Black Forest Labs' FLUX.1 merges text-to-image generation with image editing in one model

With FLUX.1 Kontext, Black Forest Labs extends text-to-image systems to support both image generation and editing. The model enables fast, Kontext-aware manipulation using a mix of text and image prompts, while preserving consistent styles and characters across multiple images.
Unlike earlier models, FLUX.1 Kontext lets users combine text and images as prompts to edit existing images, generate new scenes in the style of a reference image, or maintain character consistency across different outputs. A key feature is local image editing, where individual elements can be modified without altering the rest of the image. Style cues can also be provided via text to create scenes that match the look of a given reference.
One model for editing, generation and style transfer
FLUX.1 Kontext [pro] combines traditional text-to-image generation with step-by-step image editing. It handles both text and image prompts and, according to Black Forest Labs, runs up to ten times faster than comparable models. The system is designed to preserve the consistency of characters, styles, and objects across multiple edits—something current tools like GPT-Image-1 or Midjourney often struggle with.

An experimental version, FLUX.1 Kontext [max], targets users who need greater typographic precision, more reliable editing, and faster inference. The goal is to maximize prompt accuracy while delivering high performance.
To measure performance, Black Forest Labs ran its own tests using an in-house benchmark called KontextBench. The company reports that FLUX.1 Kontext [pro] led the field, especially in text editing and character retention. It also beat other current models in speed and in sticking to the user's prompt.
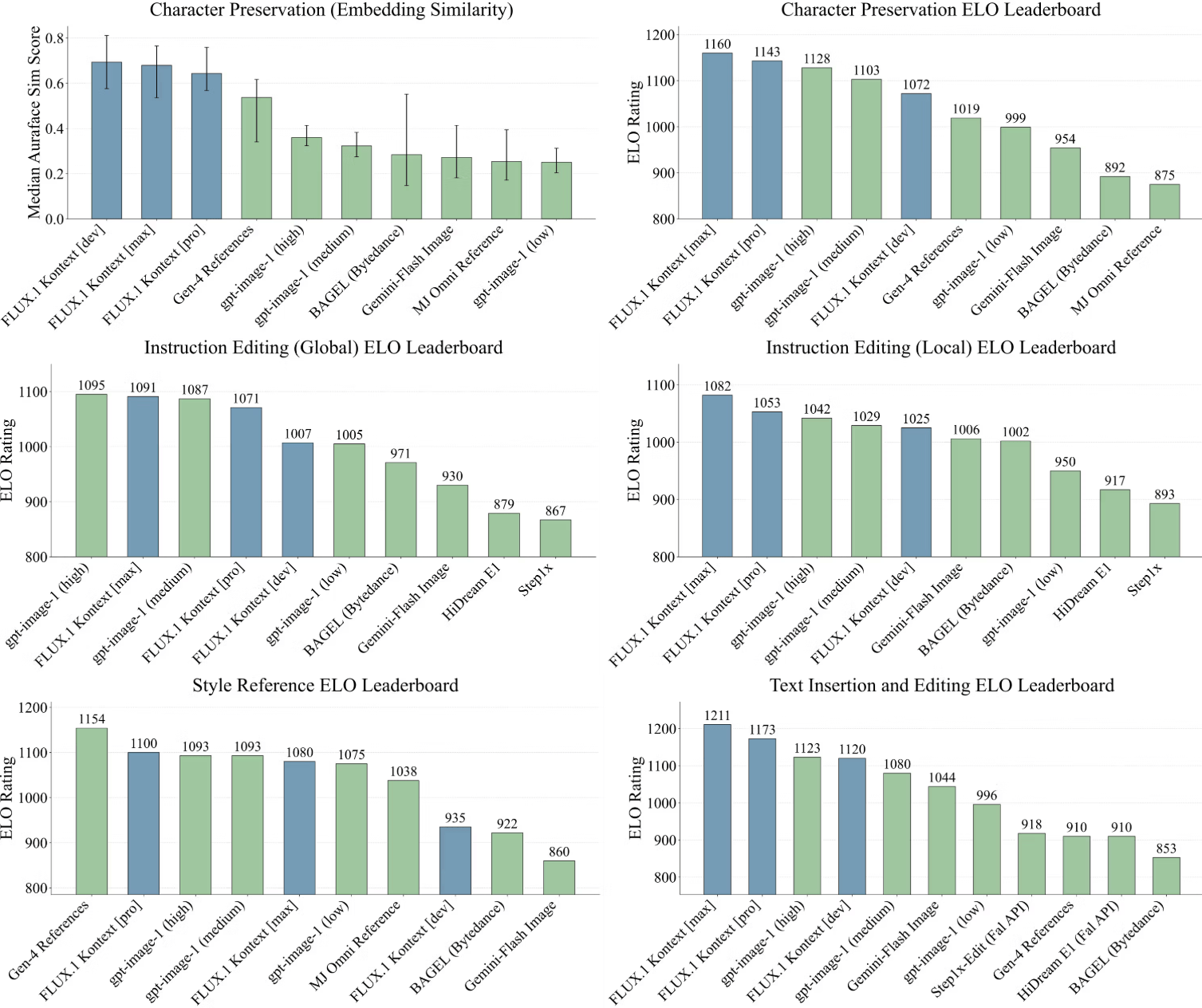
There are still some trade-offs, the company says: The model can introduce visible artifacts during longer editing chains, and sometimes fails to follow prompts accurately. Its limited world knowledge can also affect its ability to generate Kontextually accurate images.
Open version for research and new interfaces for testing
For research, BFL offers a smaller model called FLUX.1 Kontext [dev]. With 12 billion parameters, it's intended for security testing and custom adaptations, and will be available through a private beta. Once released publicly, it will be distributed via partners such as Hugging Face.
BFL has also launched the "FLUX Playground," a web interface for testing the models in real time without any technical setup. It lets users explore capabilities, experiment with prompts, and validate use cases on the fly.
FLUX.1 Kontext models are also available through platforms like KreaAI, Freepik, Lightricks, OpenArt, and LeonardoAI, as well as infrastructure providers including FAL, Replicate, and DataCrunch.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.