Chinese researchers collected data from Internet comments to train ERNIE-Music, a generative text-to-waveform model.
Generating music from text is still a major challenge. There are several reasons for this, but a major one is the lack of a critical mass of training data. To develop such a text-music model, one needs not only the music itself but more importantly, a labeling of the corresponding data in text form.
Some methods try to get around this problem, such as Riffusion, which uses Stable Diffusion to directly generate images of music in waveform and then convert them into audible snippets.
Researchers at the Chinese Internet company Baidu now present a possible solution to the data shortage and the generative text-to-waveform model ERNIE-Music.
Do positive ratings equal good training data?
According to the team, ERNIE-Music is the first AI model to generate music in waveform from free text. Baidu collects the necessary data from Chinese music platforms - the paper does not specify which ones.
In total, the team collected 3,890 text-music pairs. The texts come from popular comments on the music platforms and usually describe characteristics of the 20-second tracks, according to the researchers.
"By our observation, the 'popular comments' are generally relatively high quality and usually contain much useful music-related information such as musical instruments, genres, and expressed human moods.," the paper states.

Baidu uses the data to train the ERNIE music diffusion model to synthesize waveforms from text descriptions. The resulting music has a wide variety of melodies and emotions, as well as instruments such as piano, violin, erhu, and guitar.
To evaluate ERNIE-Music, the team relies on human feedback from ten people who compare music generated by ERNIE-Music with other models such as Mubert, Text-to-Symbolic Music, and Musika. The Chinese team's model performs best on these benchmarks.

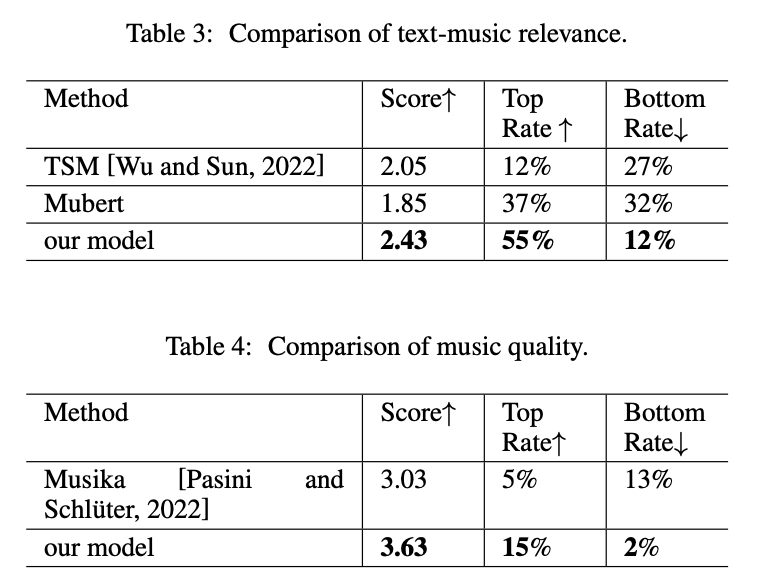
Baidu is also investigating whether the free-form text training performed for ERNIE-Music produces better results than training with relevant keywords extracted from the text, such as "piano, violin, gentle, melancholic". In fact, the researchers were able to show that the text format chosen for training has an effect and that the model trained with free-form text performs significantly better in comparison.
The results show that our free-form text-based conditional generation model creates diverse and coherent music and outperforms related works in music quality and text-music relevance.
From the paper
Is the "DALL-E for music" coming now?
So how should we classify the findings of Baidu's researchers? Are we one step closer to a "DALL-E for music"? Unfortunately, the team did not provide any audio samples or source code, so an independent evaluation is still pending. But Baidu's approach bets on end-to-end training with multimodal data pairs, which has been extremely successful in image synthesis and also offers a comparatively simple solution for collecting them for music.
However, the amount of data collected here is tiny compared to what is needed, and it remains to be seen whether the method can be scaled to more music and other languages. Such scaling is also likely to lead to similar copyright discussions as with image models - except that musicians have a much larger lobby through their labels.