
AI researchers found scaling laws for large language models in 2020. A new paper shows that such laws could also exist for reinforcement learning algorithms.
In a paper published in 2020 called "Scaling Laws for Neural Language Models," AI researchers investigated empirical scaling laws for the performance of language models such as GPT-2 or GPT-3, showing that the models' performance scales by several orders of magnitude depending on the model size, the dataset size, and the compute used for training.
In their work, the team derived optimal hyperparameters for training large language models given a fixed computational power budget, such as optimal network size and the amount of training data. In 2022, Deepmind researchers confirmed with Chinchilla that such scaling laws do exist, but that the hyperparameters proposed by the first team had underestimated the positive impact of more training data. According to Deepmind, for optimal training, the model size and the number of training tokens should scale equally.
Scaling laws drive AI development
As early as the release of GPT-2, OpenAI researchers noticed that the performance of their network scaled with size. Then, with GPT-3, the company showed just how big the potential performance leap from scaling was. In 2020, the scaling laws gave this phenomenon a theoretical basis, delivered (semi-)optimal hyperparameters for a fixed compute budget, and have since motivated numerous developments and investments in larger models.
Away from the big language models, there have been few attempts to find scaling laws. However, similarly designed models, such as for image generation or OpenAI's Video PreTraining for Minecraft, show a similar trend.
Researchers at Goethe-University Frankfurt now show that such scaling laws could also exist outside of such "foundation models".
Scaling laws for reinforcement learning
In their work, the researchers undertake an analysis in the style of the 2020 scaling law paper, but instead of scaling language models, they scale AlphaZero RL agents playing two different games: Connect Four and Pentago. These games are suitable candidates for their study because they are non-trivial to learn while being easy enough to enable a larger number of agents with a reasonable amount of resources, the paper says.
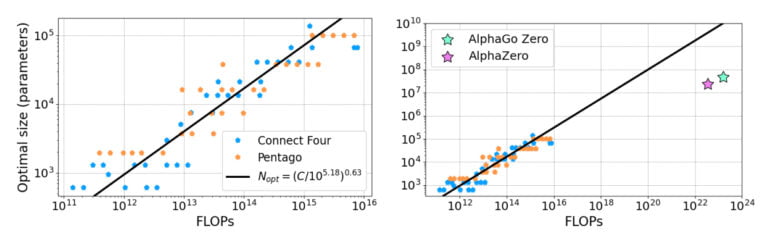
In their experiments, the researchers show that agent performance scales as a power law with neural network size "when models are trained until convergence at the limit of abundant compute." They believe this provides evidence that the scaling laws known from language models are also present in AlphaZero models. They suspect that other reinforcement learning algorithms also exhibit similar scaling behavior.
In an extrapolation of their results, the team also shows that the groundbreaking AI systems AlphaGo Zero and AlphaZero developed by Deepmind may have used neural networks that were too small and could perform even better with larger ones.

It is also possible that changes to the hyperparameters, such as those demonstrated for Chinchilla, could allow for a different optimal distribution of training resources in the case of AlphaZero. Investigating the effect of hyperparameters will be part of the team's next work.


