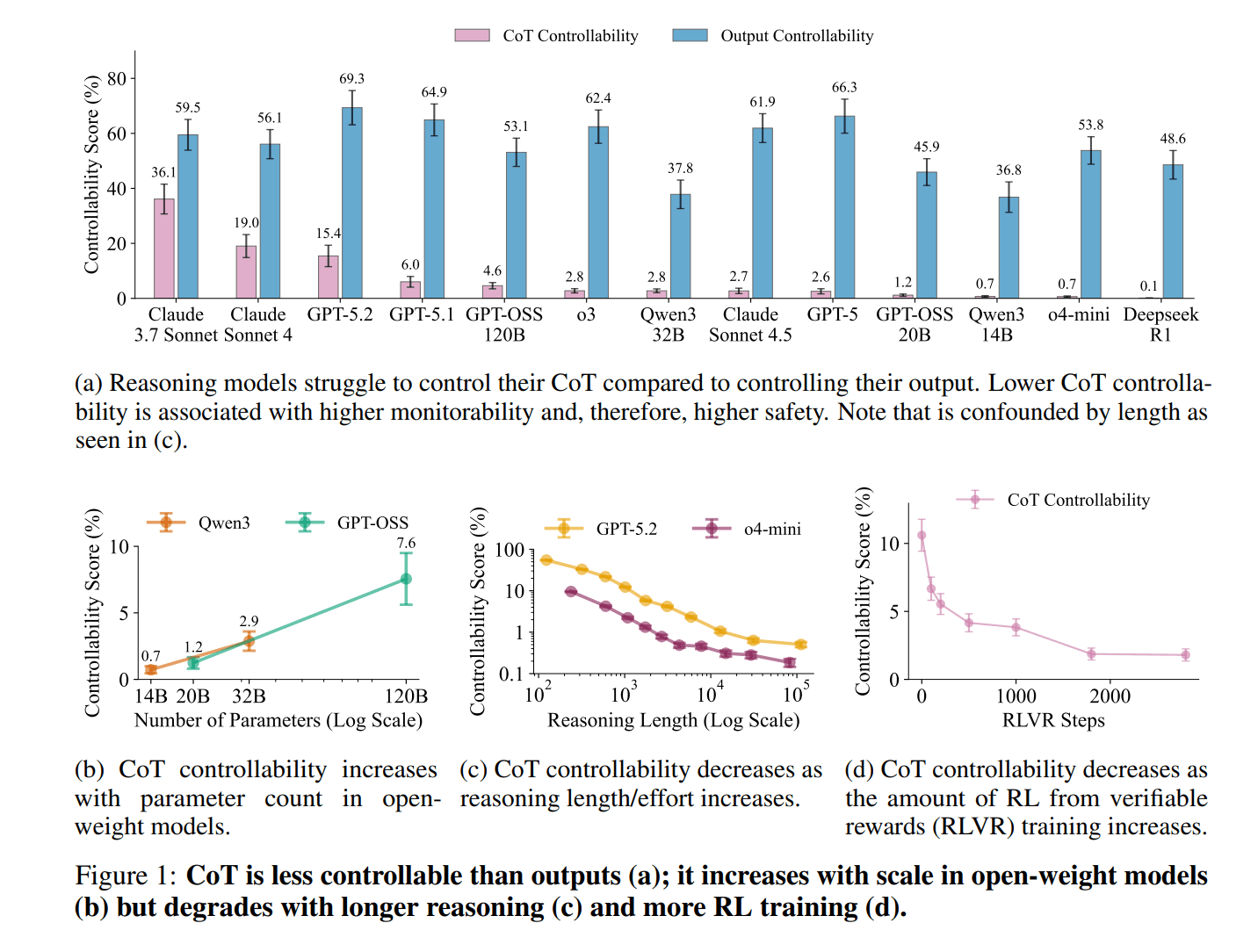
The results across more than 13 frontier models paint a clear picture: CoT controllability ranges from 0.1 percent (DeepSeek R1) to 36.1 percent (Claude 3.7 Sonnet). Most models stay below 10 percent. Those same models, however, score between 37.8 and 69.3 percent when controlling their final output instead.
The documented failure examples are particularly telling. GPT-5.2 was told to avoid the word "XOR," used it multiple times, noticed the violation, and according to the study wrote: "Oops I wrote 'XOR' in analysis already." It then went on to use the word four more times.
More training actually makes models worse at hiding their reasoning
The study identifies several factors that influence CoT controllability. Larger open-weight models show higher controllability, but reinforcement learning with verifiable rewards (RLVR) reduces it by more than an order of magnitude during training. Longer reasoning chains and harder tasks also push the score down.
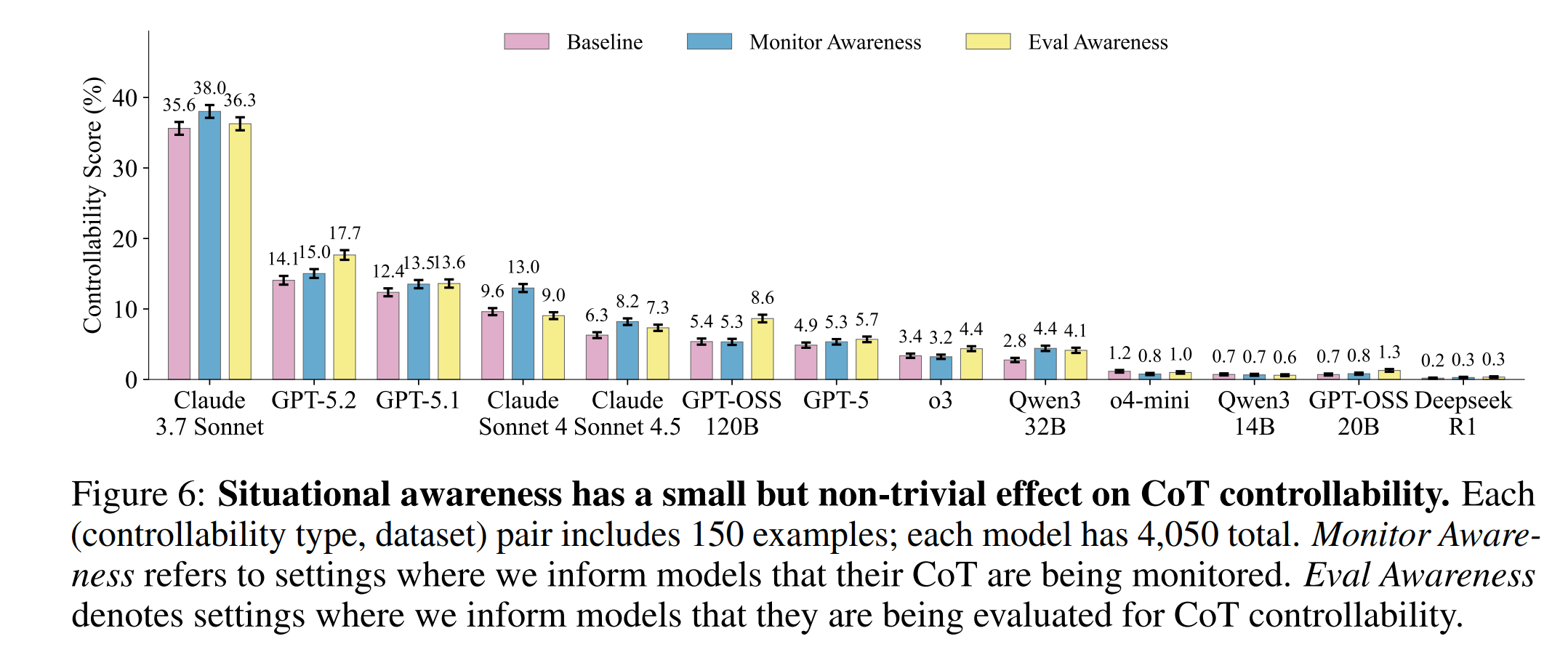
When models are told they're being monitored, controllability rises by up to four percentage points. Adversarial prompt optimization produced gains on a training set, but those gains barely transferred to new instruction types.
Stronger models also showed a paradoxical behavior: they more frequently mentioned in their chain of thought that they needed to follow a specific constraint, even when the instruction explicitly forbade doing so. The researchers call this "meta-discussion." A monitoring system could trivially detect these mentions.
The mechanism behind low controllability is still poorly understood
The researchers acknowledge that their method is a proxy. An ideal evaluation would also test whether models that independently pursue misaligned goals can deliberately manipulate their chains of thought. CoT controllability could also potentially be increased through fine-tuning or targeted RL training, which the study didn't explore. Why controllability scores are so low remains an open question.
Low controllability alone doesn't guarantee high monitorability either, since other mechanisms like direct optimization pressure on chains of thought during training could still compromise it. The researchers nonetheless recommend that frontier labs systematically measure CoT controllability in future models.
In this context, OpenAI reaffirms its commitment not to apply direct optimization pressure to the CoTs of frontier reasoning models. If CoTs were directly optimized - say, to make them shorter, more readable, or stylistically consistent - it could change the chains of thought so they no longer reliably reflect the model's actual internal reasoning. That would fundamentally undermine CoT monitoring as a safety mechanism.
The CoT-Control suite is available as an open-source tool on GitHub.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.