
Transformer models are everywhere - but why does a ChatGPT actually write what it writes? Aleph Alphas AtMan is supposed to enable explainability for large Transformer models.
Introduced by Google in 2017, the Transformer architecture has been triumphant in natural language machine processing and is now also being used successfully in computer vision and image generation. Variants of Transformers generate and analyze text, images, audio, or 3D data.
With the growing role of Transformer-based AI models in society at large, e.g. through ChatGPT or in critical application scenarios such as medicine, there is a great need for explainability - why did a model make this classification and not another, why did it generate this word and not another?
Aleph Alphas AtMan to enable efficient XAI for transformers
The technical term for this is "Explainable AI", or XAI for short. Such methods are intended to shed light on the black box of AI and already exist for all relevant architectures and are used, for example, in AI diagnostics - although a recent study has revealed major weaknesses in the saliency methods widely used there.
XAI methods also exist for transformers, but they usually capitulate due to too high computational requirements for the large models that are so relevant, or they only explain classifications of e.g. Vision Transformers. Text synthesis of language models remains a mystery to them.
Researchers from the German AI start-up Aleph Alpha, TU Darmstadt, the Hessian.AI research center, and the German Research Center for Artificial Intelligence (DFKI) demonstrate AtMan (Attention Manipulation), an efficient XAI method that works with large, even multimodal transformer models and can explain both classifications and generative output.
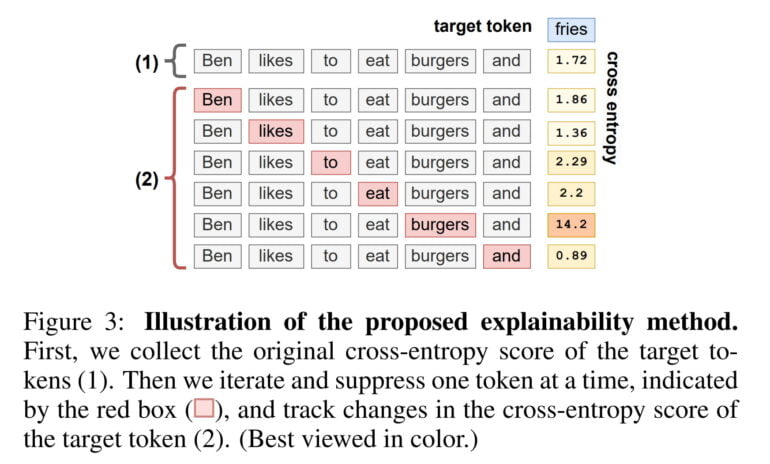
Aleph Alphas' method uses perturbations to measure how one token affects the generation of another token. For example, the sentence "Ben likes to eat burgers and" is continued by the word "fries" in the language model. Using AtMan, the team then calculates a value (cross-entropy) that roughly indicates how much the sentence as a whole determined the synthesis of "fries".
AtMan then suppresses one word at a time and compares how the value changes in each case. In our example, the value jumps up significantly as soon as the word "burger" is suppressed, and the XAI method has thus identified the word that most influenced the synthesis of "fries".
AtMan achieves SOTA in benchmarks
The researchers compare AtMan to other methods in the SQuAD QA benchmark, where their method outperforms alternatives such as IxG, IG, and Chefer, in some cases by a wide margin. Since AtMan performs perturbations in the embedding space at the token level, the method can easily be used in multimodal models such as Aleph Alphas MAGMA to explain classifications. Again, AtMan shows better performance in answering questions about images in the OpenImages VQA benchmark.


The team also explores how AtMan scales and concludes that their method is much better suited for use in large models. In one test, AtMan was able to process token lengths of up to 1,024 tokens in a Transformer model with up to 17.3 billion parameters on a single 80-gigabyte Nvidia A100 GPU, staying under 40 gigabytes of memory. The compared Chefer method exceeds the memory limit with more than twice the memory requirement.
AtMan can also be run in parallel, according to the team. Especially for large AI models, which run distributed on many GPUs anyway, this can significantly reduce AtMan's runtime.
How useful are explanations if no one understands them?
However, AtMan still has some limitations: "Whereas AtMan reduces the overall noise on the generated explanation, when compared to gradient-based methods, undesirable artifacts still remain. It is unclear to what extent this is due to the method or the underlying transformer architecture," the team writes. In addition, AtMan performs worse on the VQA benchmark with a MAGMA model scaled to 30 billion parameters than with the 6-billion-parameter variant.
This could be due to the increasing complexity of the model and thus the complexity of the explanation at hand, the paper says. "Hence, it is not expected that the 'human' alignment
with the model’s explanations scales with their size" - a phenomenon that could also occur with large language models. Consequently, scaling explainability with model size should be further studied, the team concludes.


