
A complex prompt from cloud marketing company Salesforce aims to improve the quality of article summaries using GPT-4.
The Chain of Density prompt first asks GPT-4 to create a first draft of a summary with as few elements as possible. In the next steps, the prompt asks GPT-4 to revise this summary and add more details.
As with chain-of-thought prompting, the model then uses the first generated output as a template for the next generation. The more often the model goes through this process, the greater the information density in the summary for the same character length.
"Summaries generated by CoD are more abstractive, exhibit more fusion, and have less of a lead bias than GPT-4 summaries generated by a vanilla prompt," the team writes.
Article: {{article}
You will generate increasingly concise entity-dense summaries of the above article. Repeat the following 2 steps 5 times.
Step 1: Identify 1-3 informative entities (delimited) from the article which are missing from the previously generated summary.
Step 2: Write a new denser summary of identical length which covers every entity and detail from the previous summary plus the missing entities.
A missing entity is
- Relevant: to the main stories.
- Specific: descriptive yet concise (5 words or fewer).
- Novel: not in the previous summary.
- Faithful: present in the article.
- Anywhere: located in the article.
Guidelines:
- The first summary should be long (4-5 sentences, ~80 words), yet highly non-specific, containing little information beyond the entities marked as missing. Use overly verbose language and fillers (e.g., "this article discusses") to reach ~80 words.
- Make every word count. Rewrite the previous summary to improve flow and make space for additional entities.
- Make space with fusion, compression, and removal of uninformative phrases like "the article discusses".
- The summaries should become highly dense and concise, yet self-contained, e.g., easily understood without the article.
- Missing entities can appear anywhere in the new summary.
- Never drop entities from the previous summary. If space cannot be made, add fewer new entities.
Remember: Use the exact same number of words for each summary.

Answer in JSON. The JSON should be a list (length 5) of dictionaries whose keys are "missing_entities" and "denser_summary".

The complexity of summaries
The research team tested the prompt on 100 news articles from CNN and DailyMail. Human reviewers, in this case four of the article's authors, rated the summaries highest after about three passes.
On average, GPT-4 rated the summaries highest in the dimensions of information, quality, coherence, attribution, and "overall" after two passes. The CoD method is said to be superior to a simpler prompt tested ("Write a VERY short summary of the article. Do not exceed 70 words.").
"We find that a degree of densification is preferred, yet, when summaries contain too many entities per token, it is very difficult maintain readability and coherence," the team writes.
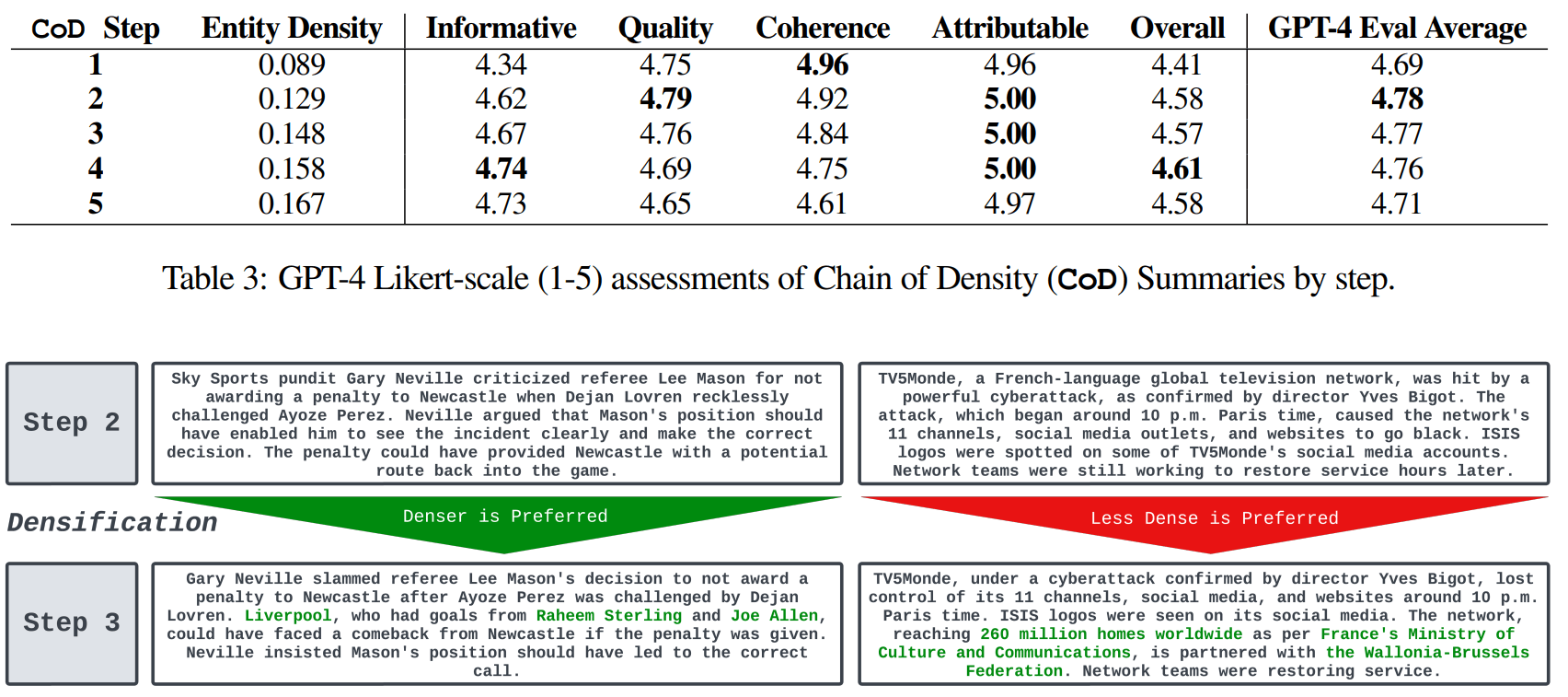
In general, the first and last steps score the worst, with the three middle summaries close together. That the first summary scores lower makes sense, considering that the prompt asks the model to write a superficial summary first.
The fact that the results are so close also shows how difficult it is to evaluate texts above a certain level. This, in turn, makes it difficult to measure the impact of prompt engineering.
The research team publishes a dataset of 500 annotated and 5000 unannotated CoD summaries alongside the prompt.


