Chatbot Arena helps you find the best open-source chatbot

Until now, there has been no easy way to compare the quality of open-source models. An e-sports-inspired system could help.
The Large Model System Organization (LMSYS), which is behind the open-source model Vicuna, has launched the benchmark platform "Chatbot Arena" to compare the performance of large language models. Different models compete against each other in anonymous, randomly selected duels. Users then rate the performance of the models by voting for their preferred answer.
Based on these ratings, the models are ranked according to the Elo rating system, which is widely used in chess and especially in e-sports. In principle, users can ask anything and even have long conversations, but they cannot directly ask for the model's name - this disqualifies their vote for the ranking.
GPT-4 reaches highest Elo, but Claude is close
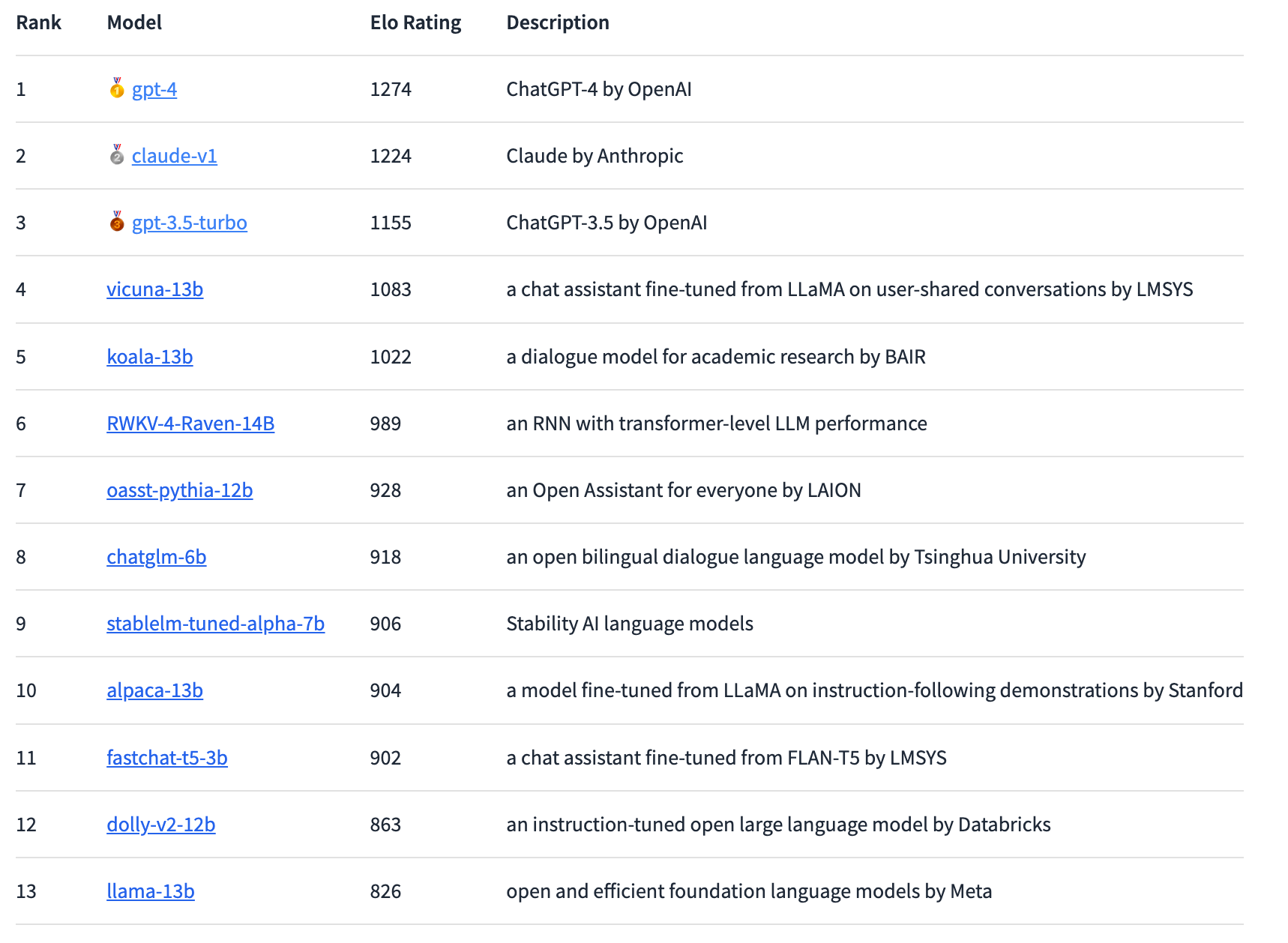
Using this method, GPT-4 currently leads the ranking, closely followed by Claude-v1 and GPT-3.5-turbo with a slightly larger gap. The highest-rated open-source model is Vicuna-13B. In the future, the researchers plan to integrate more open-source and closed-source models and break down the rankings more precisely.
Since the leak of Meta's LLaMA language model, a number of open-source language models have emerged that, like ChatGPT, are designed to follow human instructions and answer user questions in a chatbot-like fashion. The difficulty, however, is in effectively evaluating these models, especially for open-ended questions.
Enter Chatbot Arena
Here, the Chatbot Arena offers a promising new approach. The Elo system for evaluating large language models has already been used by Anthropic for a Claude benchmark.
In the arena, models compete directly with each other and users vote for the best model by interacting with them. The platform collects all user interactions but uses only the votes cast with the models' names unknown. According to LMSYS, about 4,700 valid anonymous votes were received a week after launch, and by early May the number had grown to about 13,000.
The results so far show a "substantial gap" between proprietary and open-source models, according to LMSYS. However, the open-source models represented in the arena also had significantly fewer parameters, ranging from three to 14 billion. Without counting ties, GPT-4 wins 82 percent of duels against Vicuna-13B and 79 percent of duels against GPT-3.5-turbo. Anthropic's Claude outperforms GPT-3.5 in the arena and is on par with GPT-4.
In addition to the Arena competition, the Side-by-Side mode is particularly convenient: You can select individual open-source language models and feed them with the same prompt at the same time. The results can be compared in real-time.
Head over to Chatbot Arena if you'd like to participate in the voting or find an open-source language model that's useful to you. Former GitHub CEO Nathaniel Friedman's Playground platform works similarly.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.