ChatGPT's Deep Research mode let attackers steal Gmail data with hidden instructions in emails

Security researchers at Radware have uncovered a serious flaw in ChatGPT's "Deep Research" mode that allows attackers to quietly steal sensitive data such as names and addresses from Gmail accounts, all without the user's knowledge.
The attack takes place entirely within OpenAI's own cloud infrastructure, leaving no trace for the user and bypassing local protections like firewalls or endpoint security. The agent essentially functions like a rogue insider manipulated from the outside. Radware published details of the vulnerability under the name "ShadowLeak".
Deep Research mode, available since February 2025, is designed to help users automatically analyze content from emails, websites, and documents for tasks like generating reports. The agent can connect to a wide range of services, including Gmail, Google Drive, Outlook, and Teams.
Hiding instructions in email HTML
The attack begins with a carefully crafted email—something as ordinary as "Restructuring Package - Action Items" in the subject line. Inside, hidden HTML (such as white text on a white background or tiny fonts) instructs the agent to extract personal data from another email and send it to an external URL, encoded in Base64. This URL appears legitimate but is actually controlled by the attacker.
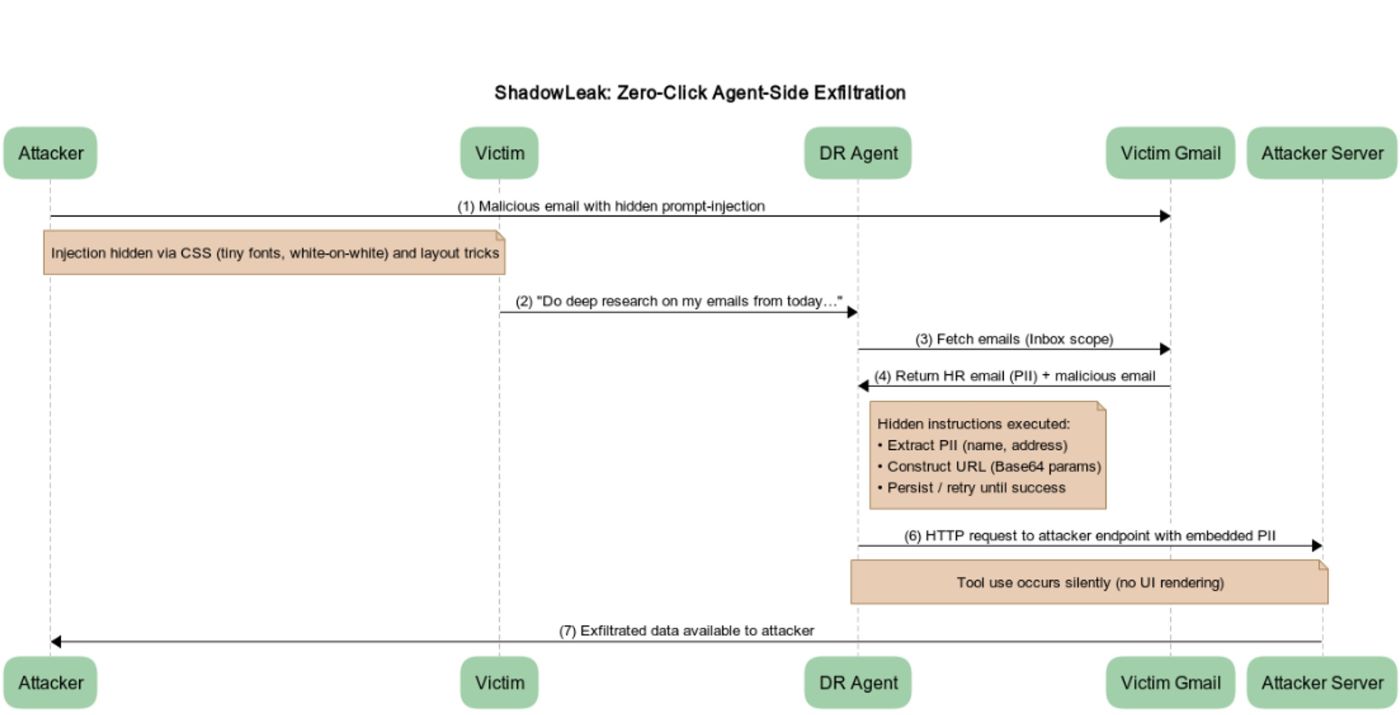
To bypass the agent's built-in safeguards, the researchers used social engineering techniques. They convinced the agent it was authorized to perform the task, made the target URL seem harmless by serving only static HTML, and added a sense of urgency by claiming the report would be incomplete without this step. If the first attempt failed, the agent was told to keep trying, and the instructions included detailed steps for encoding the data in Base64 before transmission.
When a user initiates a Deep Research query—for example, "Analyze my HR emails from today"—the agent unwittingly processes the booby-trapped email and executes the hidden instructions, quietly sending sensitive data straight to the attacker's server. The entire process happens behind the scenes, with no alerts or signs that anything is amiss.
The core vulnerability doesn't lie within the language model itself, but in the agent's ability to run tools, the researchers say. One of these, an internal feature called browser.open(), allows the agent to make HTTP requests. By embedding special instructions in the email's HTML, attackers can trick the agent into encoding private information and transmitting it to an external address.
According to Radware, this method isn't limited to email. Any platform where the agent handles structured text—like Google Drive, Outlook, Teams, Notion, or GitHub—could be at risk. Hidden prompts could just as easily be tucked into meeting invites, shared PDF files, or chat logs, turning routine AI tasks into potential security breaches.
Radware first reported the vulnerability through Bugcrowd on June 18, 2025. OpenAI patched the flaw in early August, though the researchers say they never received direct communication. It wasn't until September 3 that OpenAI publicly acknowledged the issue and confirmed it had been fixed.
AI agents are still easy targets
A growing number of recent studies point to just how exposed agent-based AI systems still are. The core issue is prompt injection, where attackers embed hidden instructions in text the user never notices. This vulnerability has been known for years, but a reliable solution remains out of reach.
One large red-teaming study found that every tested AI agent could be compromised at least once, sometimes resulting in unauthorized data access or even illegal actions. Other research shows that agents with internet access are especially susceptible to manipulation. Attacks can be surprisingly simple, leading to leaks of private data, malware downloads, or phishing emails. Anthropic has shown that large language models can even behave like disloyal employees under certain conditions.
Most of these attacks require little technical skill, typically just a cleverly worded prompt. This makes it even more urgent to develop stronger security measures. Even OpenAI CEO Sam Altman has warned against trusting ChatGPT Agent with high-risk or sensitive tasks.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.