OpenAI's latest AI builds a Diamond Axe in Minecraft - why it matters

OpenAI uses Minecraft as an example to show how artificial intelligence can learn complex skills with video training and reinforcement learning.
In 2019, AI researchers first introduced the MineRL Challenge, which aims to teach artificial intelligence to play Minecraft. Specifically, MineRL consists of various tasks, such as finding a cave or building a house.
In Minecraft itself, there are also numerous other tasks that require different skills and vary in difficulty: Building a pickaxe out of wood, for example, is much simpler than building a pickaxe out of diamond, which requires more intermediate steps. Human players usually needed more than 20 minutes and about 24,000 actions for this.
Four years have passed since MineRL was first published. Every year, numerous participants compete against each other with their AI approaches in the various tasks. All teams get access to a special Minecraft version as well as an extensive collection of gameplay videos that serve as training material.
Because instead of relying solely on reinforcement learning, which is quickly overwhelmed by the complex tasks in the open world, the team behind MineRL sees a possible solution in hybrid approaches that rely on imitative learning as a central element.
Advances in MineRL could therefore pave the way to numerous applications in which AI systems learn to perform actions from human models, such as operating computers, smartphones or embodied robots.
OpenAI collects 70,000 hours of gameplay as training material
Now, in a new research paper, a team from OpenAI shows how a mix of video training and reinforcement learning can pave the way for an AI to make a diamond pickaxe. Central to the work is what's called Video PreTraining (VPT), which involves training an AI model with massive amounts of raw gameplay video and only a small amount of human-processed video.
Specifically, OpenAI collected nearly 270,000 hours of Minecraft videos, which were edited down to just under 70,000 hours of pure gameplay. In addition, contractors recorded another 2,000 hours of gameplay, including keyboard and mouse input data. OpenAI invested just under $2,000 for these videos.
With the labeled video data, OpenAI trained a so-called Inverse Dynamics Model (IDM) that learned from images of past and future events in gameplay to predict the corresponding keyboard and mouse inputs. The IDM then labeled the 70,000 hours of raw gameplay - so the small investment of $2,000 unlocked a massive treasure trove of data.
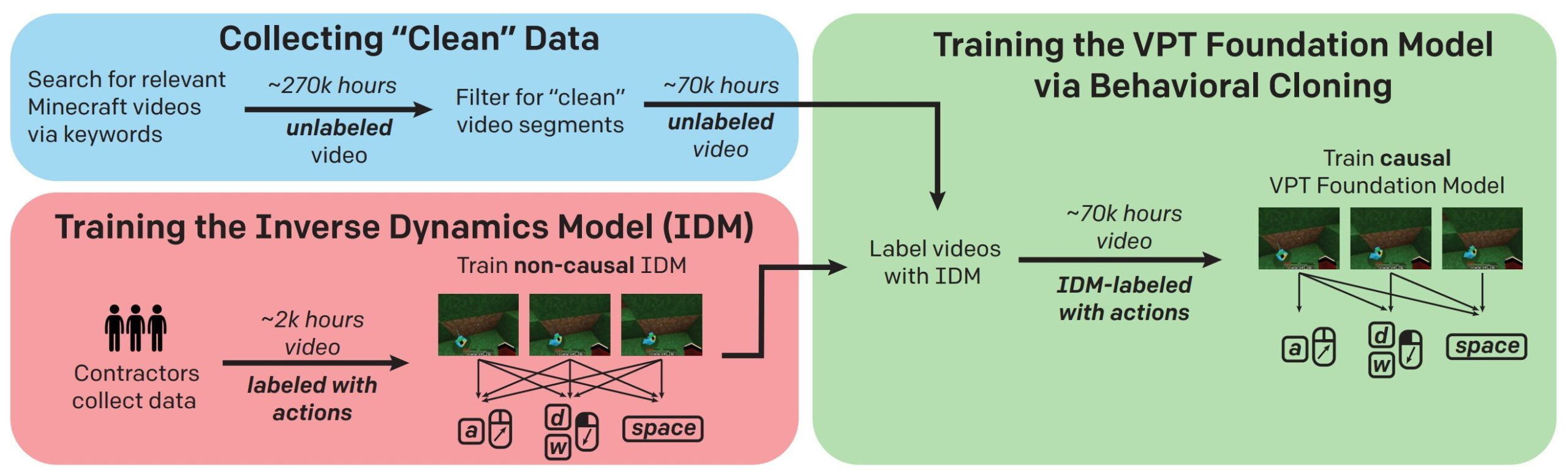
OpenAI used this labeled, massive video dataset to train what it calls the "VPT Foundation Model," which in training must predict future actions from past inputs and frames. In this way, the model learns to predict and clone the behavior of human players.
OpenAI's model shows interesting zero-shot capabilities
OpenAI deploys the VPT model in Minecraft with a 20Hz frame rate and simulated mouse and keyboard. With just video training (zero-shot), the AI model can perform tasks that were previously nearly impossible with just reinforcement learning: It can cut down trees, collect logs, turn the logs into boards, and make a crafting table from those boards. According to OpenAI, this takes humans about 50 seconds, or 1,000 consecutive play actions.
Video: OpenAI
The model also shows other complex actions, such as swimming, chasing and eating animals, and also "pillar jumping," in which players rise in height by repeatedly jumping and placing a block under themselves.
OpenAI additionally trained the AI model with labeled videos of Minecraft gameplay from the first ten minutes of a new game to see if it could be fine-tuned for reliable "early game" capabilities.
After this fine-tuning, the researchers noticed a massive improvement in early-game capabilities. In addition, the fine-tuned model can go deeper into the technology tree and produce wooden and stone tools. In isolated cases, the researchers were even able to observe rudimentary shelter building or village scavenging, including looting chests.
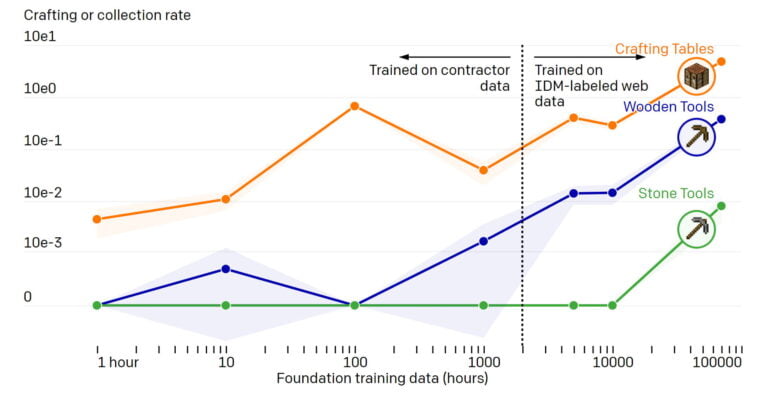
In a comparison, OpenAI also shows that an AI model trained only with video data tagged by humans cannot match the capabilities of the VPT model. Once again, more data leads to better results.
OpenAI cracks the path to the diamond pickaxe
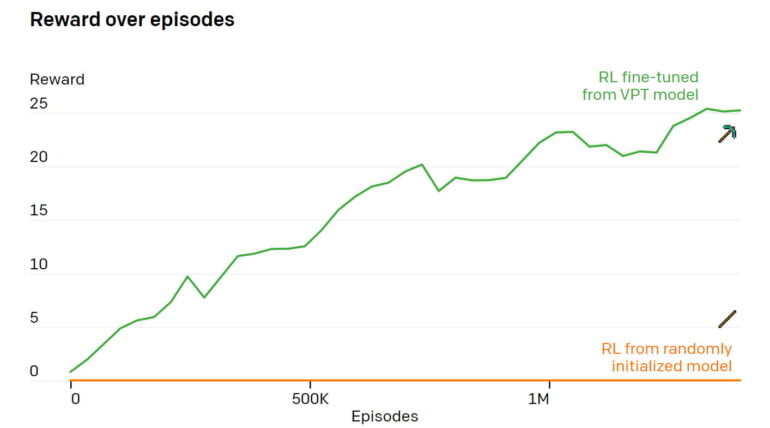
In a further step, OpenAI uses the pre-trained and subsequently fine-tuned VPT model as the basis for an AI agent that learns through reinforcement to make a diamond pickaxe in under ten minutes.
During training, the agent is rewarded for collecting and making the relevant objects on the way to the pickaxe. As expected, the learned imitation of human behavior turns out to be a better starting point than the otherwise randomly performed actions of standard reinforcement learning agents.
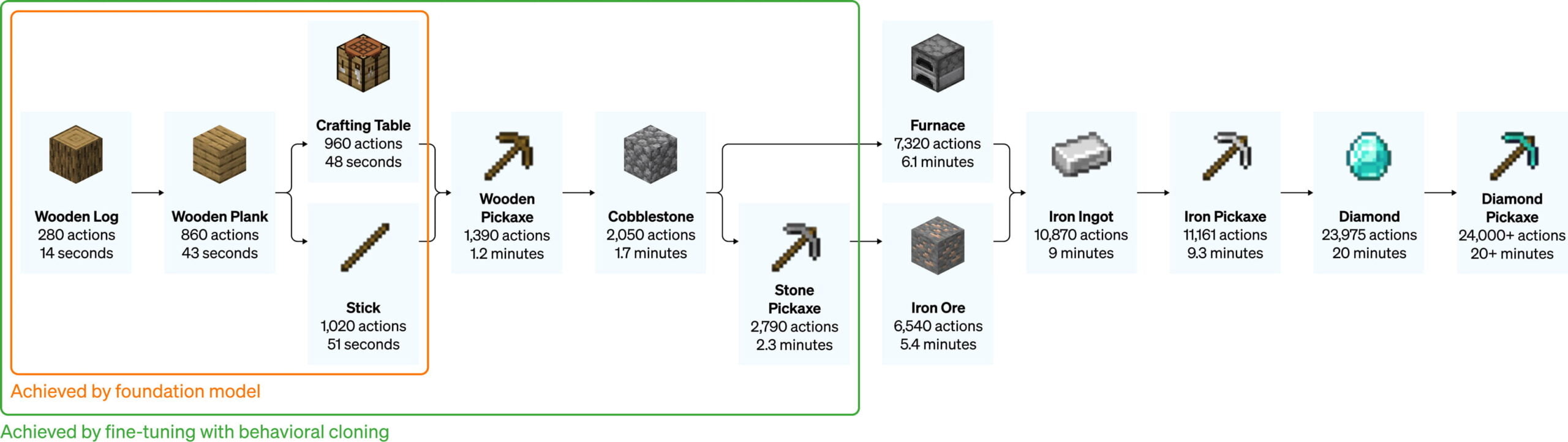
According to OpenAI, such a randomly initialized strategy achieves few rewards because it never learns to collect logs and rarely collects sticks. In contrast, agents based on the VPT model learn to make iron pickaxes 80 percent of the time, collect diamonds just under 20 percent of the time, and manage to make a diamond pickaxe 2.5 percent of the time.
OpenAI says, this puts the AI system on the same level as a human on average and it is the first AI model that can make a diamond pickaxe in a Minecraft world without any limitations.
Video: OpenAI
The model also developed useful diamond mining skills, the researchers said, such as efficient mining patterns, cave exploration, returning to previously placed objects such as the crafting table, and advanced techniques such as using wood pickaxes as fuel when transitioning to iron tools.
OpenAI wants to train with even more data - and plans new experiments
For additional refinements, it would be possible to collect up to a million hours of Minecraft training videos, the researchers estimate. Larger and better-tuned models promise further advancements.
The current VPT model is also conditioned only on past observations, so it cannot be controlled directly. However, the OpenAI team was able to show in an initial test with 17,000 hours of video footage, including associated captions, that a combination of VPT plus training with speech accompanying that video provides some control.
Since in the gameplay videos the speakers sometimes comment on their intentions (e.g. "Let's cut down some trees to make a wooden axe"), the model can make connections between the language and the learned behavioral priors.
For sentences that encourage the AI agent to explore (e.g., "I'm going to explore" and "I'm going to find water"), the AI agent moves significantly farther away from its starting point. In addition, the agent preferred to collect early game items such as seeds, wood, and dirt when prompted with texts such as "I will collect seeds /chop wood / collect dirt."
As of yet, this level of control is too low to be useful, the researchers said. But more training data, more computing power, and a multimodal training process in which the model learns to jointly predict the next action and the text in the final stage could change that, the team reckons.
OpenAI is open-sourcing the human-captured video data, including input data, the Minecraft environment, model code and model weights.
The company has also partnered with the MineRL-NeurIPS competition this year: all participants can use OpenAI's models and fine-tune them to solve the competition's tasks.
OpenAI uses Minecraft for research on Foundation Models
For OpenAI, the VPT model shows that video pre-training paves the way for AI agents to learn to act by watching large amounts of Internet video. VPT shows that semi-supervised imitation learning from large and freely available video datasets can work for domains that require sequential decisions, the researchers said.
The resulting VPT model is a "foundation model" that resembles large language models such as OpenAI's GPT-3 and can be fine-tuned with additional data - as demonstrated in Minecraft - or serve as the basis for AI agents that use reinforcement learning. Training the base model is made possible using IDM, which in the case of Minecraft generates the corresponding input data for the Internet videos. This method is a key building block for VPT, the researchers said.
"The internet contains an enormous amount of publicly available videos that we can learn from. You can watch a person make a gorgeous presentation, a digital artist draw a beautiful sunset, and a Minecraft player build an intricate house," OpenAI writes in a blog post. "However, these videos only provide a record of what happened but not precisely how it was achieved, i.e. you will not know the exact sequence of mouse movements and keys pressed."

Similar to the foundation models for speech, VPT also shows a trend towards better capabilities with more training data. The largest model has almost 500 million parameters. For the experiments, however, OpenAI has reverted to a smaller model with 220 million parameters for cost reasons.
In principle, learning with the human keyboard and mouse interface enables lossless modeling of the full range of human behavior in Minecraft, OpenAI said.
VPT therefore also provides a general approach for training behavioral priorities in hard but generic action spaces in any domain that has a large amount of freely available unlabeled data - such as computer usage.
Besides Minecraft, this includes almost any software of which there is enough video material. Should OpenAI improve the controllability of the models by integrating the audio/subtitle track, models could soon emerge that can operate everyday software in a rudimentary way. These models could, for example, process DALL-E 2 images via the OpenAI API directly in Photoshop.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.