
A new generative AI system generates 3D models from a text description. The models can be used directly in common graphics engines.
Generative AI models such as OpenAI's DALL-E 2, Midjourney or Stable Diffusion produce impressive images of almost any style. The only input required is a text prompt that describes the desired result. The AI graphics tools speed up existing work processes, but can also create almost complete works of art.
The technology could therefore be an early example of AI's impact on the job market, says OpenAI founder Sam Altman. As the case of Jason Allen shows, whose AI artwork won an art competition, it is already causing trouble among artists and designers.
Outside the realm of 2D art and design, a small group of researchers is working on a new class of generative AI systems that have great potential to revolutionize an entire industry: generative AI systems for 3D models.
In late 2021, Google showed Dream Fields, an AI model for generating 3D rendering. Dream Fields combines OpenAI's CLIP with a NeRF generator, that can produce simple NeRFs based on text descriptions.

Google's method, however, takes over a day per NeRF and is computationally intensive. Furthermore, NeRFs cannot be directly transformed into 3D mesh models. Such mesh models form the basis of the representation of almost all current 3D objects, for example in video games or simulations.
CLIP-Mesh directly generates 3D mesh models
In a new research paper from Concordia University, Canada, researchers now demonstrate CLIP-Mesh, a generative AI model that directly generates 3D mesh models with textures and normal maps from text descriptions.
The team renders different views of a simple model, such as a sphere. This sphere is created by a renderer from texture map, normal map, and vertices of the mesh.
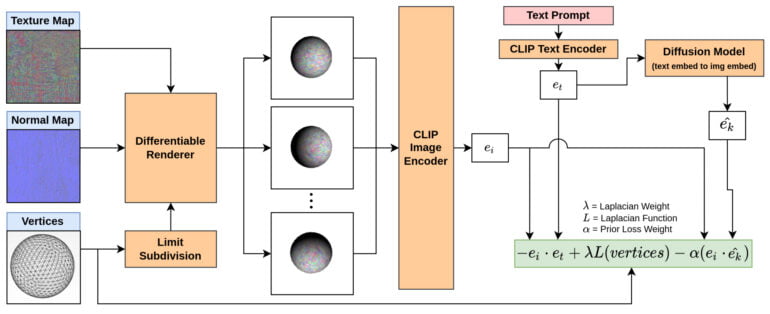
The images are encoded by a CLIP image encoder and compared with the text input encoded by CLIP text encoder. In addition, this encoded text input is transformed into an image embedding by a diffusion model, which output is also used for a loss function.

CLIP-Mesh then adjusts the texture map, normal map, and vertices of the mesh model fed to the renderer according to feedback from the text encoder and diffusion model.

In initial experiments, the team uses a sphere with 600 vertices and a texture and normal map resolution of 512 by 512 pixels. With this data, CLIP-Mesh generates a 3D model in 50 minutes on an Nvidia P100 with 16 gigabytes of graphics memory. The shape of possible models is constrained by the original vertices - overly variable shapes cannot emerge from a sphere, the researchers say.
Generative AIs for 3D models are only a matter of time
In a short video, the team shows a small room complete with generated 3D models. The results are clearly recognizable as objects and can be easily used in an engine that processes 3D meshes. CLIP-Mesh textures the models to match.
Video: Khalid et al.
CLIP-Mesh can also be used to edit multiple objects. For example, a surface can be textured and at the same time, a model standing on it can be completely changed.

Theoretically, CLIP-Mesh can already be used in many ways - even if the 3D mesh models produced are far from the quality of manual 3D modeling.
One potentially big advantage: the research team did not need its own 3D database for the model, thanks to the use of CLIP. Potentially, this could lead to new generative AI systems for 3D models that use the comprehensive datasets for image systems and do not require additional data. The researchers now want to investigate the extent to which this approach will bear fruit in the future.
If generative AI models for 3D objects show a similar development speed as 2D systems, companies specializing in this field, such as OpenAI, could present models as early as next year that will stir up a lot of dust in another job market: 3D programming and design.


