Chinese AI lab Zhipu releases GLM-5 under MIT license, claims parity with top Western models
Key Points
- Zhipu AI has released GLM-5, an open-source model with 744 billion parameters under an MIT license. The company claims it matches Claude Opus 4.5 and GPT-5.2 on coding and agent tasks.
- Beyond Nvidia GPUs, the model also runs on Chinese chips from Huawei and other domestic manufacturers, a significant advantage given current US export restrictions on advanced AI hardware.
- Competition among Chinese AI labs is heating up: Moonshot AI's Kimi K2.5 takes a different approach with swarms of agents working in parallel, while Deepseek-V3.2 falls behind both GLM-5 and Kimi K2.5 across several benchmarks.
Chinese AI company Zhipu AI dropped GLM-5, an open-source model with 744 billion parameters that goes toe-to-toe with Claude Opus 4.5 and GPT-5.2 on coding and agent tasks.
GLM-5 packs 744 billion parameters, with 40 billion active at any given time. Its Mixture-of-Experts architecture is nearly twice the size of its predecessor, GLM-4.5, which had 355 billion parameters. Training data jumped significantly too, from 23 to 28.5 trillion tokens. According to Z.ai, the model uses Deepseek Sparse Attention (DSA) to cut deployment costs without losing performance on long contexts.
Zhipu AI's pitch is that foundation models need to move beyond chat and start doing real work. GLM-5 is designed to build complex systems and plan long-term - the same direction Anthropic, Google, and OpenAI are pushing their latest models. The model weights are available under the MIT license, one of the most permissive open-source licenses out there.
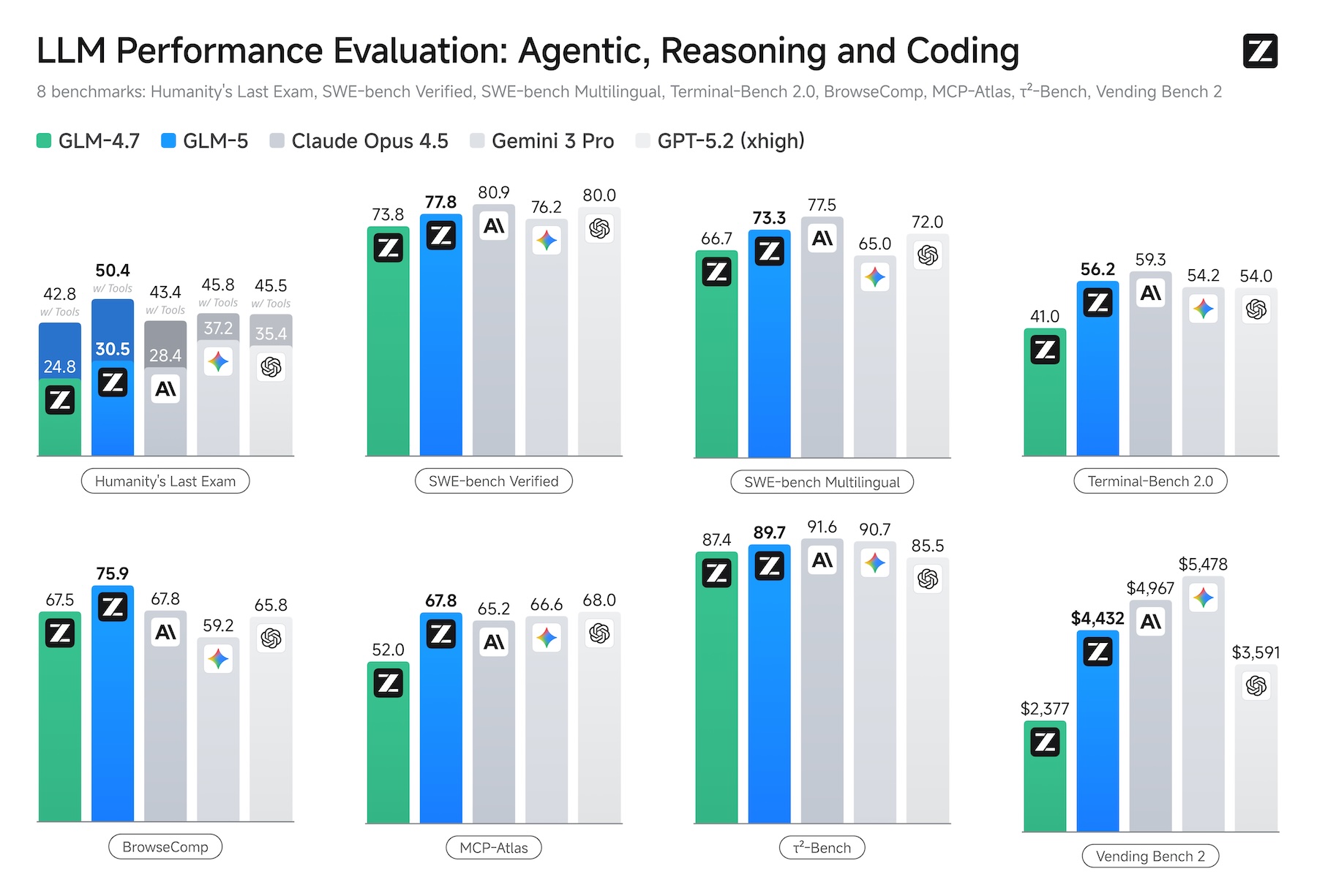
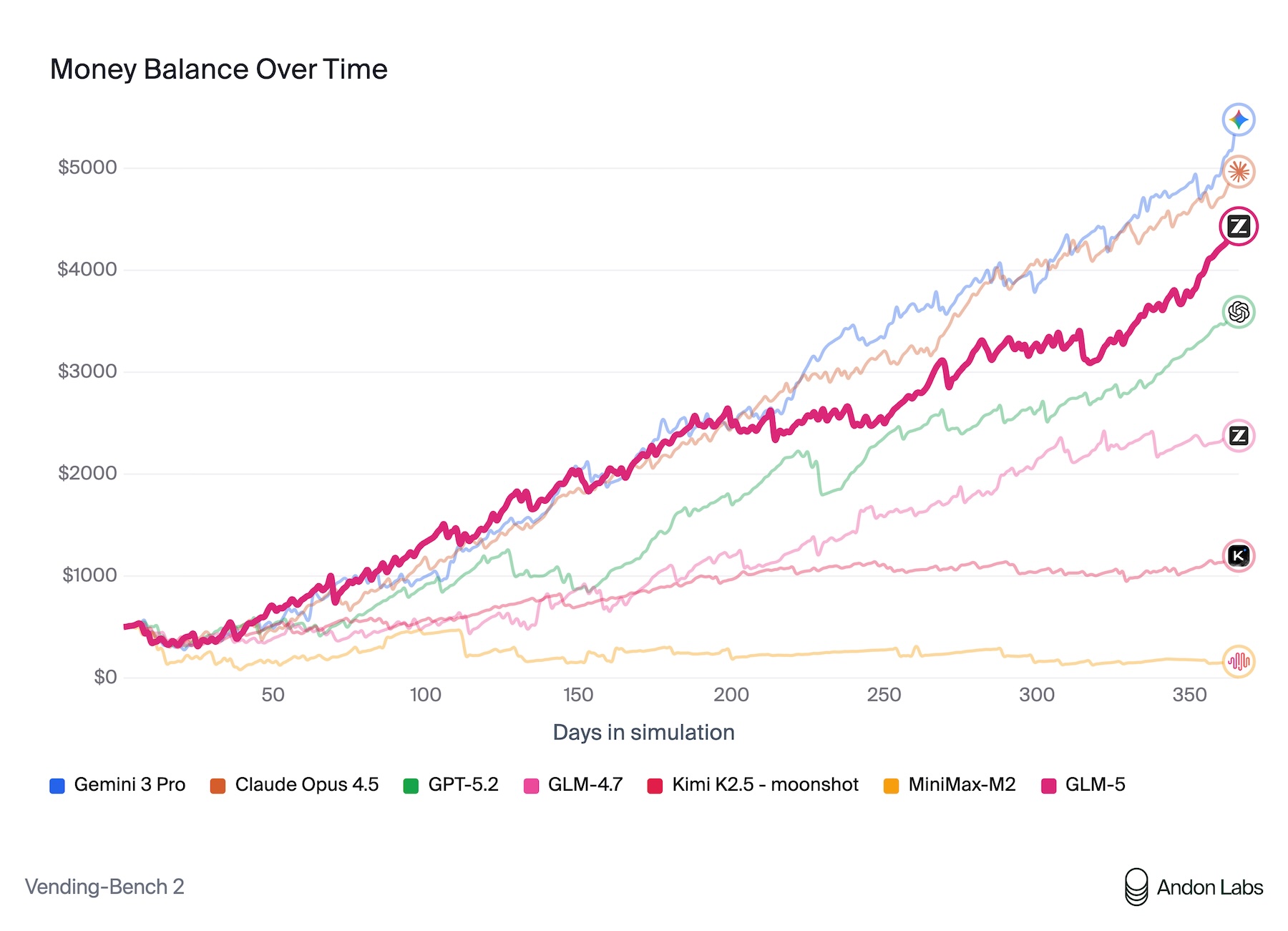
According to Zhipu AI, GLM-5 tops every open-source model in the company's published benchmarks for reasoning, coding, and agent tasks. One particularly telling test is Vending Bench 2, where a model has to run a simulated vending machine business for an entire year.
GLM-5 finished with $4,432 in its account, putting it within striking distance of Claude Opus 4.5 at $4,967. Andon Labs ran the benchmark, the same group that helped Anthropic with "Project Vend," the real-world experiment where Claude Sonnet 3.7 tried to run an actual self-service store and lost money.
On SWE-bench Verified, GLM-5 hits 77.8 percent, beating Deepseek-V3.2 and Kimi K2.5 but still short of Claude Opus 4.5's 80.9 percent. Zhipu AI also claims GLM-5 beats all tested proprietary models on BrowseComp, which measures agent-based web search and context management, though no independent testing has confirmed that yet.
As always, benchmark scores don't necessarily translate to real-world performance. This gap tends to be even wider with open-source models, where strong test results sometimes mask weaker day-to-day usability compared to proprietary alternatives.
Still, the speed of the release is noteworthy. A Stanford analysis found Chinese AI models typically run about seven months behind their US counterparts. GLM-5 landed roughly three months after the latest flagships from Anthropic, Google, and OpenAI, cutting that gap in half.
Document generation turns prompts into files
Zhipu AI says GLM-5 can take text and other sources and turn them directly into polished .docx, .pdf, and .xlsx files. The official Z.ai app includes an agent mode with built-in document creation skills for things like sponsorship proposals and financial reports.
The model also works with OpenClaw, a new and controversial framework for cross-app and cross-device workflows, plus popular coding agents like Claude Code, OpenCode, and Roo Code.
GLM-5 runs on Nvidia GPUs but also on chips from Huawei Ascend, Moore Threads, Cambricon, and other Chinese manufacturers. Zhipu AI says kernel optimization and model quantization make "reasonable throughput" possible on these alternative chips.
That matters a lot in China, where US export restrictions have made Nvidia hardware hard to come by. For local deployment, GLM-5 supports the vLLM and SGLang inference frameworks, with setup instructions available in the GitHub repository.
Zhipu AI also open-sourced slime, the reinforcement learning framework it used to retrain GLM-5. The core problem slime tackles: applying reinforcement learning to large language models is still painfully slow. Slime uses an asynchronous architecture that pairs the Megatron training framework with the SGLang inference engine. It supports Qwen3, Deepseek V3, and Llama 3 in addition to Zhipu's own models.
Chinese AI labs keep raising the bar for each other
Zhipu AI recently shipped GLM-4.7, GLM-5's direct predecessor, which introduced a "Preserved Thinking" feature that carries thought processes across long dialogs. GLM-5 pushes that model's SWE-bench score from 73.8 to 77.8 percent.
At the same time, Chinese rival Moonshot AI released Kimi K2.5, which can coordinate up to 100 sub-agents working in parallel through "Agent Swarms" and also posts top scores on agent benchmarks. Both models use Mixture-of-Experts architectures and are chasing the same prize: autonomous AI agents that can plan and execute over long time horizons.
One clear trend across the latest GLM-5 and Kimi K2.5 benchmarks: Deepseek is losing ground. Deepseek-V3.2 trails both models by a clear margin on several agent and coding tests. According to the South China Morning Post, Deepseek's next big model—a one-trillion-parameter system—has been delayed because of the growing model size.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now