Even the most capable LLMs fail at simple logic task that kids can solve, study finds

Researchers used a simple text task to show that current language models fail when it comes to basic logical conclusions. But the models insist on wrong answers and overestimate their abilities.
Using an easy text task, researchers from the AI lab LAION, the Jülich Supercomputing Center, and other institutions have found serious flaws in the logical thinking of modern language models.
The problem is a simple puzzle that most adults, and probably even elementary school children, could solve: "Alice has N brothers and M sisters. How many sisters has Alice's brother?"
The correct answer is the addition of M + 1 (Alice plus her sisters). The researchers varied the values of N and M, as well as the order of the siblings in the text.
They fed the puzzle into small and large language models such as GPT-4, Claude, LLaMA, Mistral, and Gemini, which are known for their supposedly strong logical reasoning abilities.
The results are disappointing: most models couldn't solve the task or only solved it occasionally. Different prompt strategies didn't change the basic result.
Only GPT-4 and Claude could sometimes find the right answer and back it up with a correct explanation. But even with them, the success rate varied greatly depending on the exact wording of the prompt.
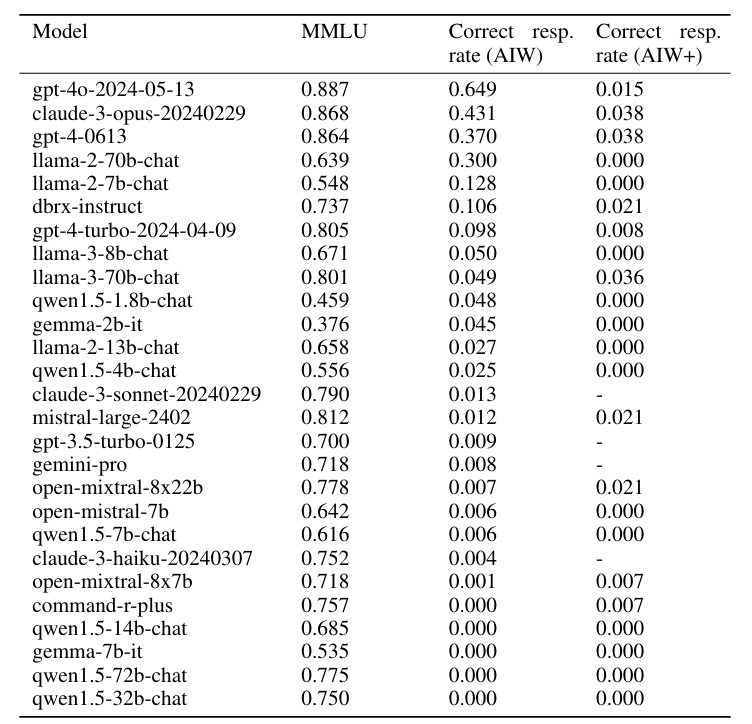
Overall, the average correct answer rate of the language models was well below 50 percent. Only GPT-40 performed above chance with 0.6 correct answers. In general, the larger language models performed much better than the small ones, leading the researchers to comment: "Go small, go home."
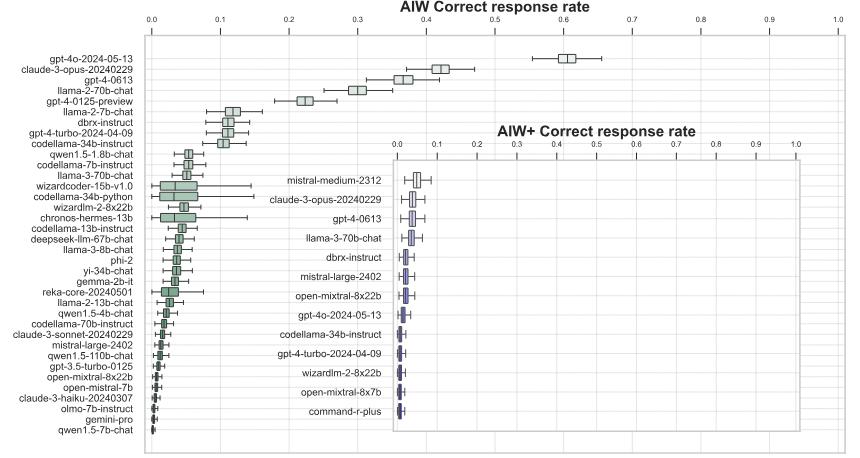
A harder version of the task (AIW+) brought even the best models Mistral Medium, GPT-4 and Claude 3 Opus to the brink of total mental collapse with very few correct answers.
What makes this breakdown even more dramatic is that the models expressed strong confidence in their incorrect answers and used pseudo-logic to justify and support the validity of clearly incorrect answers, according to the paper.
The fact that LLMs fail this simple task is even more striking when you consider that the same models perform well on common benchmarks of logical reasoning. The simple "Alice" task makes it clear that these industry-wide tests don't reveal the models' weaknesses, the researchers say.
The research team believes that while the models have a latent ability to draw logical conclusions, they can't do so in a robust and reliable way. This requires further study.
However, it is clear that current benchmarks do not accurately reflect the true capabilities of language models, they say, and call on the scientific community to develop better tests that detect logical flaws.
"We hypothesize that generalization and core reasoning abilities are thus latently present in those models, as otherwise they would not be able to generate such responses at all, as guessing correct answer including full correct reasoning by accident in such cases is impossible. The fact that the correct reasoning responses are rare and model behavior is not robust to problem variations demonstrates though deficiency to exercise proper control over these capabilities."
From the paper
An earlier study showed how weak LLMs are at the simplest logical inferences. Even though language models know the mother of actor Tom Cruise, they can't figure out that Tom Cruise is the mother's son. This so-called "reversal curse" hasn't been solved yet.
Another recent study shows that language models act more irrationally than humans when they draw and justify incorrect conclusions.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.