Can self-supervised learning explain human language learning? A new study compares the Wav2Vec algorithm with fMRI recordings.
Self-supervised trained AI models are approaching or have already achieved human performance in areas such as object recognition, translation, and speech recognition. Several studies also show that at least individual representations of these algorithms correlate with those of human brains.
For example, the neural activity of the middle layers of GPT models can be mapped to the brain during the consumption of text or spoken language. In doing so, activity from a deeper layer of the neural network can be transformed into synthetic fMRI (functional magnetic resonance imaging) images and compared to real images of humans.
In one paper, researchers at Meta showed that they could predict brain responses to language based on activations of GPT-2 in response to the same stories. "The more subjects understand the stories, the better GPT-2 predicts their brain activity," said Jean-Remi King, CNRS researcher at Ecole Normale Supérieure and AI researcher at Meta.
GPT models can't explain language acquisition
However, models like GPT-2 differ significantly from the brain in several ways. For example, they require huge amounts of data for training and rely on text rather than raw sensor data. To read the 40 gigabytes of pure text used to train GPT-2, most people would need several lifetimes.
The models are therefore of limited use in learning more about the human brain - a stated goal of King's research team at Meta. Insights gained in this way should also enable better artificial intelligence.
Efforts are currently focused on the fundamentals of language acquisition: “Humans and kids, in particular, acquire language extremely efficiently. They learn to do this rapidly and with an extremely small amount of data. This requires a skill which at the moment remains unknown,” says King.
In a new research paper, King and his team are now investigating whether the Wav2Vec algorithm can shed light on this special human ability.
Wav2Vec is trained with 600 hours of audio
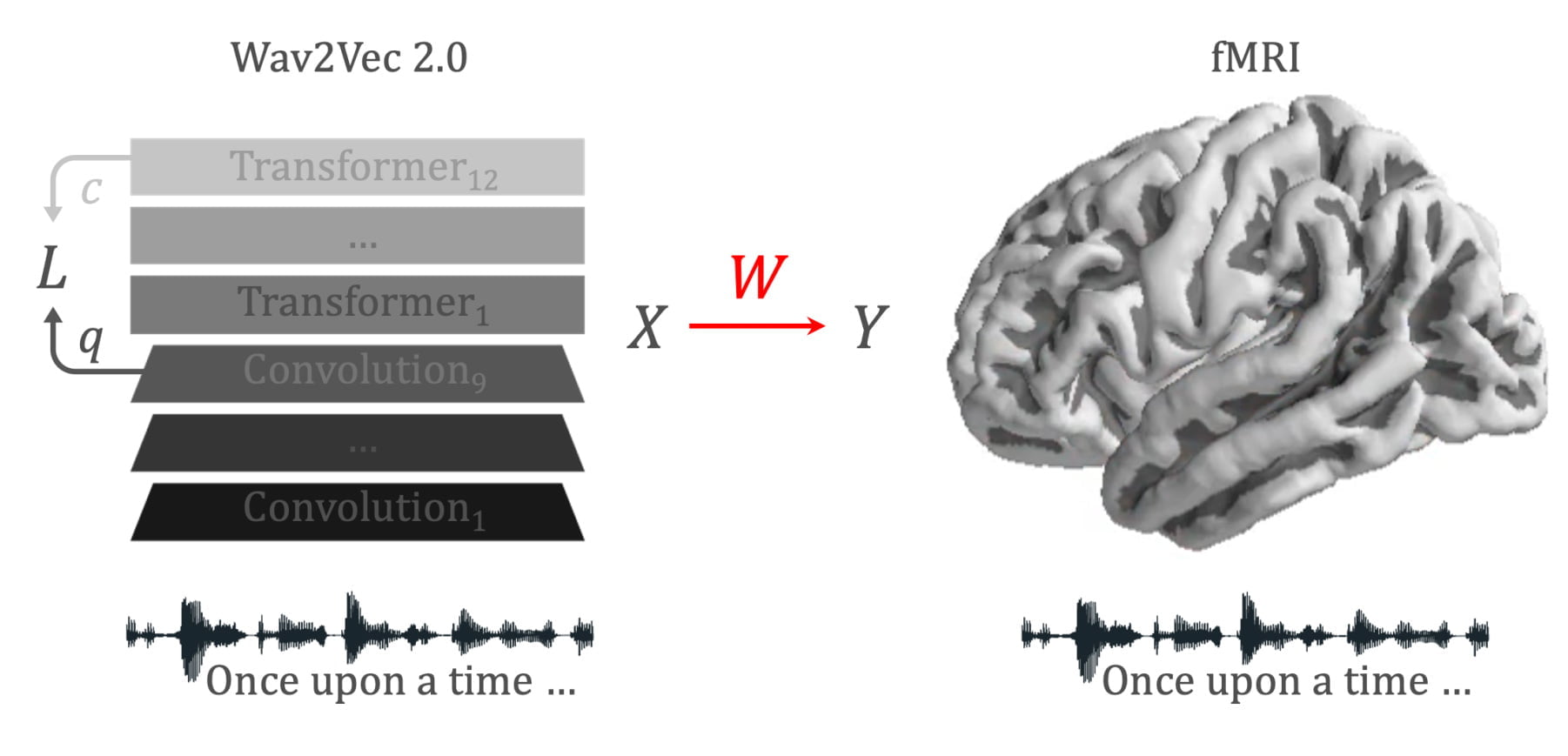
Wav2Vec 2.0 is a hybrid transformer model with convolutional layers that is trained in a self-supervised fashion with audio data, learning a latent representation of the waveforms of the speech recordings. Meta uses the system and its predecessor Wav2Vec for self-supervised learned speech recognition, translation or speech generation.

In Meta's new work, King and his team compare a Wav2Vec model trained with 600 hours of speech recordings to fMRI recordings of 417 people listening to audiobooks. The 600 hours roughly correspond to the amount of spoken language infants hear during early language acquisition, according to the researchers.
?Preprint out:
`Toward a realistic model of speech processing in the brain with self-supervised learning':https://t.co/rJH6t6H6sm
by J. Millet*, @c_caucheteux* and our wonderful team:
The 3 main results summarized below ? pic.twitter.com/mdrJpbrb3M
- Jean-Rémi King (@JeanRemiKing) June 6, 2022
The experiment showed that self-supervised learning is sufficient for an AI algorithm like Wav2Vec to learn brain-like representations, King said. In the study, the researchers show that most brain areas correlate significantly with the algorithm's activations in response to the same language input.
Moreover, the hierarchy learned by the algorithm corresponds to that of the brain. For example, the auditory cortex is best tuned to the first transformer layer, while the prefrontal cortex is best tuned to the deepest layers.
AI research is on the right track
Using fMRI data from an additional 386 subjects who had to distinguish non-language sounds from speech in a foreign language and in their own language, the researchers also show that the auditory, linguistic, and language-specific representations learned by the model correlate with those of the human brain.
Modeling human-level intelligence is still a distant goal, King said. But the emergence of brain-like functions in self-supervised algorithms, he says, suggests that AI research is on the right track.
King is likely addressing critics of the deep learning paradigm. Recently, for example, Gary Marcus criticized the debate initiated by Deepmind's multitalented Gato about the role of scaling on the way to human-level artificial intelligence.
Marcus called this "Scaling-Uber-Alles" approach hubris and part of an "alt intelligence" research: "Alt Intelligence isn’t about building machines that solve problems in ways that have to do with human intelligence. It’s about using massive amounts of data – often derived from human behavior – as a substitute for intelligence."




