Microsoft's Medprompt demonstrates the power of prompting

With Microsoft's Medprompt, GPT-4 outperforms specialized models in medical applications. The prompt has other applications as well.
OpenAI GPT-4 has shown in the past that it can answer medical questions with a high degree of accuracy using appropriate prompts. In many cases, however, the large language model still lagged behind specialized variants such as Med-PaLM-2.
In a new paper, a Microsoft team has now shown that GPT-4 achieves new benchmarks for medical questions, outperforming even specialized models. This leap is due to a new prompting strategy that combines different approaches and is transferable to other domains.
Microsoft's Medprompt combines three methods
The method, which they call "Medprompt," combines dynamic few-shot selection, self-generated chain-of-thought (CoT), and choice shuffle ensembling.

The three elements of Medprompt are
- Dynamic selection of examples: For each question, previously collected similar training examples are selected to provide context to the model.
- Self-generated Chain of Thought: The model independently generates a CoT prompt using previously automated CoT prompts from training data.
- Choice Shuffle Ensembling: Answer options are presented multiple times in different order to avoid bias due to the position of the options. The best answer is selected by majority vote from the multiple answers generated in this way.
The previously created training examples, which contain questions and answers as well as CoT prompts that led to correct answers, are also automatically generated from benchmarks using GPT-4 and an embedding model. The embeddings are used in the inference phase to find similar examples for the new questions.
Medprompt achieves new state-of-the-art in medical benchmarks
With Medprompt, the team was able to achieve a GPT-4 hit rate of over 90% on the MedQA dataset for the first time, and the best-reported results on all nine benchmark datasets in the MultiMedQA suite. Further improvements were achieved by increasing the number of few-shot exemplars and the number of ensemble steps.
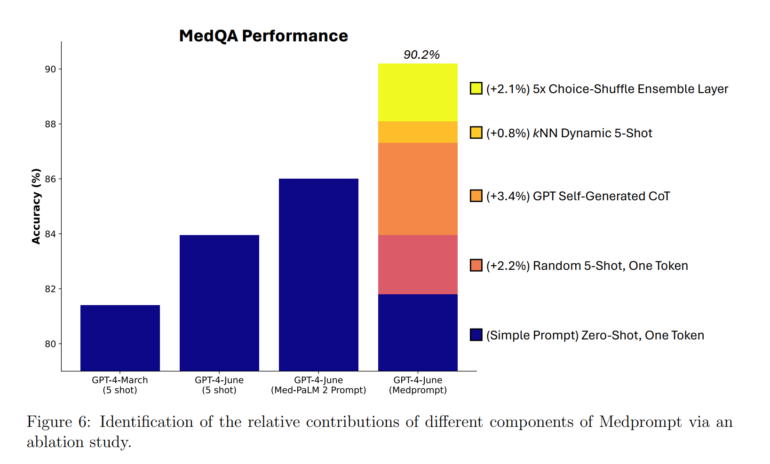
However, the researchers point out that the good performance of GPT-4 with Medprompt in benchmarks does not directly reflect the effectiveness of the model and methods in the real world.
Medprompt also shows improvements in other areas
The developed prompt is transferable to other applications because it does not require expert knowledge and manual prompt design, as in the Few-Shot examples or the Chain-of-Thought prompt. The team conducted several tests in areas of the MMLU benchmark, such as professional law, professional accounting, philosophy, or professional psychology. In all areas, Medprompt showed an average improvement of 7.3 percent.
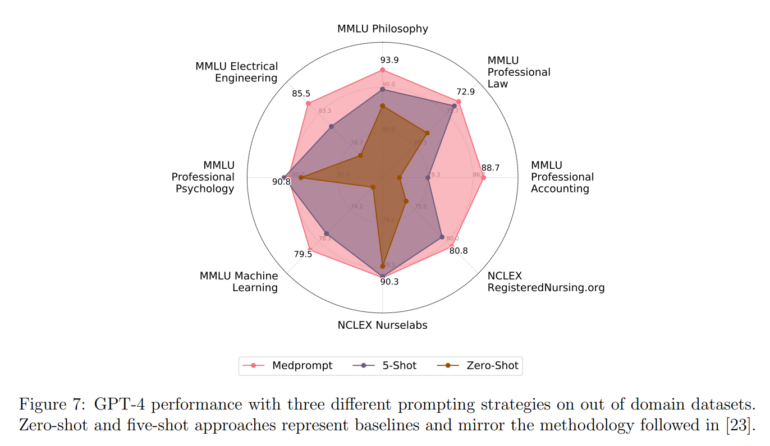
The team sees these results as a clear indication that the framework on which Medprompt is based can be generalized to other domains and applications beyond multiple-choice questions.
All implementation details can be found in the paper.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.