GPT-4 dominates other LLMs in "real-world pragmatic missions," study finds

There are many commercial and open-source generative text AIs. A benchmark developed specifically for testing assistance tasks now shows that GPT-4 stands out in this segment.
"AgentBench" is a standardized test specifically designed to measure the assistance capabilities of large language models in "real-world pragmatic missions". All tests are conducted in real-time interactive environments. This makes the benchmark particularly suitable for what it is intended to measure: how well a large language model can handle a variety of everyday tasks in a total of eight areas.
- Operating System: Here, LLMs must perform tasks related to the use of a computer operating system.
- Database: This environment is about how well LLMs can work with databases.
- Knowledge Graph: This environment tests how well LLMs can work with knowledge graphs.
- Digital card game: This tests how well LLMs can understand digital card games and develop strategies.
- Lateral thinking puzzles: This challenge tests how creative LLMs can be in solving problems. It requires them to think outside the box.
- Budgets: This scenario is about tasks that occur in a budget, based on the Alfworld dataset.
- Internet Shopping: This scenario tests how well LLMs perform on tasks related to online shopping.
- Web browsing: Based on the Mind2Web dataset, this scenario tests how well LLMs can perform tasks related to using the Internet.
Video: AgentBench
GPT-4 is by far the most capable AI model
In total, the team of researchers from Tsinghua University, Ohio State University, and UC Berkeley tested 25 large language models from multiple providers, as well as open-source models.
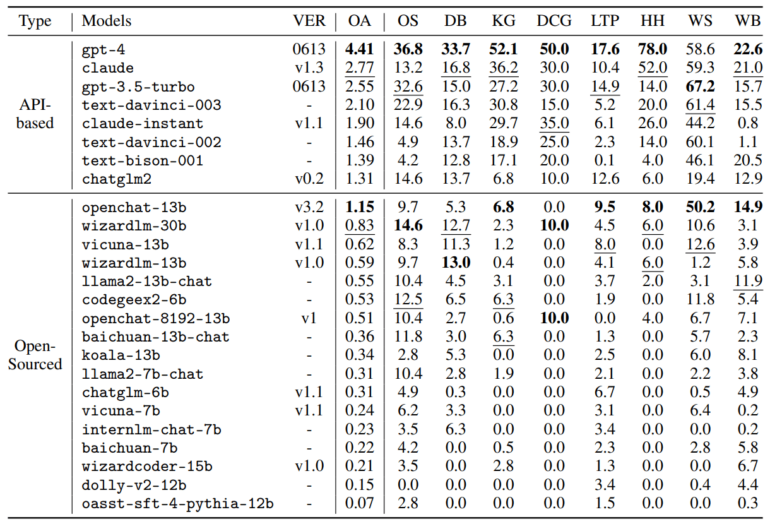
The result: OpenAI's GPT-4 achieved the highest overall score of 4.41 and was ahead in almost all disciplines. Only in the web shopping task, GPT-3.5 came out on top.
The Claude model from competitor Anthropic follows closely with an overall score of 2.77, ahead of OpenAI's free GPT-3.5 Turbo model. The average score of the commercial models is 2.24.
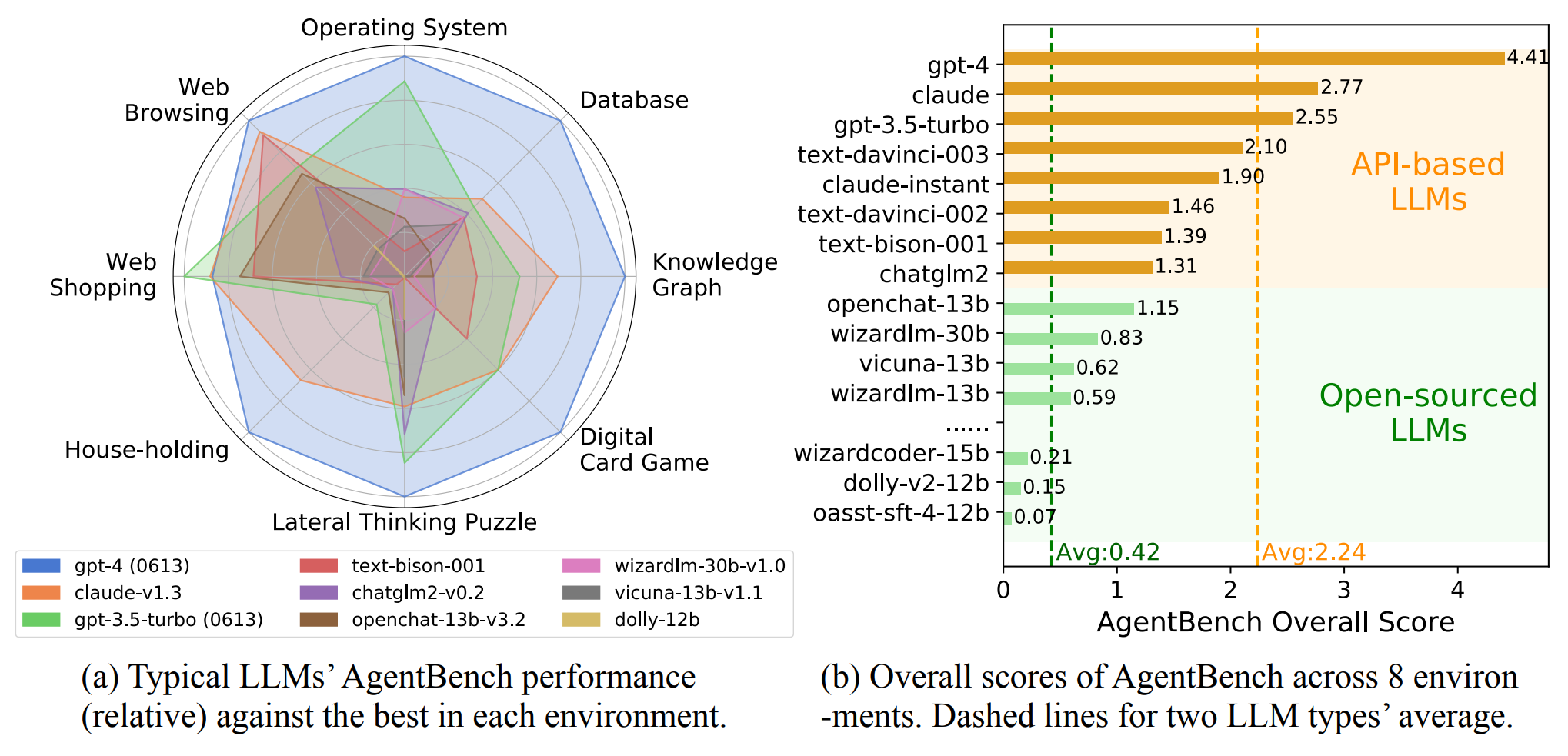
The gap between GPT-4 and the commercial and open-source models, in general, is even more pronounced: The average performance score of open-source models is only 0.42 points. They generally fail in all complex tasks and are far behind GPT-3.5, the researchers write. OpenChat based on Llama-13B is the best-performing OS model with 1.15 points.
We unveil that while top LLMs are becoming capable of tackling complex real-world missions, for open-sourced competitiors there are still a long way to go.
From the paper
The preliminary results list is missing many commercial models such as PaLM 2 from Google, Claude 2 or the models from Aleph Alpha as well as other open-source models.
The research team is therefore making a toolkit, the datasets, and the benchmark environment available to the research community on Github for more extensive performance comparisons. More information and a demo are available on the project website.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.