Deepmind shows how AI can deal with uncertainty

Uncertainty is a constant companion for humans and animals. Those who can handle it better have an advantage. This also applies to artificial intelligence, as Deepmind shows.
Biological creatures are constantly exposed to uncertainty in their environment. Their knowledge about their immediate environment, future events or the effects of their own actions is limited. Human intelligence's more or less competent handling of uncertainty is one of its great strengths.
Dealing with uncertainty is also an important issue in the field of artificial intelligence: AI systems should know when they do not know something, when they should be cautious, and when they need to take risks, especially in high-risk application areas such as critical infrastructure, healthcare, or the military.
Uncertainty in decision-making comes in two forms
In 1921, economist Frank H. Knight proposed a distinction between two fundamentally different forms of uncertainty in decision-making: risk and ambiguity.
Risk is present whenever, in a known situation, the outcome of an event is uncertain, but probabilities can be computed, as in dice, for example. Ambiguity, on the other hand, refers to unknown situations in which the probabilities are not known or cannot be determined.
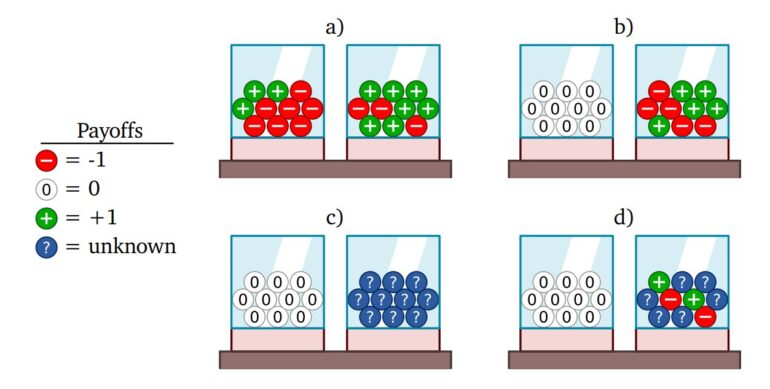
Nearly 40 years after Knight's publication, Daniel Ellsberg, also an economist, argued for the evolutionary advantages of different decision mechanisms for known but uncertain situations (risk) over entirely new situations (ambiguity).
Since then, researchers have found correlations between decision-making mechanisms and different patterns of neural activity in the human brain.
Deepmind shows how AI can handle risk and ambiguity
In a new paper, a team from Deepmind shows how AI agents can learn to deal with both forms of uncertainty via meta-learning. To accomplish this, the team modifies meta-learning algorithms used for AI agents to make them sensitive to risk and ambiguity.
So far, they say, meta-learning training has primarily resulted in AI agents that are neutral to risk and ambiguity because they are guided solely by the expected payoff and act in new situations as if the uncertainty is known.
Deepmind hopes that the new research will show that this is not necessarily the only outcome of meta-learning - and thus an implicit solution to optimization problems.
In its proposed approach, the team modifies the experience-generation process of AI agents, for example, by deploying a second agent in the environment during training to anticipate the first AI agent's plans and increase their likelihood of success. This then leads to a risk-taking AI agent, the authors said.
Sensitivity to ambiguity, on the other hand, occurs when an AI agent receives advice from multiple agents, who would naturally disagree in novel situations. In this way, the AI agent learns how best to deal with conflicting advice.
Deepmind's AI agents learn sensitivity to risk and ambiguity
In their work, Deepmind researchers train AI agents with the proposed meta-learning algorithms and show in various decision-making experiments that their agents develop sensitivity to risk and ambiguity, and thus perform better in certain cases than agents without them.
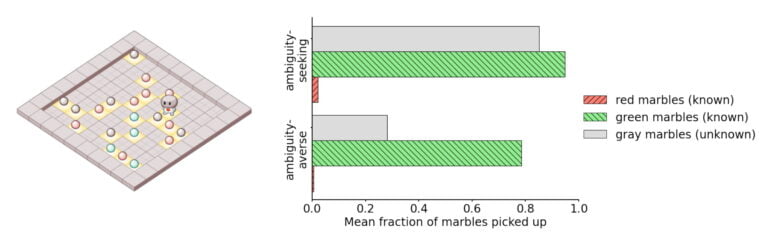
They also show how agents in urn experiments, for example, can learn missing information from their draws and thus reduce ambiguity to risk.
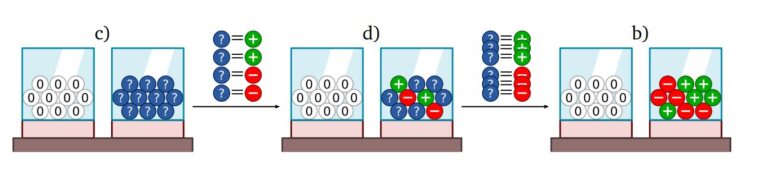
Most AI models today cannot distinguish between what they know and what they don't know, according to Deepmind, but this ability is critical for robust AI systems that can reliably deal with our highly uncertain and dynamic world. Often this robustness is associated with risk sensitivity, but it is also closely related to Knight's ambiguity, they said.
"We have shown two simple mechanisms to induce risk and ambiguity sensitivity. Both of them depend on the history of the agent’s observations, action and rewards. This way agents can
become uncertainty-seeking or -averse depending on the experiences within a particular context," the team writes. " We have shown how to deal with risk and ambiguity in a data-dependent
manner with our meta-training mechanisms."
The hope is that the proposed mechanisms will be the starting point for data-dependent methods for the study and application of uncertainty-sensitivity in humans and machines.
Full details and other interesting considerations, such as the relationship of uncertainty to closed and open worlds, are available in the paper "Beyond Bayes-Optimality: Meta-Learning What You Know You Don't Know."
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.