Google PaLM-E combines language, vision and robotics

With PaLM-E, Google Robotics, TU Berlin, and Google Research present a new AI model that can understand and generate language, understand images, and use both together for complex robot commands.
PaLM-E's largest model has 562 billion parameters and combines Google's massive PaLM language model with ViT-22B, the largest vision transformer to date.
The main architectural idea of PaLM-E is to inject continuous, embodied observations such as images, state estimates, or other sensor modalities into the language embedding space of a pre-trained language model.
From the paper
Video: Google
The largest PaLM-E model is capable of processing PaLM-level natural language while also understanding and describing image content and guiding robots through precise, sequential steps by combining language and computer vision.
PaLM-E can guide robots through the real world by understanding language and images. | Video: Google
With PaLM-SayCan, Google previously demonstrated that language models can help guide robots. PaLM-E's combined training approach across domains is said to lead to "significantly higher performance" compared to models optimized for robotics alone.
Perhaps most exciting about PaLM-E is **positive transfer**: simultaneously training PaLM-E across several domains, including internet-scale general vision-language tasks, leads to significantly higher performance compared to single-task robot models. pic.twitter.com/sUqrX6U7BU
- Danny Driess (@DannyDriess) March 7, 2023
Importantly, we have demonstrated that this diverse training leads to several avenues of transfer from the vision-language domains into embodied decision making, enabling robot planning tasks to be achieved data efficiently.
From the paper
PaLM-E handles a variety of robotics and visual tasks
Google shows another demo in which PaLM-E controls a robotic arm that arranges blocks. The twist here is that the robot processes visual and language inputs in parallel and uses them to solve the task. For example, it can move blocks sorted by color into different corners. PaLM-E generates the solution instructions step by step from the visual input.
Video: Google
According to the research team, the model also demonstrates the ability to generalize. In the following video, it guides the robot arm to move the red blocks toward the coffee cup precisely and as instructed. There were only three examples of coffee cups in the training data, none of which had red blocks in the image, according to the team.
Video: Google
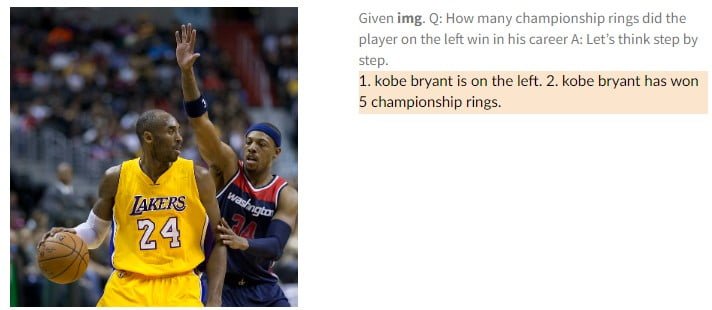
PaLM-E is also a "competent vision-language model," the researchers write. For example, it recognizes basketball star Kobe Bryant in an image and can generate textual information about him, such as how many championships he has won. In another example, PaLM-E sees a traffic sign and explains what rules are associated with it.

PaLM-E's language capabilities lose significant performance due to multimodal and robotic training in the smaller PaLM-E models. This phenomenon is known as "catastrophic forgetting" and is usually avoided by freezing language models during training. In contrast, the drop in performance compared to the larger PaLM model is minimal, which the researchers say shows that scaling can help combat catastrophic forgetting.
We observe a notable trend with model scale: the larger the language model, the more it maintains its language capabilities when training on visual-language and robotics tasks - quantitatively, the 562B PaLM-E model nearly retains all of its language capabilities. pic.twitter.com/sWrPOfGxhp
- Danny Driess (@DannyDriess) March 7, 2023
In addition, the largest PaLM-E model, with 562 billion parameters, shows emergent capabilities such as multimodal reasoning chains and the ability to reason across multiple images, even though the model was trained using only single image prompts.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.