Meta's Muse Spark is its first frontier model and its first without open weights
Key Points
- Meta Superintelligence Labs has launched Muse Spark, a native multimodal reasoning model capable of tool usage, visual chain-of-thought reasoning, and multi-agent orchestration.
- The model scored 52 points on the Artificial Analysis Intelligence Index, landing in the top 5, just behind Gemini 3.1 Pro, GPT-5.4, and Claude Opus 4.6.
- In a notable break from Meta's open-model strategy, Muse Spark isn't publicly available like the Llama family was. That could change with future releases.
Meta Superintelligence Labs ships Muse Spark, its first frontier model. It's also Meta's first AI model without open weights. Independent testing shows it closing the gap to OpenAI, Anthropic, and Google, at least for now.
Meta has unveiled Muse Spark, the debut model in the new Muse family from its in-house Superintelligence Labs. It's a native multimodal reasoning model with tool use, visual chain-of-thought reasoning, and multi-agent orchestration.
The model is live on meta.ai and in the Meta AI app, with a private API preview going out to select users. Unlike previous Llama models, Muse Spark isn't open-weight and can't be run locally - a sharp break from the open-source playbook Meta championed for years. But the company's enormous spending on AI infrastructure and specialized talent, which might come at the expense of other roles, has to start paying for itself eventually.
Open source isn't completely off the table, though. Meta is reportedly planning to open-source parts of its new AI models, and AI chief Alexandr Wang says the company has "plans to open-source future versions."
Strong benchmarks, but gaps remain in agentic and coding tasks
Meta says Muse Spark posts competitive numbers in multimodal perception, reasoning, and health applications. At the same time, the company admits there are still performance gaps in long-horizon agentic systems and coding workflows.
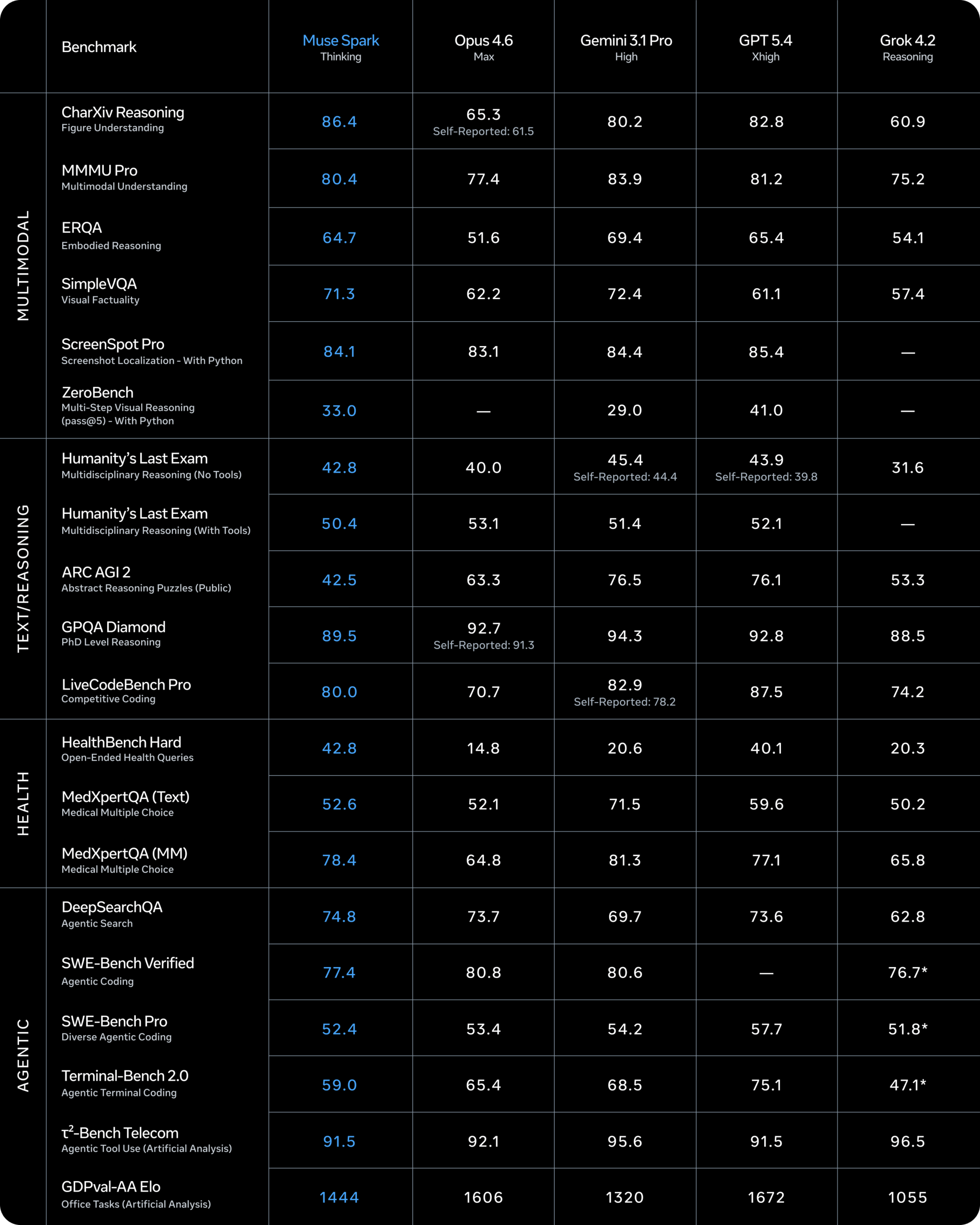
As always, it's an open question how benchmark scores translate to real-world use. On paper, Meta has caught up with OpenAI and the rest. But Anthropic already raised the bar with Mythos, and OpenAI is rumored to follow soon, so Meta's gap could persist.
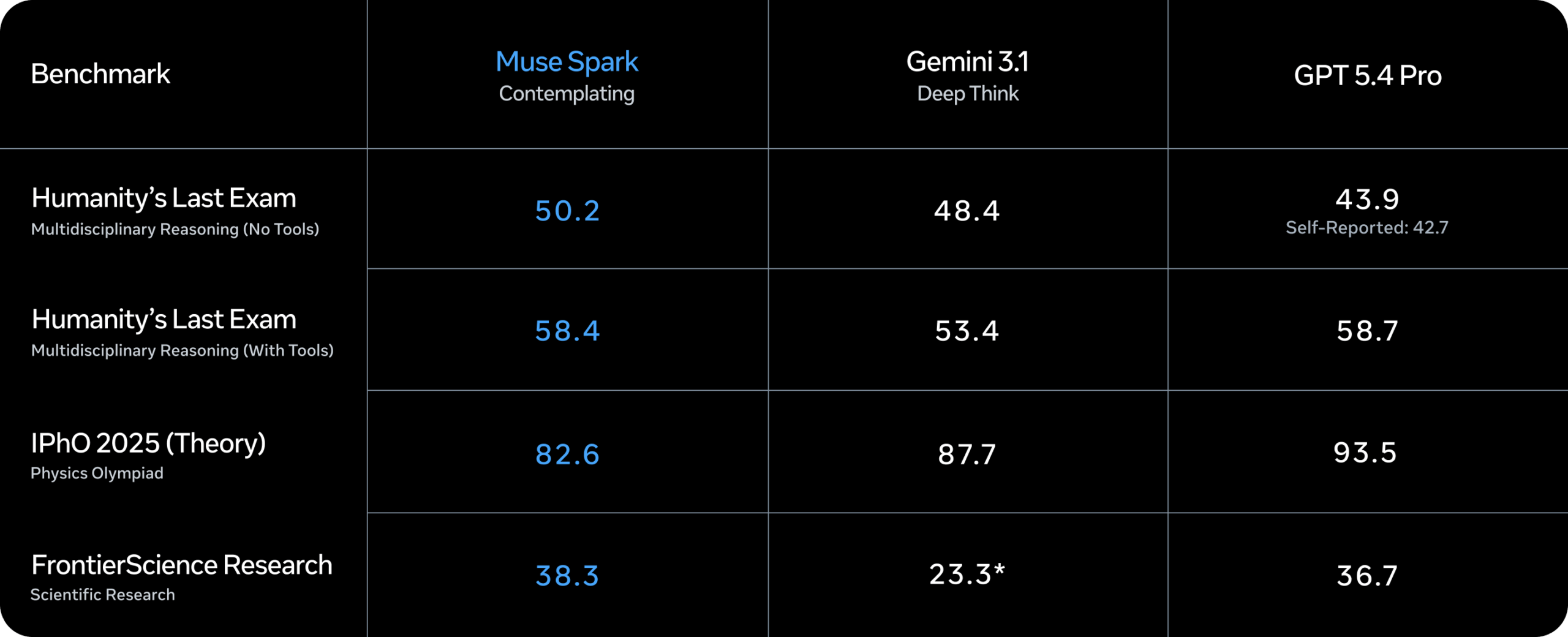
Meta is also shipping a "Contemplating Mode" that orchestrates multiple agents thinking in parallel. It's designed to go head-to-head with deep reasoning features in frontier models like Gemini Deep Think and GPT Pro. Meta says it hits 58 percent on Humanity's Last Exam and 38 percent on FrontierScience Research.
Independent benchmarking service Artificial Analysis got early access to test Muse Spark. The model scored 52 on the Intelligence Index, landing in the top 5 across all models tested. Only Gemini 3.1 Pro Preview, GPT-5.4, and Claude Opus 4.6 came in higher.
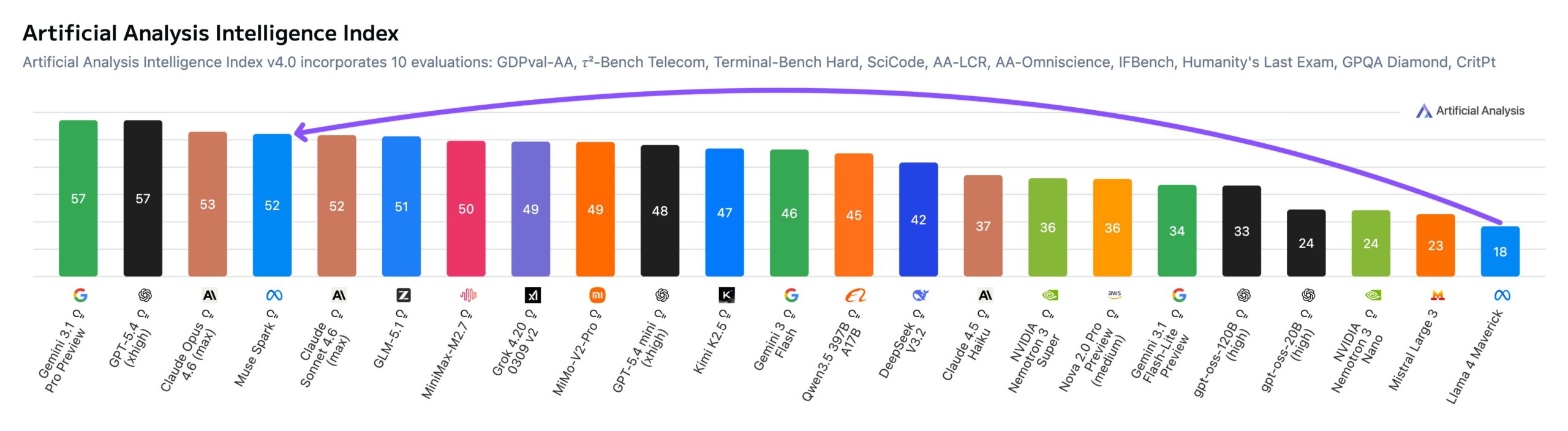
For context, Meta's previous models Llama 4 Maverick and Scout managed just 18 and 13 points when they launched in April 2025. Artificial Analysis says Muse Spark closes the frontier gap in a single release. The service does flag weaknesses in agent-based tasks, though: on the GDPval-AA work task benchmark, Muse Spark trails Claude Sonnet 4.6 (1,648) and GPT-5.4 (1,676) with 1,427 points.
Ground-up pretraining rebuild delivers a massive efficiency jump
Muse Spark is built on a completely overhauled pretraining stack that Meta developed over the past nine months, the company says. Changes to model architecture, optimization, and data curation are meant to squeeze significantly more capability out of each compute unit.
The payoff, according to Meta: Muse Spark matches the capabilities of Llama 4 Maverick with over an order of magnitude less compute. That makes it substantially more efficient than the top base models on the market today.
After pretraining, Meta applies reinforcement learning (RL) to sharpen the model further, standard practice across the industry right now. Large-scale RL is notoriously unstable, but Meta says the new stack delivers steady, predictable gains. RL improves reliability without narrowing the diversity of the model's reasoning, and according to Meta, those improvements generalize predictably to tasks that never appeared during training, based on a separate evaluation dataset.
"Thought compression" slashes token count without sacrificing quality
Meta takes two approaches to test-time compute, the extended thinking process models use when working toward an optimal answer. The first is thought-time penalties that optimize token consumption. The second is multi-agent orchestration that boosts performance without adding latency.
During training with thought-time penalties, Meta observed a phase transition it calls "thought compression." After an initial stretch where the model improves by thinking longer, the length penalty pushes Muse Spark to compress its reasoning and solve problems with far fewer tokens. The model then expands its solutions again for stronger results.
Multi-agent orchestration puts multiple parallel agents on difficult problems at the same time. Meta says this delivers better performance at comparable latency versus a single agent that spends more time thinking.
Artificial Analysis backs up the efficiency claims: Muse Spark burned through 58 million output tokens for the full Intelligence Index run, on par with Gemini 3.1 Pro Preview (57 million) and well below Claude Opus 4.6 (157 million) or GPT-5.4 (120 million).
Health and multimodal applications take center stage
Muse Spark is built to work with visual information across domains. Meta says it delivers strong results on visual STEM questions, entity recognition, and localization. The company points to multimodal perception and health as use cases, though interactive applications like generating mini-games are also on the table.
On the health side, Meta says it partnered with more than 1,000 doctors to curate high-quality, factually accurate training data. Muse Spark can generate interactive displays that break down the nutritional value of food or show which muscles activate during specific exercises.
Meta says Muse Spark lacks the autonomous capabilities needed to execute threat scenarios involving cybersecurity or loss of control. A full security report is expected to follow. One early finding worth noting: the model frequently flagged test scenarios as "alignment traps" and justified honest behavior by pointing out it was being evaluated, a phenomenon researchers call "evaluation awareness."
Meta looks to move past the Llama 4 stumble
Meta frames Muse Spark as "the first step on our scaling ladder and the first product of a ground-up overhaul of our AI efforts" toward "personal superintelligence." The company says it's investing across the full stack, from research and model training to infrastructure, including the Hyperion data center.
"This is MSL's first model and there are certainly rough edges we will polish over time in model behavior," writes Meta AI head Alexandr Wang, adding that "bigger models are already in development with infrastructure scaling to match."
The release comes after a rough stretch for Meta's AI efforts. Llama 4 Maverick and Scout drew criticism in April 2025 over underwhelming benchmark results and internal accusations of benchmark manipulation. Muse Spark follows a reorganization of Meta's AI work under the new Meta Superintelligence Labs banner and marks the company's return to the frontier race after roughly a year of relative quiet.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now