Frontier Radar #2: Why AI productivity gets lost between benchmarks and the balance sheet

Generative AI leads to measurable time savings on many tasks. But a gap remains between faster task completion and measurable economic impact. Verification overhead, limited metrics, and organizational inertia often prevent benchmark gains from translating into broader productivity gains.
Six times a year, THE DECODER's editorial team takes an in-depth look at a fundamental AI topic in its "Frontier Radar," as a newsletter and exclusively here on the site for THE DECODER subscribers. This is issue #2, on the measurable impact of AI on productivity. Issue #1 examines the current state of agentic AI.
AI accelerates many tasks. By now, enough studies support this that it is difficult to dispute seriously. The more relevant question is why so little of that speed appears in corporate financials and economic data.
In our view, the debate often takes a wrong turn at a critical point. It treats the path from faster individual task completion to actual value creation as straightforward. In practice, that path is the difficult part. Between the two lie processes, incentives, verification overhead, and the simple fact that many companies do not directly measure productivity in knowledge work at all.
Current research supports two statements at once, without contradiction. At the level of individual tasks, there is compelling evidence of substantial AI-driven gains. At the level of entire companies, and even more so the broader economy, those gains remain muted and difficult to measure.
Task-level evidence is stronger than many assume
The debate over macroeconomic productivity data misses an important point. At the level of individual tasks, the best-known studies provide clear evidence of measurable performance gains.
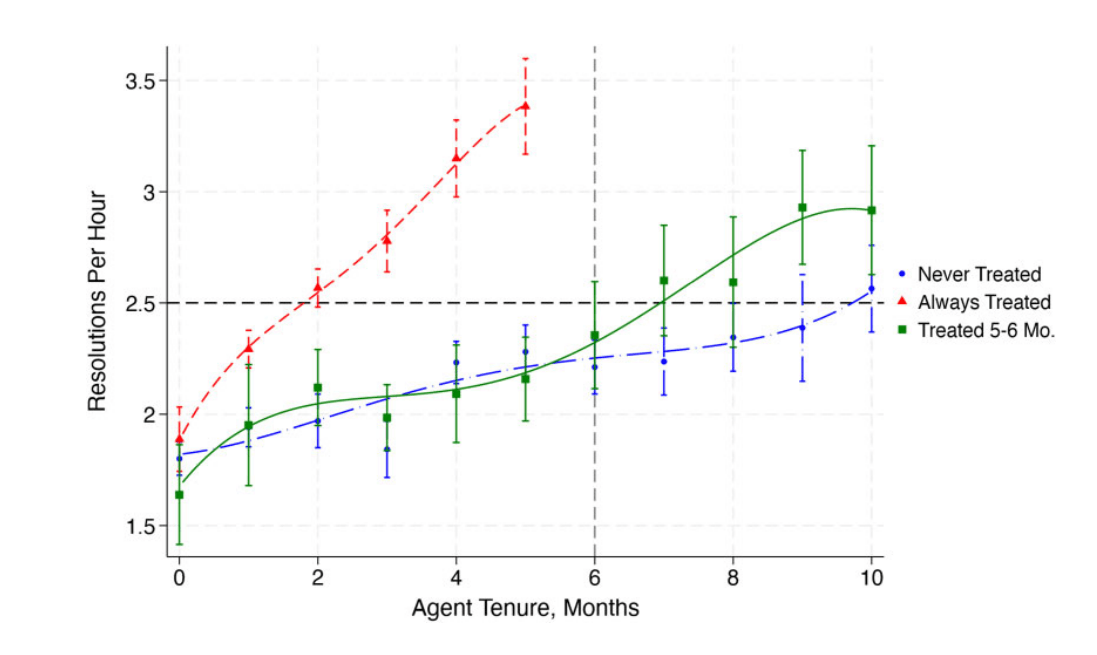
In customer service, a study published in the Quarterly Journal of Economics found that the number of resolved issues per hour rose by roughly 14 to 15 percent after the introduction of a generative AI assistant. Less experienced workers benefited the most. As early as 2023, Noy and Zhang found that ChatGPT significantly reduced completion time and improved quality on average for professional writing tasks.
Results from software development follow the same pattern. An early GitHub Copilot study found a 55.8 percent faster completion rate on a clearly defined coding task. In three field experiments at Microsoft, Accenture, and a Fortune 100 company, the number of completed tasks rose by an average of about 26 percent with AI assistance. In a randomized experiment at Google, developers worked up to 20 percent faster.
Many of these studies are older and used less capable models. Since then, specialized coding tools like Claude Code have emerged, along with substantially stronger models such as Claude Opus 4.6 or GPT-5.4-Thinking. Experienced practitioners like prominent AI researcher and software developer Andrej Karpathy identified a new capability threshold for coding models in late 2025. For many use cases, code is becoming cheaper, more disposable, and easier to modify.
These findings make one assumption difficult to defend: that AI may appear impressive but does not deliver meaningful performance gains.
The methodological strength of these studies also explains their limitation. They measure what can be observed relatively cleanly: time to completion, output per hour, or the quality of a standardized result. The narrower the task, the clearer the finding. But the fact that an assistant closes a customer service case faster does not mean an entire team or company becomes proportionally more productive.
Real-world work is not a benchmark
Work rarely consists of a single task. It is made up of chains of subtasks, follow-up questions, wait times, approvals and system interruptions. An AI model can perform impressively on a narrowly defined task and still have only a limited net effect in day-to-day work because the actual bottleneck lies somewhere else entirely.
The Microsoft/NBER field experiment illustrates this. The researchers studied 66 companies and 7,137 knowledge workers in a randomized setting. During the latter half of the six-month study, active users cut roughly two hours per week from email and showed reduced after-hours work. Yet the authors found no clear indication that this recovered time flowed into other tasks or that overall work patterns changed in a meaningful way. Individual relief was real, but a broader reorganization of work did not occur.
Software development shows the same gap between capability and process. METR reported in 2025 that experienced open-source developers actually became 19 percent slower on average when using AI on familiar tasks.
In February 2026, METR itself revised some of those results. New raw data pointed more toward a speedup because the tools had improved. But even this updated finding comes with caveats. The better AI tools become, the more deeply developers integrate them into their workflows. A meaningful study would require a control group that voluntarily gives up these tools. Developers who benefit the most are unlikely to volunteer for a control group that requires giving up these tools, while those who do remain are more likely to be people who use AI less anyway. That makes the control group unrepresentative and weakens the study's validity.
Newer agent benchmarks also show that point-in-time capability and reliable execution across longer, open-ended work processes remain far apart. APEX-Agents tests long, tool-intensive tasks from investment banking, consulting and law. The best system solves only 24 percent of tasks on the first attempt. FeatureBench measures end-to-end feature implementation in real codebases, where even a strong model completes only 11 percent of tasks successfully. ResearchGym evaluates full research workflows with objective execution metrics. The best-tested agent improves on existing baselines in just 1 out of 15 runs and completes an average of 26.5 percent of subtasks.
Most benchmarks primarily show how well a system performs in a curated test scenario. That also applies to agent benchmarks. Once created, AI companies quickly target and solve them through focused training. How well these results carry over to everyday work remains an open question, since real tasks are less standardized, contexts change continuously and mistakes carry far greater consequences.
Knowledge work has no assembly line
In manufacturing, productivity is relatively easy to observe through unit counts, defect rates or cycle times. In knowledge work, the situation is fundamentally different.
An analyst, a product manager, or a lawyer does not produce standardized units. They make decisions, create alignment, and reduce risk. These are exactly the kinds of contributions that traditional productivity metrics capture poorly.
A widely cited review of knowledge worker productivity measurement underscores the problem: There is no single, universally accepted metric. Different types of work require different combinations of quantity, quality, relevance, and impact.
Many organizations do collect large amounts of data. They track sent emails, meeting minutes, processed tickets, and response times. But these measures primarily capture activity and visibility. According to Deloitte, 60 percent of surveyed executives use such activity indicators as productivity measures. Employees, meanwhile, spend an average of 32 percent of their time on performative work that makes productivity visible without actually increasing it.
If a company has never tracked how cycle times, error rates, or the economic contribution of entire knowledge-work processes change, it cannot reliably measure AI's impact. What remains are anecdotes or, at best, qualitative case studies.
Companies should also recognize that the measurement problem can quickly become an incentive problem. Generative AI often increases visible outputs first. More drafts, more emails answered, more tickets closed, more code suggestions generated. These numbers are easy to count, so they quickly find their way into dashboards, pilot reports, and ROI slides.
As Jan Sauermann describes in labor economics research, this creates a familiar distortion. Once specific observable metrics feed into evaluations or incentives, people optimize for exactly those visible numbers.
For AI, this has a practical implication. Companies often become better at measuring accelerated output, but that does not mean they become better at recognizing its economic value. Precisely because AI produces so many countable results in the short term, the risk of confusing productivity with visibility increases.
More output does not necessarily mean more value
Even companies that manage to measure changes in output encounter the next misconception in the AI debate. Many confuse output with outcome. When a team uses AI to produce twice as many drafts, emails or code suggestions, that is more output. But more output is not the same as more value. That depends entirely on what those additional results actually achieve. More variants only help if they lead to better decisions. More closed tickets only generate profit if quality holds up.
| Level | What gets measured | What's missing |
|---|---|---|
| Task | Time, volume, quality of a single result | Impact on the overall process |
| Process | Cycle time, error rate, rework | Economic value of the result |
| Company | Revenue, margin, customer satisfaction | Causal attribution to AI |
| Economy | GDP per hour worked | Isolating the AI effect from other factors |
The survey data from the St. Louis Fed puts numbers to this gap. Among those who actually use generative AI, the average time saved comes to about 5.4 percent of their working hours. Spread across the entire workforce, that figure drops to just 1.4 percent of total hours.
The authors derive a potential productivity gain of about 1.1 percent from this, but emphasize that it remains unclear whether and when these potential gains will appear in measured productivity data. Without adjustments to work processes, goals, and responsibilities, the saved time can simply dissipate in daily work, absorbed as buffer time, informal breaks, or additional communication.
The sharpest test comes from a Danish registry study by Anders Humlum and Emilie Vestergaard. They linked usage surveys with administrative labor market data and found zero effects on income and recorded work hours two years after the introduction of chatbots. The authors largely rule out effects greater than 2 percent. They did, however, observe changes in tasks and occupational mobility. AI has effects, but local efficiency gains do not automatically translate into traditional labor market outcomes.
A European firm-level study by Aldasoro and colleagues offers a somewhat more positive picture. AI adoption raises labor productivity by an average of four percent, with no short-term decline in employment. The key question is where those effects appear. They are stronger in medium and large firms and in companies that already have complementary investments in software, data, and training. This, too, argues against the simple formula that more output automatically equals more value.
Projections from Penn Wharton, the OECD, and even model maker Anthropic do not expect explosive effects. They project additional productivity contributions of a few tenths to roughly one percentage point per year, depending on the country and scenario. Only a portion of work is affected, only a fraction of firms have deeply integrated AI, and only part of the time savings actually gets converted into value creation.
The incentive problem: no one reports the full picture
Productivity is hard to measure and socially charged. Anyone who admits that a task that once took five hours now takes three is essentially opening the door to a heavier workload and a reassessment of their position. No wonder workers have good reasons to keep quiet about time savings.
Executives and tool vendors have the opposite problem. They need to justify budgets and keep transformation narratives alive, so early ROI reports predictably sound more optimistic than later reality checks.
Workday reports that workers frequently describe noticeable time savings, but companies often fail to turn that freed-up capacity into better outcomes. Neither side is lying. They just see different things. Workers notice local time effects. Companies can only book a gain when that time actually feeds into better results.
That is precisely why the AI productivity debate remains vulnerable to exaggeration and understatement at the same time.
Hidden costs reduce gross gains
A central weakness in many productivity debates is that they focus on gross gains while ignoring net gains. A tool that saves five minutes of writing but triggers ten minutes of review may look impressive in the prompt window, yet barely improve the overall process. Because generative AI works probabilistically, part of its additional workload only appears after the response, in verification, post-editing, and quality assurance.
The BCG study on "AI Brain Fry" describes a form of cognitive exhaustion that arises from constantly supervising and evaluating multiple AI systems. Based on a survey of 1,488 US workers, about 14 percent of AI users reported such symptoms. AI partially replaces existing work processes, but it simultaneously creates new ones around checking and deciding.
BetterUp and the Stanford Social Media Lab describe another phenomenon they call "Workslop," AI-generated content that looks formally plausible but is substantively thin and requires downstream processing. In their survey, 40 percent of workers reported receiving such output in the past month. Dealing with it costs an average of nearly two hours per incident. What appears to be individual efficiency can re-emerge across the organization as shifted rework.
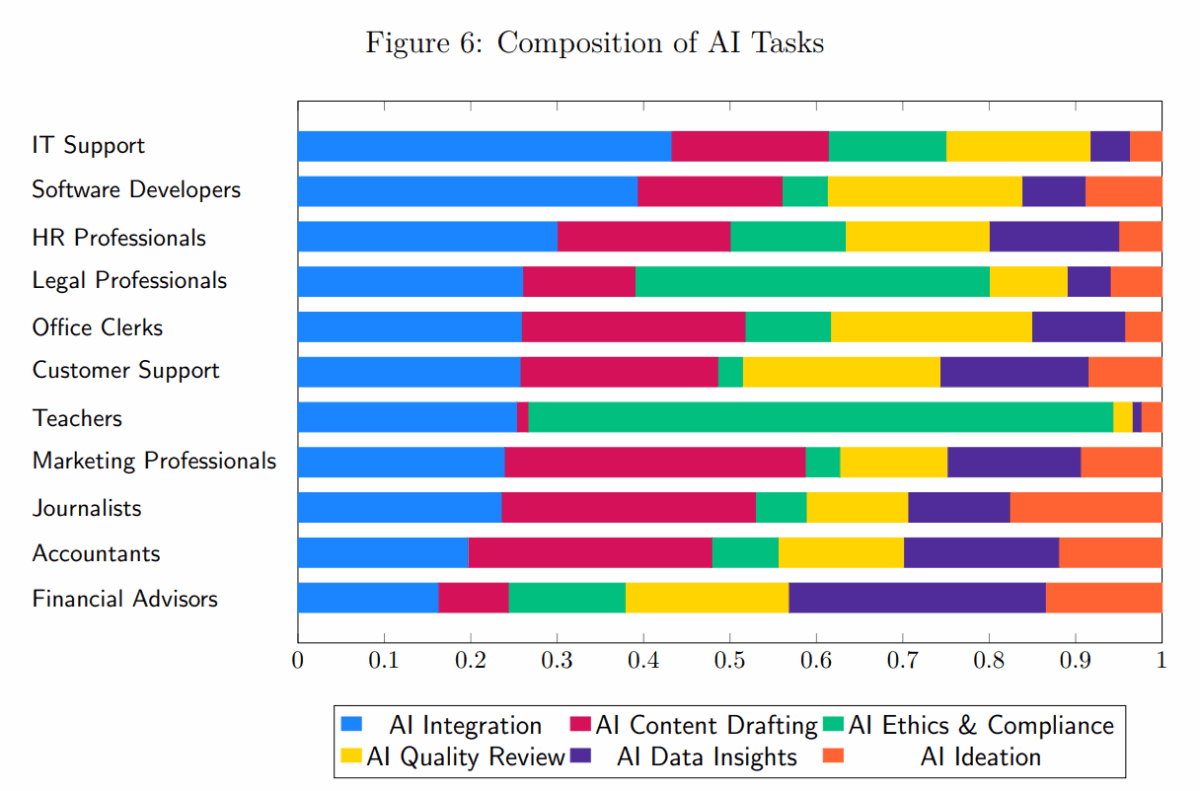
New tasks introduced by AI chatbots break down differently by profession. While IT support and software development focus mainly on integration and drafting, teachers deal primarily with ethics and compliance, and financial advisors with data insights. The weighting reflects average shares among respondents with new AI tasks. The share of actual content creation with AI remains small. | Image: Humlum, VestergaardThe longer-term costs involve learning and skill development. An Anthropic study with 52 software developers found that heavy AI use while learning a new library made developers marginally faster but led to 17 percent worse results on a knowledge test. A company can speed up work today while simultaneously weakening the training foundation for the years ahead. How AI was used made the difference. Developers who used it for explanations learned significantly better than those who heavily delegated tasks to it.
On top of that, there is a metacognitive problem. A study in Computers in Human Behavior shows that ChatGPT improves performance on reasoning tasks but simultaneously distorts self-assessment. Users performed better yet systematically overestimated their own competence. A tool that speeds up output while inflating a person's sense of their ability can increase error risk precisely where subjective confidence is high and actual understanding is limited.
Finally, there are operational, integration, and governance costs. Embedding a model securely, in an audit-proof and legally defensible way, with technical compatibility across an organization, takes significant effort. Yet these costs rarely feature in the public productivity debate. Anyone who measures only the speed of the first draft while ignoring the full costs of review, approval, monitoring, and training is measuring gross productivity, not net productivity.
What should actually be measured
The standard AI question is how much faster a task gets done. The better question is what changes in the process and which of those changes create value.
A more useful measurement framework would need to distinguish at least five levels.
- First, cycle time of entire processes, not just the completion time of individual tasks.
- Second, error and rework rates, not just output volume.
- Third, quality level, meaning whether results are at least as good as before.
- Fourth, customer value, such as faster responses, higher satisfaction, or fewer escalations.
- And fifth, economic impact, including revenue, margin, conversion, or better allocation of highly skilled labor.
Equally important is the question of what happens to freed-up capacity. The studies from the St. Louis Fed and the Microsoft/NBER field experiment show that time savings can be real. But that time becomes economically productive only when it is redirected into value-creating work. Time saved without that second step is only half a productivity metric.
Value is created beyond the benchmark
US productivity data for 2025 looks more robust, AI adoption continues to grow according to the OECD, and firm-level data points to real productivity gains. But those same years are also marked by measurement noise, data revisions, and the fact that personal use is growing much faster than deep organizational integration. According to the Budget Lab at Yale University, the data should not yet be read as evidence of an AI boom.
The narrative that AI saves time is incomplete at every level. Time savings are the first, easily measurable stage. Value emerges only at the second stage, when processes get shorter, decisions improve, errors become less frequent, or marginal costs decline. The real question is under which organizational conditions local acceleration actually turns into economic impact.
Three scenarios: baseline, acceleration, slowdown
Generative AI leads to measurable time savings on individual tasks. Numerous studies confirm this. But between this micro-level efficiency and real economic productivity lies a systematic gap. Verification overhead, missing metrics for knowledge work, hidden costs, and organizational inertia prevent benchmark gains from showing up in corporate balance sheets and economic data. The debate often treats the path from a faster individual task to value creation as a given. In reality, that path is the difficult part.
Baseline scenario: the translation gap
If current dynamics continue, AI tools will keep spreading through workflows over the next two to three years. But companies will make only limited changes to their processes, measurement systems or incentive structures. Individual time savings will remain real yet largely dissipate into buffers, additional communication and visibility-driven busywork.
Economy-wide productivity gains will stay in the range of a few tenths of a percentage point per year, in line with projections from Penn Wharton, the OECD and Anthropic. The gap between enthusiastic pilot reports and more restrained economic data will persist, sustaining both hype and disappointment narratives.
Acceleration scenario: breakthroughs through process redesign and better measurement
An acceleration scenario would materialize if significantly more reliable models converged with systematic process redesign within companies and the development of robust value-creation metrics for knowledge work. One possible trigger would be a breakthrough in autonomous coding agents that can complete entire development cycles. Today's success rates of 11 to 24 percent on complex tasks would need to increase substantially.
Another trigger could be industry-wide standards for measuring AI-assisted workflows. Company-level productivity gains could then become tangible, in the range of three to five percent annually in highly digitized sectors. The downside would be increased pressure on workers, whose task profiles could shift faster than retraining systems can adapt.
Slowdown scenario: the net-gain trap
The restraining factors are already visible. Increasing mental fatigue from supervising AI systems around the clock, a growing volume of output that reads well but says little, the slow hollowing out of skills among less experienced workers, and steadily rising costs for compliance and risk management.
Should these trends collide with a plateau in model performance or a prominent AI failure, widespread disenchantment could set in. Companies would scale back AI budgets or limit use to tightly scoped applications. Any economy-wide productivity effects would remain lost in statistical noise for years to come.
Our assessment
We consider the baseline scenario by far the most likely. The research shows a consistent pattern: the technology works at the task level, but organizations change slowly. We see the same in our work supporting AI adoption across companies in the DACH region.
Historical comparisons with the PC, the internet, and cloud computing suggest that roughly a decade tends to pass between technological availability and measurable productivity impact.
The critical bottleneck, in our view, is organizational absorptive capacity: redesigning workflows, developing measurement systems, adjusting incentive structures, and building accountability frameworks. As long as companies track activity metrics rather than value-creation metrics, and workers have good reasons to keep efficiency gains to themselves, the productivity gap will remain a structural problem. That holds regardless of how capable the next generation of models becomes.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.