Bytedance's open-weight Helios model brings minute-long AI video generation close to real time

Helios is the first 14B video model to hit 19.5 FPS on a single GPU while producing minute-long videos. The code and model weights are publicly available.
Most video generation models today only produce 5-to-10-second clips and can take minutes to render them. Real-time approaches for longer videos rely on much smaller 1.3B models that struggle with quality. Larger models like Krea-RealTime-14B top out at 6.7 FPS on an H100 and suffer from severe drifting artifacts.
Helios builds on Wan-2.1-14B, which takes around 50 minutes to generate five seconds of video on an A100. Training happens in three stages: Helios-Base (architecture and anti-drifting), Helios-Mid (token compression, 1.05 FPS), and Helios-Distilled, which maxes out speed by cutting computation down to just three steps.
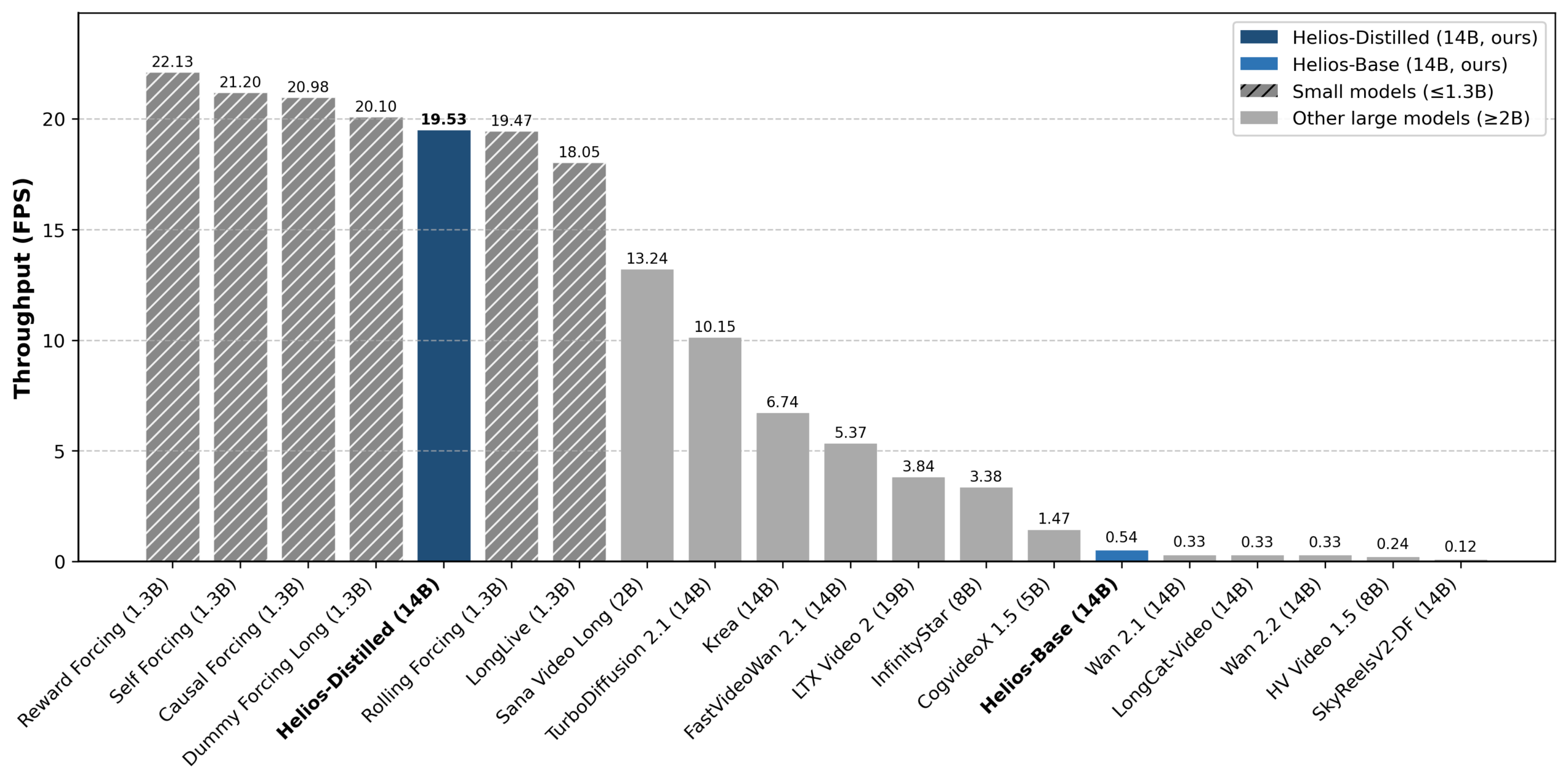
In developer benchmarks, the distilled version of Helios hits 19.53 FPS—even faster than some much smaller distilled models. SANA Video Long, which has 2 billion parameters and is roughly seven times smaller, only manages 13.24 FPS.
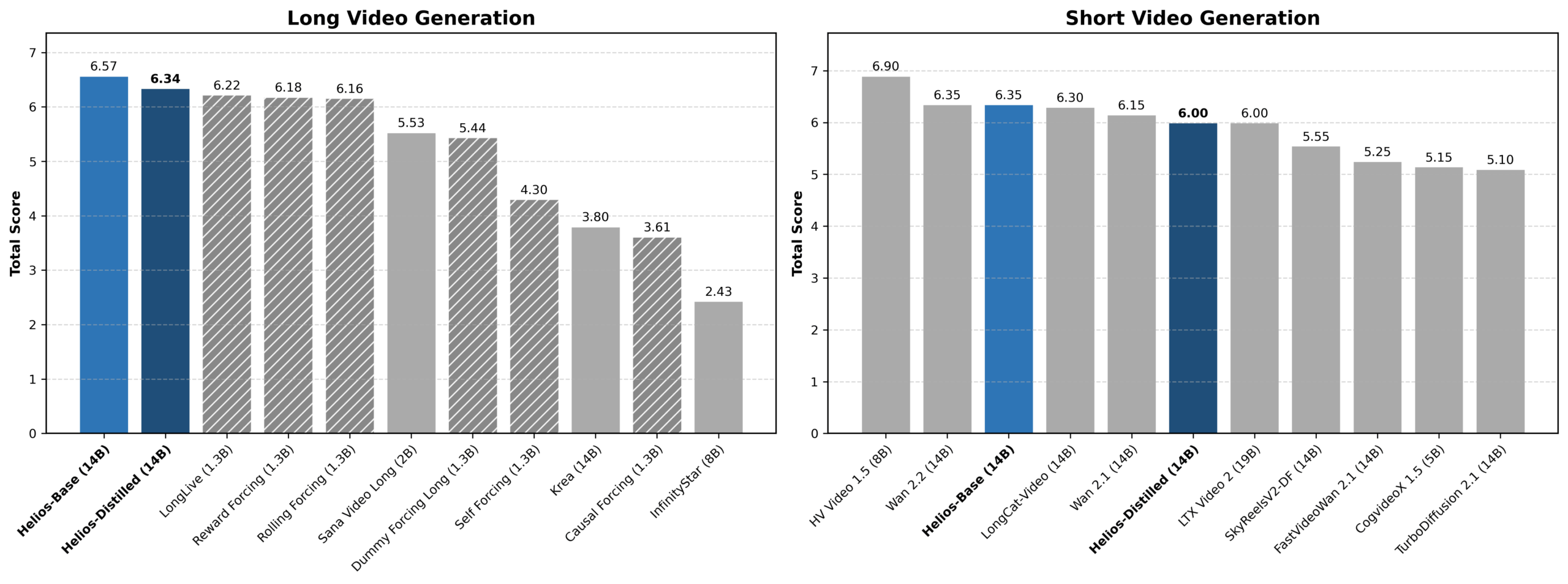
On video quality, Helios scores 6.00 overall for short videos with 81 frames. The authors say that it beats every distilled model and is on par with most base models at this size. For long videos, Helios scored 6.94, edging out the previous leader, Reward Forcing, at 6.88. A user study with 200 participants backs up the results.
Longer generated videos typically lose quality, color consistency, and content coherence over time. Previous models tackle this with complex techniques like self-forcing, where the model feeds its own output back as input during training to close the gap between training and inference. Helios skips all of that.

Instead, the authors pinpoint three typical drifting patterns and propose simpler fixes. Relative position coding keeps the model from hitting unknown position indices in long videos, which would otherwise cause repetitive movements. A first-frame anchor holds the opening frame in memory at all times, giving the model a visual reference point to prevent color shifts. A targeted perturbation simulation during training makes the model more resilient to its own errors, which would otherwise snowball over time.
One model handles text, image, and video input
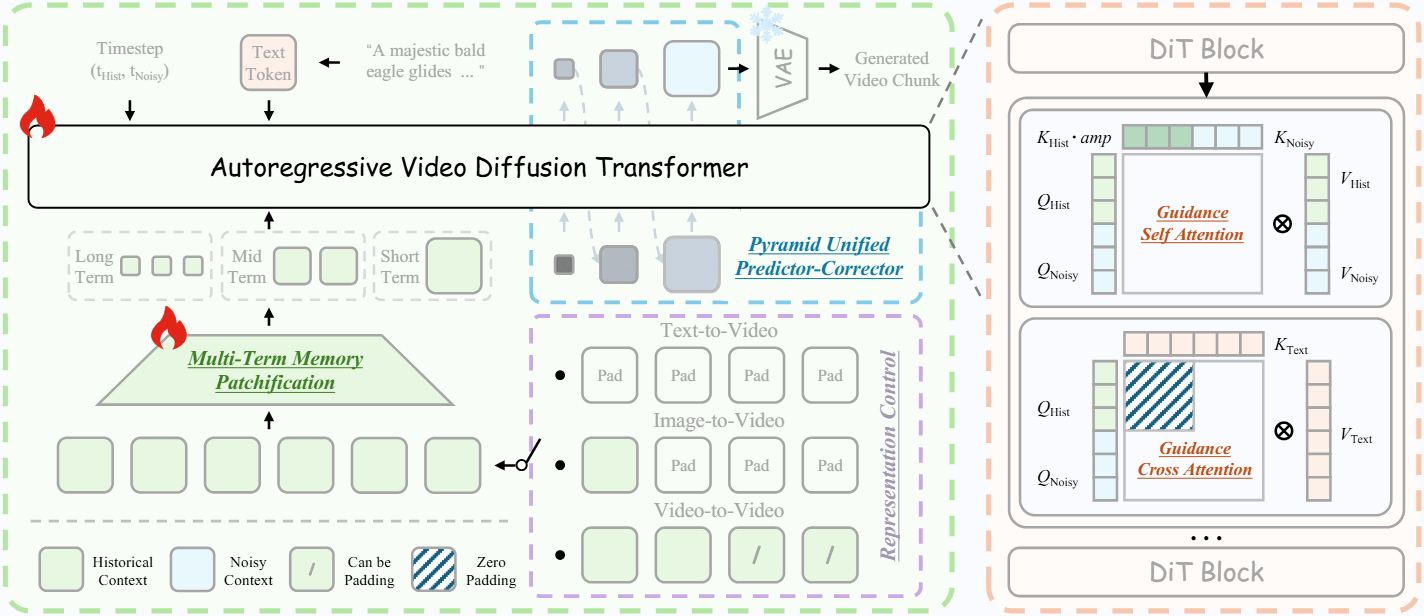
Helios uses a unified architecture that supports text-to-video, image-to-video, and video-to-video in a single framework. The model switches between tasks automatically based on what's in the previous context.
If the context is empty, the model generates from text. If only the last frame is present, it works as an image animator. If multiple frames are available, it continues an existing video. Users can also swap the text prompt mid-generation; a gradual crossfade between the old and new prompt helps prevent jarring visual breaks.
The model was trained in three stages on 800,000 short video clips, each under ten seconds long. Resolution tops out at 384 x 640 pixels for now, and flicker artifacts still show up at segment transitions. Since no open benchmark exists for real-time long videos, the researchers built their own test dataset called HeliosBench with 240 prompts.
Aggressive compression slashes compute costs
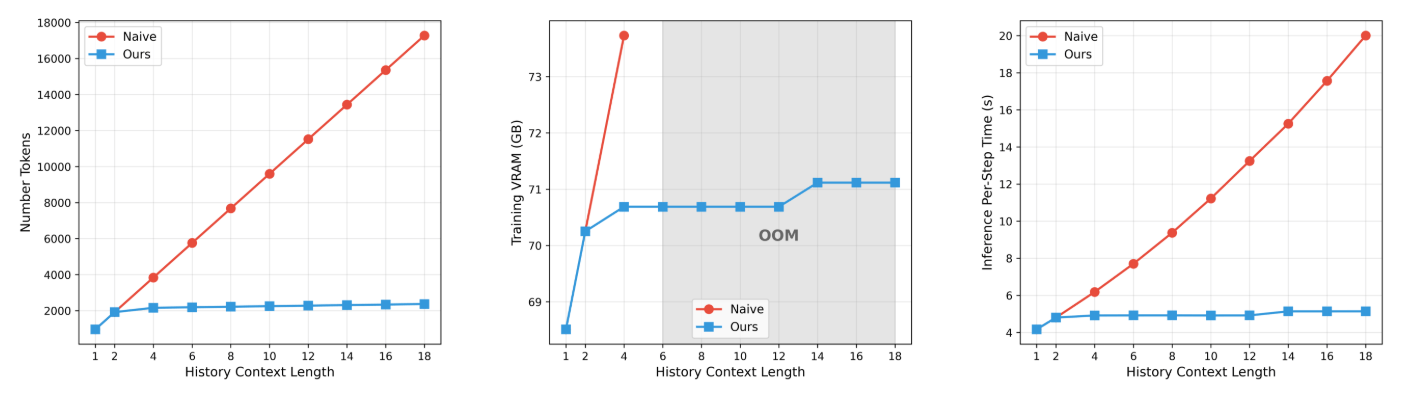
Helios hits its speed targets without common acceleration tricks like KV cache, sparse attention, or quantization. Instead, the model aggressively compresses input data at two levels.
A hierarchical memory structure splits the video history into three time scales. Recent frames get lighter compression, while older frames get compressed more heavily. This cuts the number of tokens to process by a factor of eight.
A multi-stage sampling process reduces tokens for the video segment being generated by a factor of 2.29. Early steps run at lower resolution, and only later steps fill in fine details. Together, these two techniques bring compute costs down to roughly the same level as generating a single image.
A dedicated distillation technique also cuts the number of required computation steps per video segment from 50 to 3. Unlike previous approaches, Helios uses only real video data as context and generates just one segment per training step. An adversarial training objective similar to a GAN pushes quality beyond the limits of the teacher model.
Token compression lets Helios train through its first two stages on a single GPU. The third stage requires four complete models running simultaneously, but they fit into 80 GB of GPU memory thanks to various memory optimizations. Custom compute kernels for common operations speed up both training and inference by about 14 percent over the standard implementation, according to the researchers.
Helios is available as an open-weight model on GitHub and Hugging Face, which also hosts a live demo. Generated video examples are available on the project page. The project is strictly for research and isn't planned for integration into any Bytedance products.
Bytedance recently made waves with Seedance 2.0, a multimodal video generation model that processes images, videos, audio, and text all at once. Seedance needs significantly more compute and caps out at 15-second clips, but delivers much higher visual quality—so high that it raised alarms in Hollywood over its potential for massive copyright infringement.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.