Apple AI researchers question OpenAI's claims about o1's reasoning capabilities

A new study by Apple researchers, including renowned AI scientist Samy Bengio, calls into question the logical capabilities of today's large language models - even OpenAI's new "reasoning model" o1.
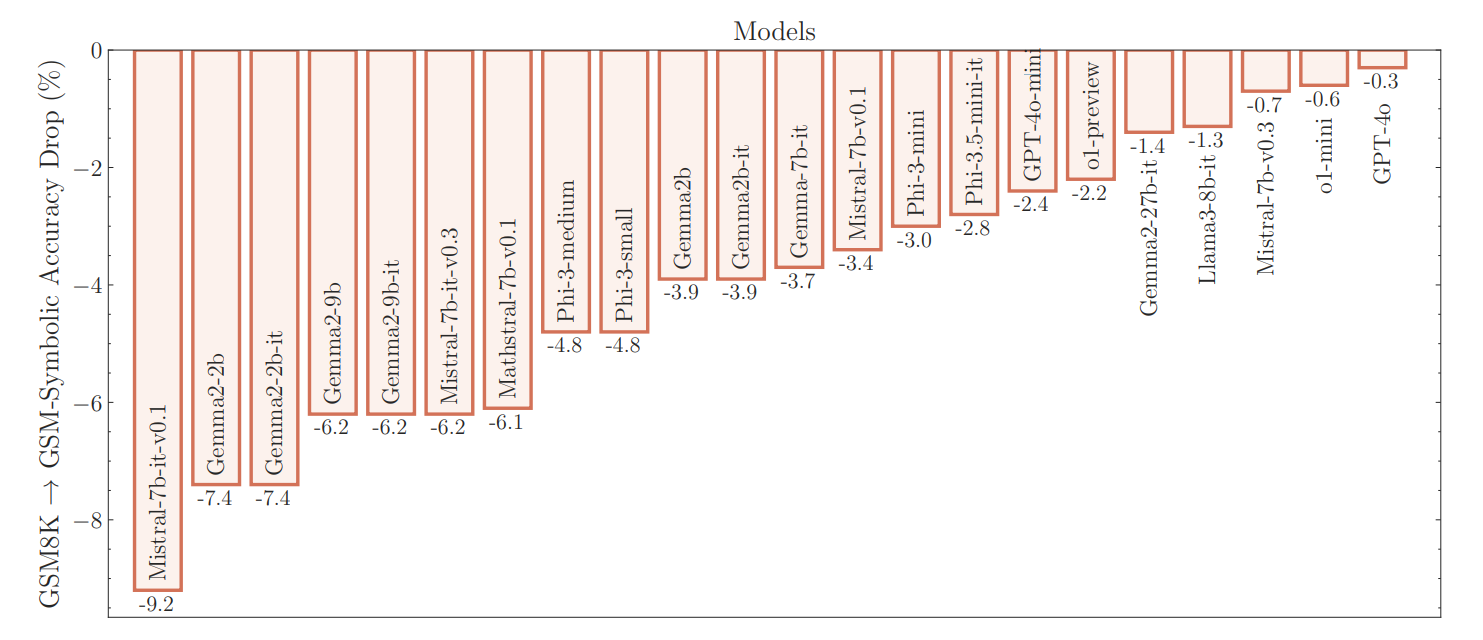
The team, led by Mehrdad Farajtabar, created a new evaluation tool called GSM-Symbolic. This tool builds on the GSM8K mathematical reasoning dataset and adds symbolic templates to test AI models more thoroughly.
The researchers tested open-source models such as Llama, Phi, Gemma, and Mistral, as well as proprietary models, including the latest offerings from OpenAI. The results, published on arXiv, suggest that even leading models such as OpenAI's GPT-4o and o1 don't use real logic, but merely mimic patterns.
Adding irrelevant information decreases performance
The results show that current accuracy scores for GSM8K are unreliable. The researchers found wide variations in performance: The Llama-8B model, for example, scored between 70 percent and 80 percent, while Phi-3 fluctuated between 75 percent and 90 percent. For most models, the average performance on GSM-Symbolic was lower than on the original GSM8K, says Farajtabar.
The experiment with the GSM-NoOp dataset was particularly revealing. Here, the researchers added a single statement to a text problem that seemed relevant but didn't contribute to the overall argument.
The result was a decline in performance for all models, including OpenAI's o1 models. "Would a grade-school student's math test score vary by ~10% if we only changed the names?" Farajtabar asks rhetorically.

Farajtabar emphasizes that the real issue is the dramatic increase in variance and drop in performance as the difficulty of the task increases only slightly. To handle the variation with increasing difficulty probably requires "exponentially more data."
Scaling would only lead to better pattern matchers
While the OpenAI o1 series, which achieves top scores on many benchmarks, performs better, it still suffers from performance fluctuations and makes "silly mistakes," showing the same fundamental weaknesses, according to the researchers. This finding is supported by another recently published study.
"Overall, we found no evidence of formal reasoning in the language models," Farajtabar concludes. "Their behavior is better explained by sophisticated pattern matching." Scaling data, parameters, and compute would lead to better pattern matchers, but "not necessarily better reasoners."

The study also questions the validity of LLM benchmarks. According to the researchers, the greatly improved results on the popular GSM8K math benchmark - GPT-3 scored 35 percent about three years ago and current models score up to 95 percent - could be due to the inclusion of test examples in the training data.
This idea is supported by a recent study showing that smaller AI models perform worse at generalizing mathematical tasks, possibly because they've seen less data during training.
Beyond pattern recognition
The Apple researchers stress that understanding the true reasoning capabilities of LLMs is crucial for their use in real-world scenarios where accuracy and consistency are essential - specifically in AI safety, alignment, education, healthcare, and decision-making systems.
"We believe further research is essential to develop AI models capable of formal reasoning, moving beyond pattern recognition to achieve more robust and generalizable problem-solving skills," the study concludes. This is a key challenge on the path to systems with human-like cognitive abilities or general intelligence.
AI researcher François Chollet describes the Apple study as "one more piece of evidence to add to the pile." The fact that LLMs are incapable of logic was an "extremely heretic viewpoint" in early 2023 - now it is becoming "self-evident conventional wisdom," Chollet says.
Debate in AI research
What's interesting about the study is that two leading AI research institutions, Apple and OpenAI, take opposing positions. OpenAI believes that o1 is the first reasoning model (level 2) that lays the foundation for logical agents (level 3), which is supposed to be the next growth area for OpenAI.
The Apple researchers' arguments are softened, for example, by a new OpenAI benchmark that shows o1 can solve machine learning engineering tasks. OpenAI claims to have explicitly excluded test examples from the training data. Another study concludes that AI models perform at least some kind of probabilistic reasoning.
One reason for these differences may be that terms such as intelligence, reasoning, and logic are vague, can occur in variations and degrees, or, in the case of machine logic, can take on new forms.
Ultimately, the academic discussion will fade into the background if future AI models can reliably solve the tasks they are given - and that's what OpenAI, with its valuation of more than $150 billion, needs to prove.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.