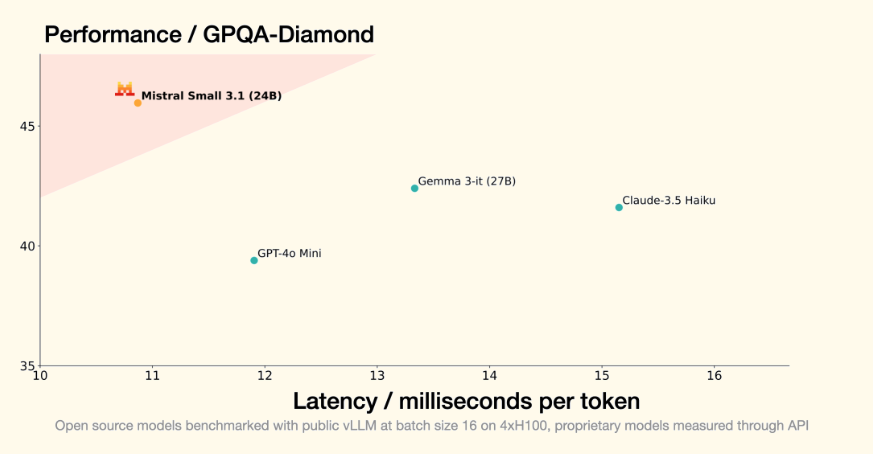
Mistral AI has released an updated version of its Small 3 model, now available as Small 3.1 under the Apache 2.0 license. The latest iteration brings enhanced text processing abilities, multimodal understanding, and an expanded context window that can handle up to 128,000 tokens. According to Mistral AI, Small 3.1 delivers better performance than similar models like Google Gemma 3 and GPT-4o-mini, achieving inference speeds of 150 tokens per second. The model runs on consumer hardware like a single RTX 4090 graphics card or a Mac with 32 GB of RAM. You can download Mistral Small 3.1 via Huggingface as a base and instruct version, or use it through the Mistral AI API and on Google Cloud Vertex AI. The company plans to expand availability to NVIDIA NIM and Microsoft Azure AI Foundry platforms in the coming weeks.