Researchers create music from text via a Stable Diffusion detour.
Despite the significant impact that generative AI models have had on the text and image industries, the music industry has yet to see such a drastic transformation.
However, there are still examples of the use of generative AI models in audio, such as Riffusion, an AI generator developed by entrepreneur Seth Forsgren and engineer Hayk Martiros. Based on the open-source Stable Diffusion model, originally designed for images, Riffusion demonstrates the potential for AI to shape the future of music creation.
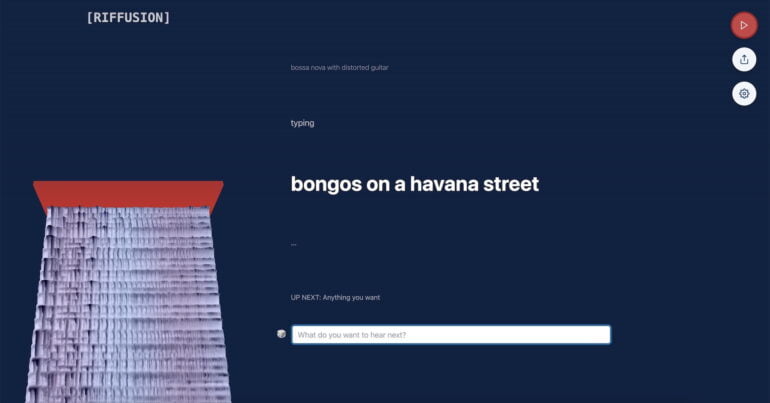
Stable Diffusion generates spectrograms, which then become music
Riffusion offers a straightforward approach to music generation through the use of Stable Diffusion v1.5, which generates images of sound waves, which are then converted into music. The model is merely fine-tuned with images of spectrograms, rather than retrained, the developers write.
A spectrogram is a visual representation of the content of a sound section. The x-axis represents time, the y-axis represents frequency. The color of each pixel indicates the amplitude of the sound at that point.
Video: Riffusion
Riffusion can create infinite variations of a prompt by varying the seed. All techniques known from Stable Diffusion like img2img, inpainting or negative prompts are ready to use.
When providing prompts, get creative! Try your favorite styles, instruments like saxophone or violin, modifiers like arabic or jamaican, genres like jazz or rock, sounds like church bells or rain, or any combination. Many words that are not present in the training data still work because the text encoder can associate words with similar semantics.
The closer a prompt is in spirit to the seed image And BPM, the better the results. For example, a prompt for a genre that is much faster BPM than the seed image will result in poor, generic audio.
Riffusion
Try Riffusion for free
You can try Riffusion directly on the official website without registration. Settings are limited to five different seed images, which affect melodic patterns, and four levels of denoising. The higher you choose the denoising factor, the more creative the result will be, but the less it will hit the beat.

Riffusion Demo - Prompt: "A robotic skull with a neural net half seen in the brain and a violin on the shoulder".
Riffusion allows users to share their generated beats with others through a link or download a five-second excerpt in MP3 format for further processing in audio software. Generated user sounds can also be found on the Riffusion subreddit.
Additionally, users can create their own custom Riffusion models trained on specific artists or bands, such as the band Rammstein (with sound examples available). While the generated sound may not be of the highest quality, the distinctive style of the chosen band is clear. A tutorial on how to create these custom models can be found on Reddit.