Microsoft unveils multimodal AI assistant for biomedicine

Researchers at Microsoft demonstrate LLaVA-Med, a multimodal AI assistant for biomedicine that can process images as well as text.
A large dataset of biomedical image-text pairs was used to train the multimodal AI model. The dataset includes chest X-rays, MRI, histology, pathology, and CT images, among others. First, the model learns to describe the content of such images and thus important biomedical concepts. Then, LLaVA-Med (Large Language and Vision Assistant for BioMedicine) was trained with an instruction dataset generated by GPT-4.
This dataset is created by GPT-4 based on the biomedical texts that contain all the information about each image and can be used to generate question-answer pairs about the images. In the fine-tuning phase, LLaVA-Med is then trained on the images and the corresponding GPT-4 examples.
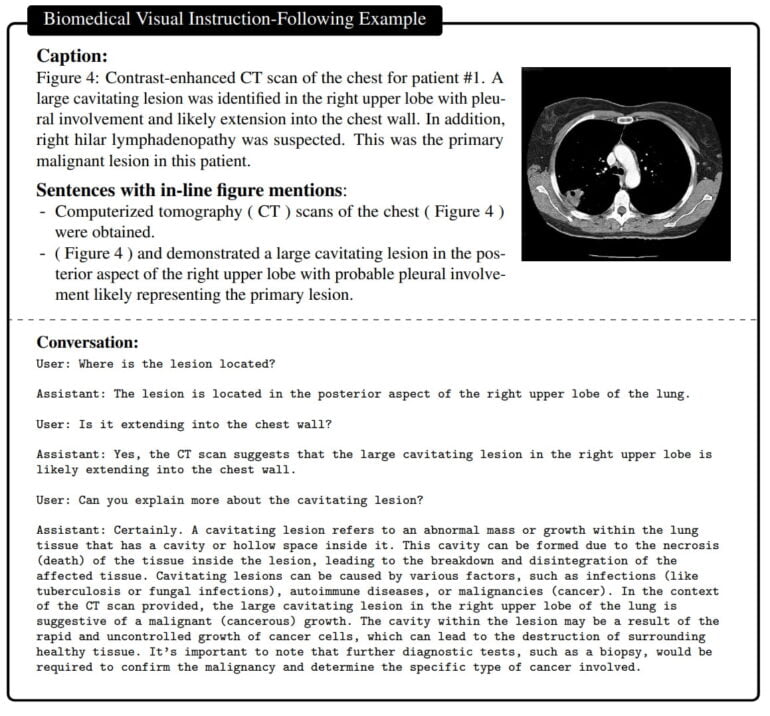
The result is an assistant that can answer questions about a biomedical image in natural language.
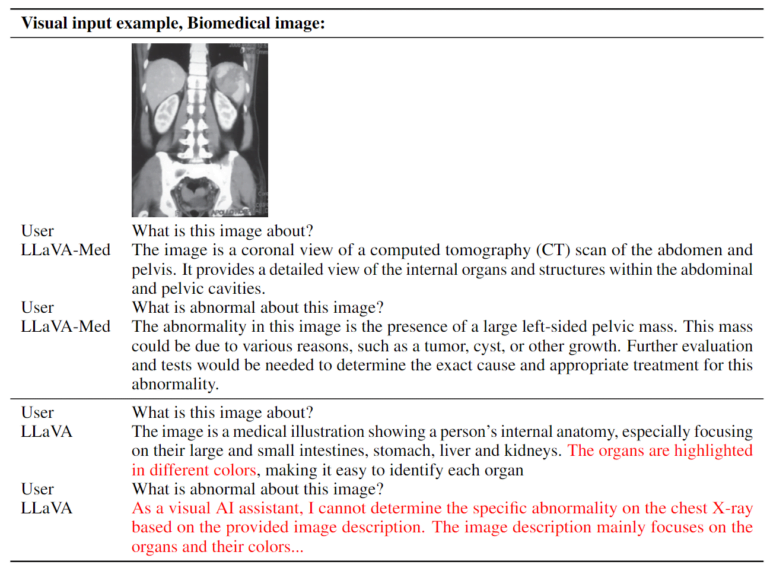
LLaVA-Med was trained in 15 hours
The training method used allowed LLaVA-Med to be trained on eight Nvidia A100 GPUs in less than 15 hours. It is based on a Vision Transformer and the Vicuna language model, which in turn is based on Meta's LLaMA. According to the team, the model has "excellent multimodal conversational capability". On three standard biomedical datasets for answering visual questions, LLaVA-Med outperformed previous state-of-the-art models on some metrics.
Multimodal assistants such as LLaVA-Med could one day be used in a variety of biomedical applications, such as medical research, interpretation of complex biomedical images, and conversational support in healthcare.
But the quality is not yet good enough: "While we believe that LLaVA-Med represents a significant step towards building a useful biomedical visual assistant, we note that LLaVA-Med is limited by hallucinations and weak in-depth reasoning common to many LMMs," the team says. Future work will focus on improving quality and reliability.
More information is available on GitHub.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.