ByteDance's new AI model brings still images to life with audio
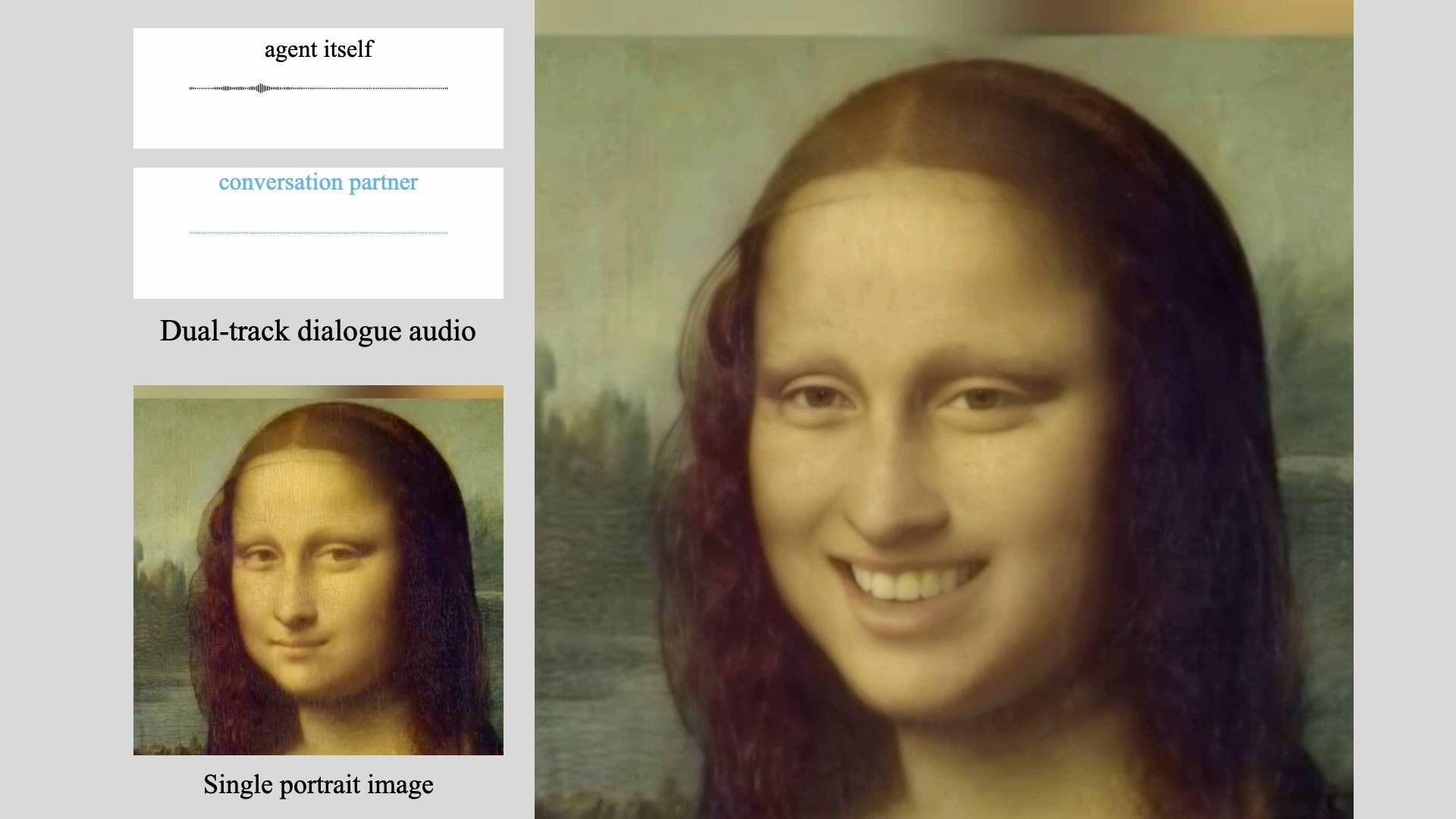
TikTok's parent company ByteDance has developed an AI system called INFP that can make static portrait photos appear to speak and react to audio input.
What sets INFP (which stands for "Interactive, Natural, Flash and Person-generic") apart is its ability to create realistic conversation videos between two people without needing anyone to manually assign speaking and listening roles. The system figures out these roles automatically as the conversation flows.
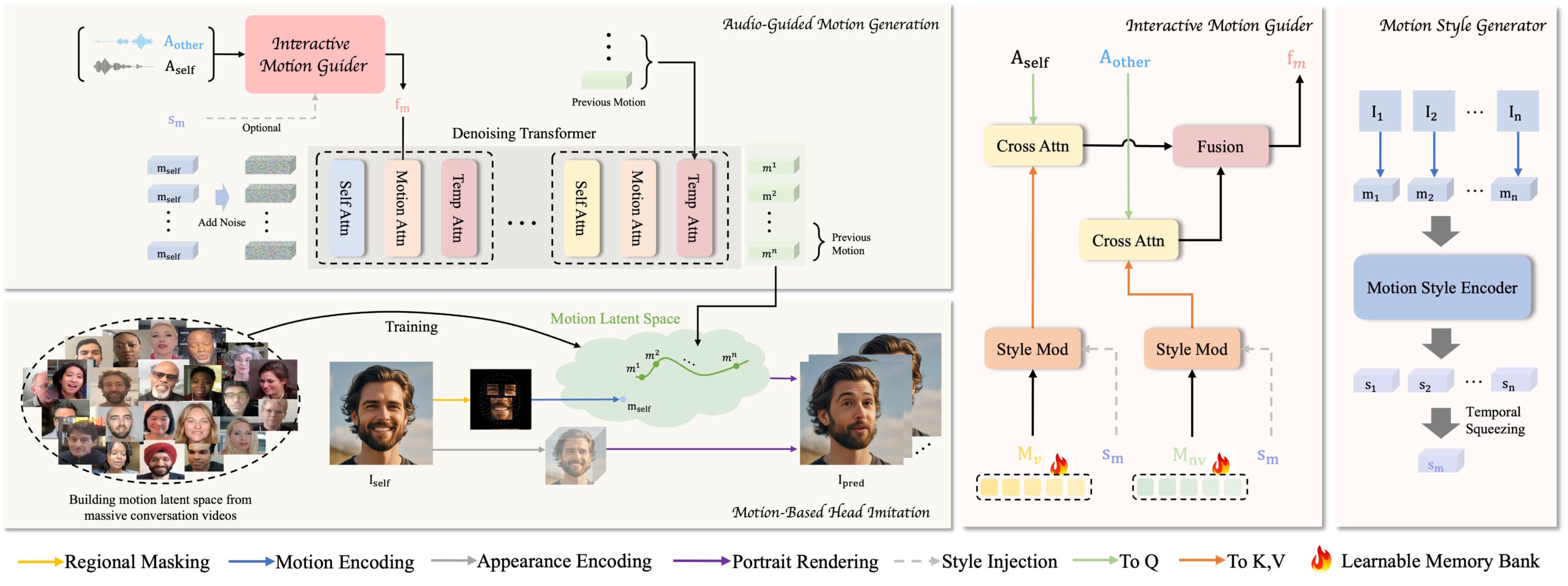
The system works in two main steps. In the first step, which ByteDance calls "Motion-Based Head Imitation," the AI learns to pick up on all the little details of how people communicate - things like facial expressions and the way they move their heads during conversations. It takes these movements from videos and turns them into data that it can use later. This motion data can then animate a still photo to match the original person's movements.
In the second stage, "audio-guided motion generation," the system figures out how to match sounds with natural-looking movements. The team developed what they call a "motion guider" that creates patterns for both speaking and listening by analyzing the audio from both sides of a conversation. Then, a special AI component called a diffusion transformer takes these patterns and gradually refines them into smooth, realistic movements that match the audio.
Teaching AI how real conversations work
To train their system properly, the team had to build something new: a collection of real-world conversations they called DyConv. They gathered over 200 hours of people talking to each other from videos across the internet.
While there are other conversation databases out there, like ViCo and RealTalk, the team says DyConv offers something special - it captures a wider range of human emotions and expressions, and the video quality is notably better.
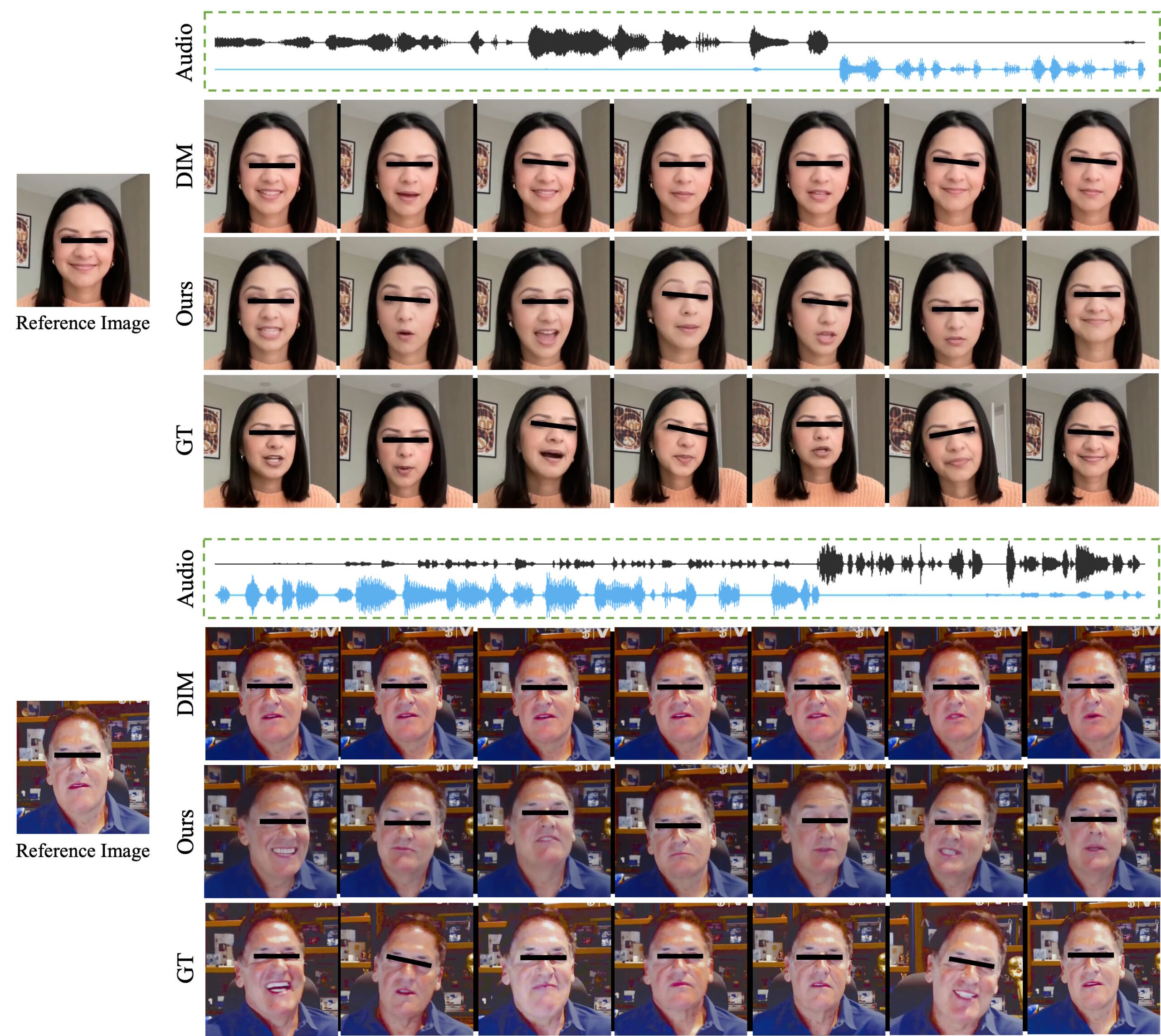
ByteDance says its system outperforms existing tools in several key areas. INFP is particularly good at matching lip movements to speech, preserving the person's unique facial features, and creating a wide variety of natural-looking movements. The team also found that it works well for creating videos of someone just listening to a conversation.
What's next for INFP
Currently, INFP only works with audio, but the team sees many ways to expand its capabilities. They're exploring how to make the system work with images and text, which would open up all kinds of new possibilities. Their next goal is to create realistic animations of people's entire bodies, not just their heads and facial expressions.
The researchers know this kind of technology could be misused to create fake videos and spread false information. That's why they're planning to keep the core technology limited to research institutions - much like Microsoft did last summer with their advanced voice cloning system.
This work is just one piece of ByteDance's bigger AI strategy, which they announced earlier this year. With popular apps like TikTok and CapCut in their portfolio, the company has a massive platform for putting these AI innovations to use.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.