
AI researchers train an AI agent in increasingly complex environments. The automated process is outpacing other training approaches
In reinforcement learning, an AI agent learns to perform certain tasks in its environment by trying very often. This AI learning method has achieved numerous successes in recent years and is seen as a potential solution to problems in autonomous driving or robotics. Prominent examples are the AI systems from Deepmind, which master video and board games.
Training an agent to solve a single task in a specific environment is relatively simple. For example, an agent that merely needs to find its way around a maze can memorize the path or develop a simple strategy that will lead to success in that environment.
Agents trained in a fixed environment, however, do not generalize to other environments and therefore fail even with small changes. AI research hence relies on different approaches to train robust AI agents that can perform many tasks in numerous environments.
More flexible AI agents: Randomization is not enough
One obvious method is to randomize the environments provided in training. For example, in a simulation, a robot may face ever-changing surfaces, steps, gaps, or multiple mazes.
In practice, however, randomly changing the environment is not enough to train robust agents. AI researchers are therefore turning to methods with "adaptive curricula," in which the complexity of the training environments is based on the agent's current capabilities. One example of this is a building block simulation from OpenAI in which one simulated robotic arm continually presents another with more complex tasks.
Such adaptive methods have already shown in practice that they can produce more robust agents in fewer training steps than randomized methods. Because adaptive methods adjust the distribution of training environments to the agent's ability, these methods are considered a form of "unsupervised environment design" (UED), in which a kind of teacher independently selects and assigns environments to the agent for training.
ACCEL modifies challenging environments on its own
In the research paper "Adversarially Compounding Complexity by Editing Levels" (ACCEL), AI researchers from the University of Oxford, University College London, University College Berkeley, University Oxford, and Meta AI present a new UED method for training more robust AI agents.
The researchers have a generator randomly select training environments and rate them according to their difficulty. To accomplish this, ACCEL scores the difference between an agent's actual performance in an environment and its possible best performance, or "regret."

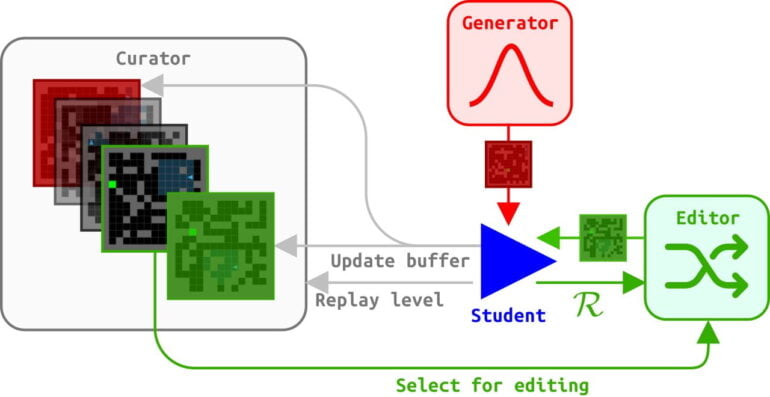
To that extent, ACCEL is similar to Prioritized Level Replay (PRL), currently one of the strongest UED methods. However, while PRL keeps randomly selecting new training environments after each training run, in ACCEL a curator evaluates the training results before the next run.
Environments that were previously too difficult for the agent are randomly modified minimally: In a maze, for example, walls are replaced or added; in a walking simulation, the number of steps or height differences are changed.
The modified environments are reassigned to the training curriculum - as long as their Regret value is still high after the modification. ACCEL thus constantly generates new environments at the limit of the agent's capabilities.
ACCEL outperforms other methods
Compared to other UED methods, ACCEL consistently trains agents that can handle difficult environments after training. For example, a trained ACCEL agent can find its way around human-designed mazes without additional training and even transfers its abilities, with limitations, to mazes that are significantly larger than the training examples.
In the BidpedalWalker simulation, the ACCEL method also generates a steadily more difficult curriculum based on the agent's abilities. ACCEL creates a highly capable agent that consistently outperforms agents trained with other UED methods in zero-shot transfer (see maze example above), the authors say. ACCEL thus produces capable generalists.
However, they said it is likely that as more difficult environments evolve, specialists will become increasingly important, such as those produced by the POET UED method. POET co-evolves agent-environment pairs and searches for specialized strategies to solve specific tasks.
ACCEL creates increasingly complex curricula. In the end, the agent walks away. | Video: https://accelagent.github.io/
These specialists may be more effective at discovering diverse and complex behaviors - but at the price of potentially over-adapting to their respective environments: The model memorizes individual solutions instead of learning to recognize features that lead to the solution. The interplay between generalists and specialists is a fascinating open question, the authors say.
For more information about the UED method and an interactive demo, visit the ACCEL project page.





