Deepmind wants to make artificial perception measurable
Benchmarks are instrumental to progress in AI research. With a new test, Deepmind wants to make the perception capabilities of artificial intelligence measurable.
Benchmarks fulfill a central role in AI research: they allow researchers to define their research goals and measure their progress toward those goals. Influential benchmarks such as ImageNet or even the Turing Test shape AI research rather than merely measuring it.
Major breakthroughs such as AlexNet, a deep-learning model that significantly beat other AI approaches in the ImageNet benchmark for the first time, were made possible by their respective benchmarks and associated datasets.
Multimodal AI systems are on the rise - and need a new benchmark
Currently, AI models are tested against a whole host of specialized benchmarks, such as for recognizing actions in videos, classifying audio, tracking objects, or answering questions about images. These benchmarks directly influence model architectures and training methods, and are thus directly involved in many AI advances.
However, while AlexNet was a supervised trained AI model for object recognition of fixed ImageNet categories, multimodal AI models specialized in perception are now trained more general and self-supervised with huge amounts of data. Models such as Perceiver, Flamingo, or BEiT-3 often attempt to machine-perceive multiple modalities simultaneously while mastering diverse perception tasks.
These multimodal models are currently being tested with various specialized datasets from different benchmarks - a slow, expensive process that does not fully cover all the perception capabilities of the new models.
With only specialized benchmarks available, a key driver for the progress of multimodal AI models is missing: a benchmark with a matching dataset that tests general perception capabilities.
Deepmind's "Perception Test" to become the central benchmark for perception models
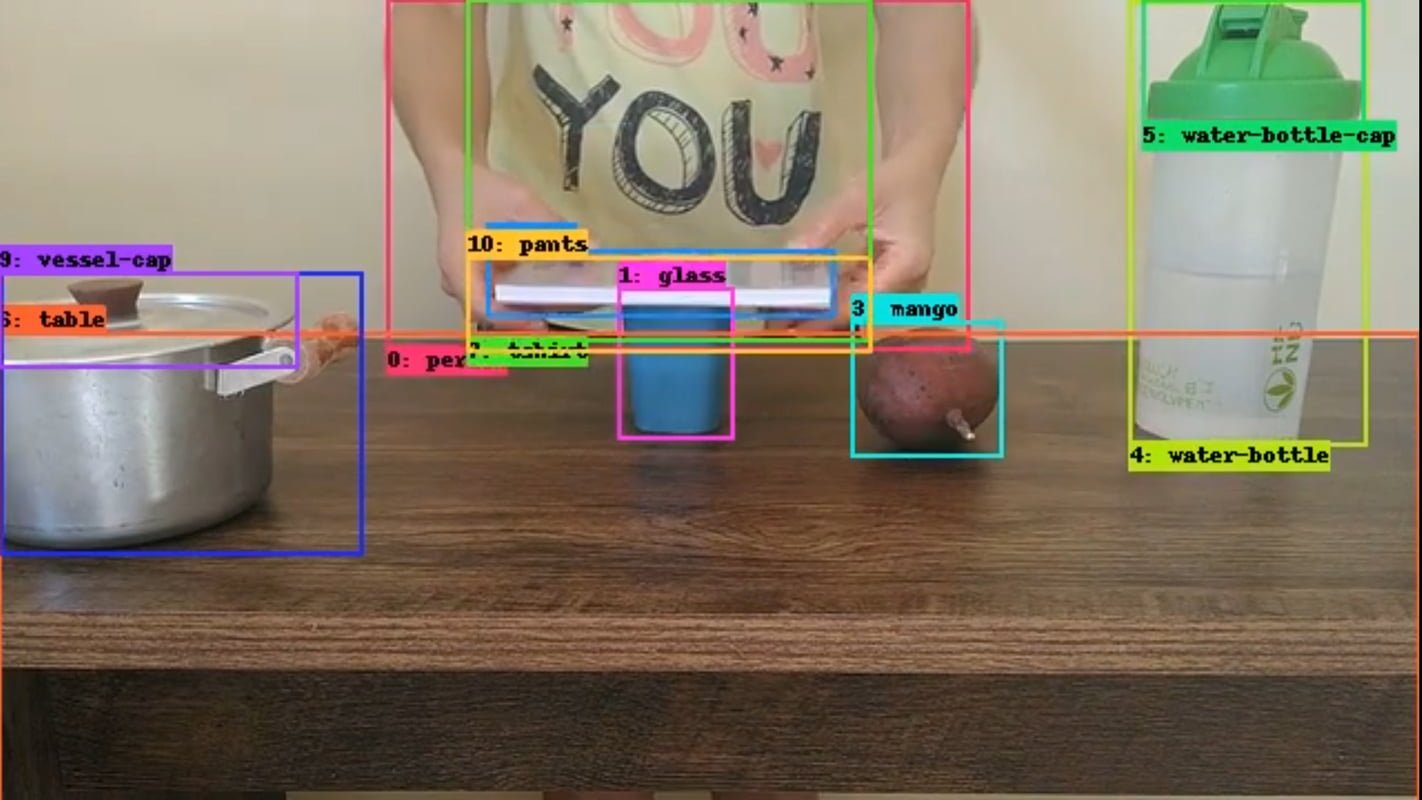
Researchers at Deepmind have therefore developed the "Perception Test," a dataset and benchmark of 11,609 labeled videos comprising six different tasks:
- Object tracking: a box is provided around an object early in the video, the model must return a full track throughout the whole video (including through occlusions).
- Point tracking: a point is selected early on in the video, the model must track the point throughout the video (also through occlusions).
- Temporal action localisation: the model must temporally localise and classify a predefined set of actions.
- Temporal sound localisation: the model must temporally localise and classify a predefined set of sounds.
- Multiple-choice video question-answering: textual questions about the video, each with three choices from which to select the answer.
- Grounded video question-answering: textual questions about the video, the model needs to return one or more object tracks.
The researchers cite tests from developmental psychology, as well as synthetic datasets such as CATER and CLEVRER, as inspiration. The videos in the new benchmark show simple games or everyday activities in which the AI models must solve their tasks. To prevent hidden bias, the videos were recorded by volunteer participants from different countries, ethnicities, and genders.
According to Deepmind, the models need four skills to succeed in the test:
- Knowledge of semantics: testing aspects like task completion, recognition of objects, actions, or sounds.
- Understanding of physics: collisions, motion, occlusions, spatial relations.
- Temporal reasoning or memory: temporal ordering of events, counting over time, detecting changes in a scene.
- Abstraction abilities: shape matching, same/different notions, pattern detection.
Deepmind runs its own test server for comparisons
The company assumes that AI models participating in the benchmark will already be trained with external data sets and tasks. The Perception Test, therefore, includes a small fine-tuning set of about 20 percent of the available videos.
The remaining 80 percent of the videos are split into a publicly available portion for benchmarking, as well as a withheld portion where performance can only be evaluated via Deepmind's own evaluation server.
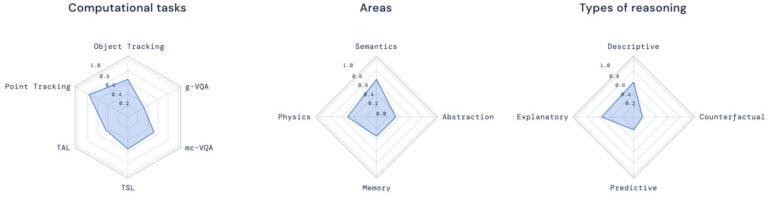
The results of the models are displayed in radar plots and across different dimensions to more clearly show the strengths and weaknesses of the models. An ideal model would score high on all radar surfaces and across all dimensions.
Deepmind hopes that the Perception Test will inspire and guide further research into general perception models. In the future, the team plans to work with the research community to further improve the benchmark.
The Perception Test benchmark is publicly available on Github and more details can be found in the "Perception Test" paper. A leaderboard and challenge server should also be available soon.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.