
Deepmind's AI system "DeepNash" masters the complex board game Stratego. For Deepmind's research team, DeepNash is a potential stepping stone for AI that can master complex everyday situations.
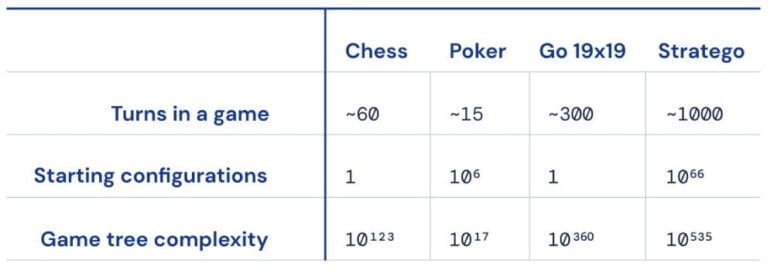
The turn-based conquest game Stratego is enormously complex, much more complex than the board games Chess and Go already mastered by Deepmind, as it requires significantly more moves and is played face-down. Much of the information relevant to the course of the game is not known - unlike in chess or Go, where all players look at the same board.
In 2019, Meta AI researchers introduced Pluribus to master poker, which is also played face-down. However, the techniques used there could not be transferred to the much longer Stratego, which often requires hundreds of moves before the game ends.
Until now, Stratego was therefore considered a major challenge in AI research that could only be solved at the amateur level. DeepNash changes that.
DeepNash reliably beats human professionals
DeepNash won 97 percent of matches against other computer systems in Stratego and 42 (84 percent) of 50 online duels against humans. In April, it secured a place in the top 3 best list of the online Stratego platform Gravon, which has been run since 2002.
Deepmind's research team sees this success as an important step towards AI systems that can better handle complex situations with unknown information in the real world.
DeepNash, or more specifically, the methods invented for its creation, have the potential to be a "game changer" in the real world, according to Deepmind. They could help solve problems characterized by imperfect knowledge and unpredictable scenarios, such as optimizing traffic management to reduce travel times and vehicle emissions.
In creating a generalisable AI system that’s robust in the face of uncertainty, we hope to bring the problem-solving capabilities of AI further into our inherently unpredictable world.
Deepmind
Such AI training, however, would still require complex simulation of everyday scenarios, a problem that remains largely unsolved.
DeepNash learns Nash equilibrium
Unlike previous AI systems, such as for chess or Go, Deepmind no longer relied on the common Monte Carlo tree search for DeepNash. This method could not handle the complexity of Stratego because of the sheer mass of moves and the amount of hidden information.

Instead of search technology, Deepmind relied on a model-free AI training approach in which the system learns by playing against itself without human input. Deepmind used the Regularised Nash Dynamics (R-NaD) algorithm, which it describes as a "new game-theoretic algorithmic idea." The company is releasing the code for R-NaD as open source on Github for interested researchers.
The algorithm steers the AI during self-play to a Nash equilibrium, named after game theory mathematician Jon Forbes Nash. The Nash equilibrium describes a game situation in which all players stick to their strategy, since a deviation would lead to a worse result. The worst possible win rate for DeepNash would therefore be 50 percent, assuming that the opponent acts as perfectly as the AI system.
During extensive reinforcement self-training, Deep Nash learned this optimal strategy in around 5.5 billion simulated games - and also appropriated human game concepts in the process, a phenomenon that was already evident in Deepmind's gaming AI AlphaZero. Deep Nash has mastered bluffing, for example, strategic moves that convey strength in a weak position, or the targeted sacrifice of certain game pieces to uncover information.
More game videos against human Experts: Game 2, Game 3, Game 4.
Former Stratego World Champion Vincent de Boer was involved in the development and evaluation of DeepNash. He is "surprised" by the level of play achieved and would trust the AI system to play a good role in a human world championship.


