AI chatbots become dramatically less reliable in longer conversations, new study finds

A new study from Microsoft and Salesforce finds that even state-of-the-art AI language models become dramatically less reliable as conversations get longer and users reveal their requirements step by step. On average, the systems' performance dropped by 39 percent in these scenarios.
To simulate how people actually interact with AI assistants, the researchers created a method called "sharding." Instead of giving the model everything up front, they broke each task into smaller pieces—mirroring the way users typically specify what they want over the course of a conversation.
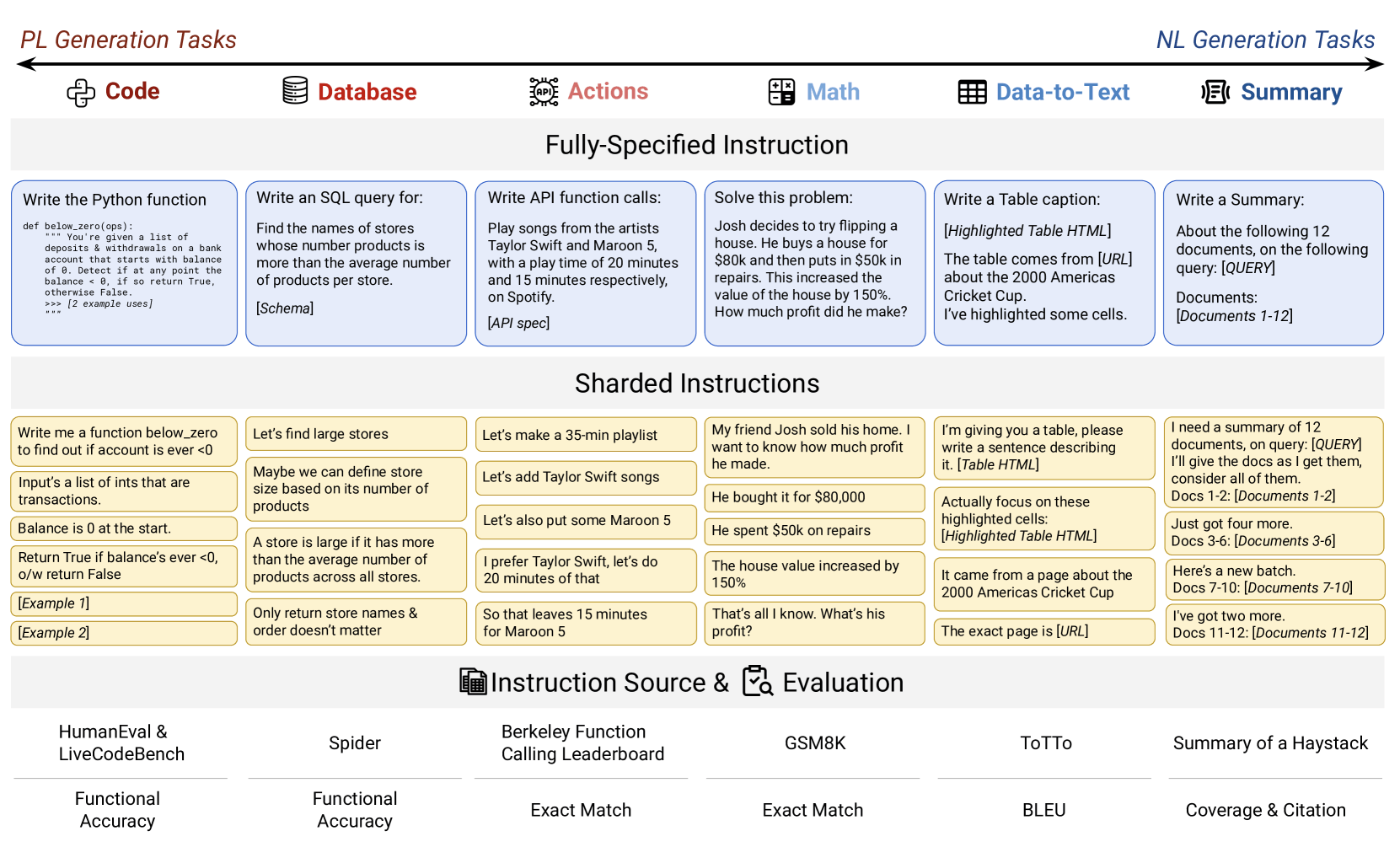
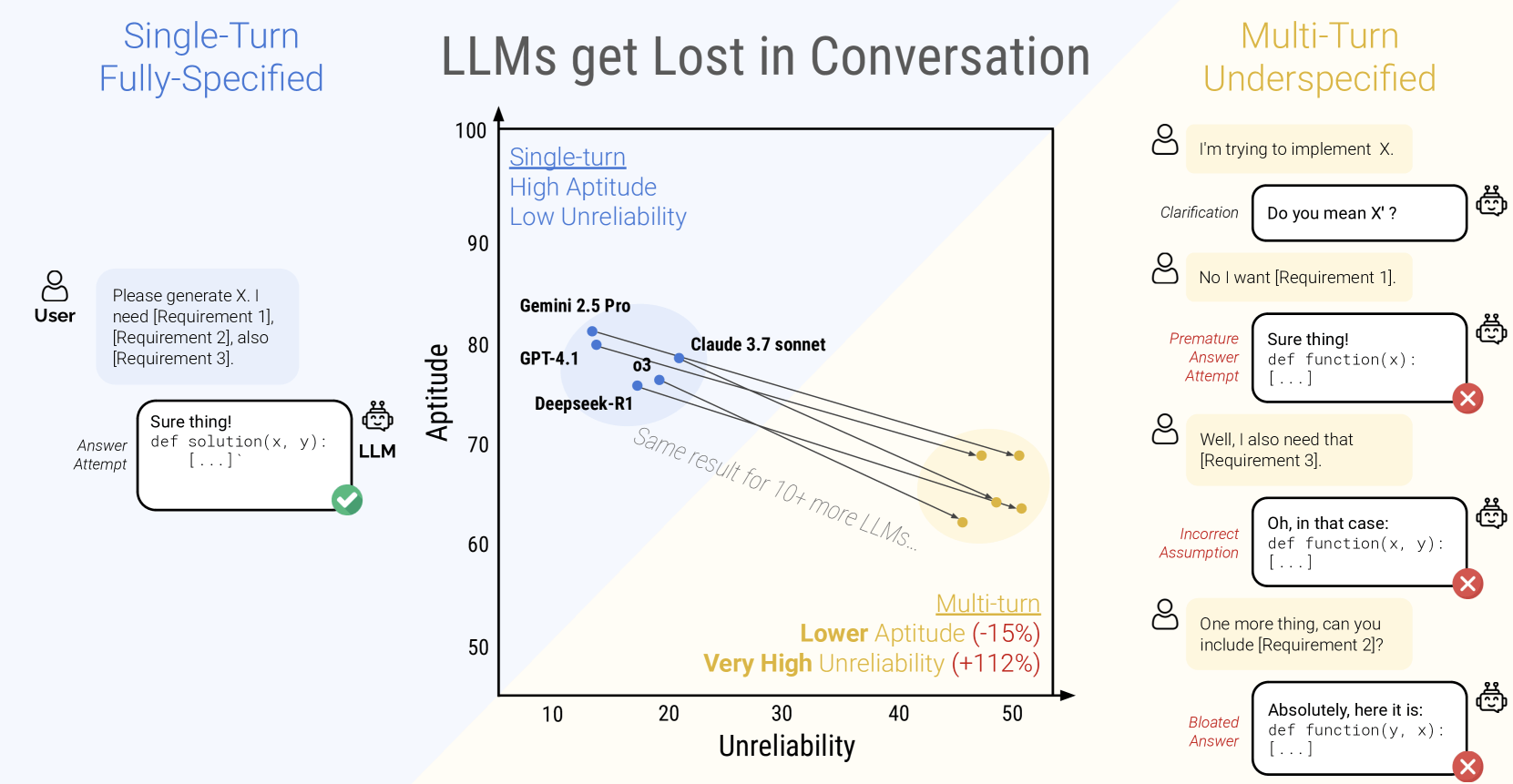
When the AI models had to handle these step-by-step instructions, their accuracy dropped from about 90 percent to just 51 percent. This steep decline was seen across all 15 models tested, from smaller open-source models like Llama-3.1-8B to big commercial systems like GPT-4o.
Even the top-tier models in the study—Claude 3.7 Sonnet, Gemini 2.5 Pro, and GPT-4.1—performed 30 to 40 percent worse in multi-round conversations compared to single-turn prompts. The models also became much less consistent, with results varying far more than in one-shot interactions.
The researchers identified four key problems: models frequently rush to conclusions prematurely, without having all the necessary details. They rely excessively on their own past (occasionally wrong) responses, neglect information from the middle of the discussion, and produce overly detailed responses, leading to incorrect assumptions about gaps in information.
Technical tweaks don’t fix the problem
The team tried several technical fixes to improve reliability, such as lowering the model’s temperature setting (which controls randomness) and having an agent repeat user instructions. None of these changes made a meaningful difference in performance.
Changing how much detail was given at each step didn't help either. The only thing that reliably worked was giving the AI all the information right at the beginning.
The performance drop had two parts: The models' basic skill (aptitude) decreased only slightly—by about 16 percent. But unreliability soared by 112 percent. In single-turn tasks, models with higher aptitude were usually more reliable. But in multi-turn chats, all models were similarly unreliable, regardless of their baseline skill. For the same task, results could swing by as much as 50 percentage points between the best and worst run.
What users and developers can do
Based on these results, the researchers suggest two practical strategies: If you get stuck, start a new conversation instead of trying to fix one that's gone off track. And at the end of a session, ask for a summary of all requirements and use that summary as the starting point for a new chat.
The researchers say that AI developers should put much more emphasis on reliability in multi-turn conversations. Future models should be able to deliver consistently good results even when the instructions are incomplete—without relying on special prompting tricks or constant temperature adjustments. Reliability matters just as much as raw performance, especially for real-world AI assistants, where conversations tend to be step-by-step and user needs can change along the way.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.