
- Added Falcon-180B
Updated on September 07, 2023:
The Technology Innovation Institute releases Falcon-180B, the largest model in the Falcon series. It is based on Falcon 40B and has been trained with 3.5 trillion tokens on up to 4096 GPUs simultaneously via Amazon SageMaker for a total of ~7,000,000 GPU hours.
Falcon 180B is said to outperform Llama 2 70B as well as OpenAI's GPT-3.5. Depending on the task, performance is estimated to be between GPT-3.5 and GPT-4, and on par with Google's PaLM 2 language model in several benchmarks.
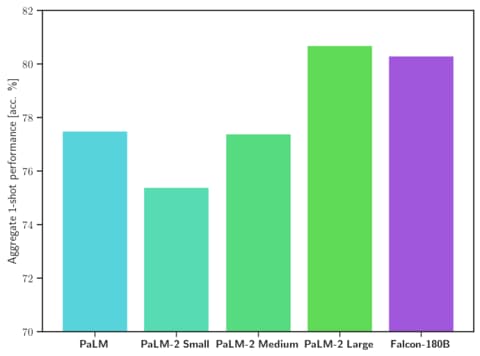
In the Hugging Face Open Source LLM ranking, Falcon 180B is currently just ahead of Meta's Llama 2. But compared to Llama 2, Falcon180B required four times as much computation to train, and the model is 2.5 times larger. A fine-tuned chat model is available.
You can find a Falcon-180B demo and more information at Hugging Face. Commercial use is possible, but very restrictive. You should take a close look at the license.
Original article from May 29, 2023:
FalconLM open-source language model beats Meta's LLaMA
The open-source language model FalconLM offers better performance than Meta's LLaMA and can also be used commercially. But commercial use is subject to royalties if revenues exceed $1 million.
FalconLM is being developed by the Technology Innovation Institute (TII) in Abu Dhabi, United Arab Emirates. The organization claims that FalconLM is the most powerful open-source language model to date, although the largest variant, with 40 billion parameters, is significantly smaller than Meta's LLaMA with 65 billion parameters.
On the Hugging Face OpenLLM Leaderboard, which summarizes the results of various benchmarks, the two largest FalconLM models, one of which has been refined with instructions, currently hold the top two positions by a significant margin. TII also offers a 7-billion model.

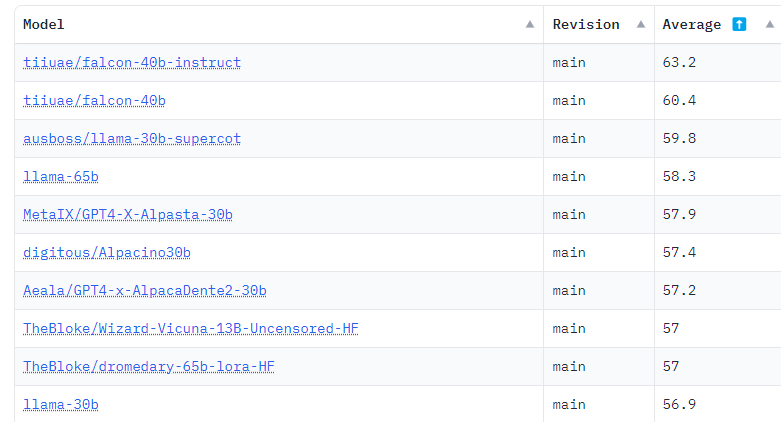
FalconLM trains more efficiently than GPT-3
An important aspect of FalconLM's competitive edge, according to the development team, is the data selection for training. Language models are sensitive to data quality during training.
The research team developed a process to extract high-quality data from the well-known common crawl dataset and remove duplicates. Despite this thorough cleaning, five trillion pieces of text (tokens) remained - enough to train powerful language models. The context window is at 2048 tokens, a bit below ChatGPT level.
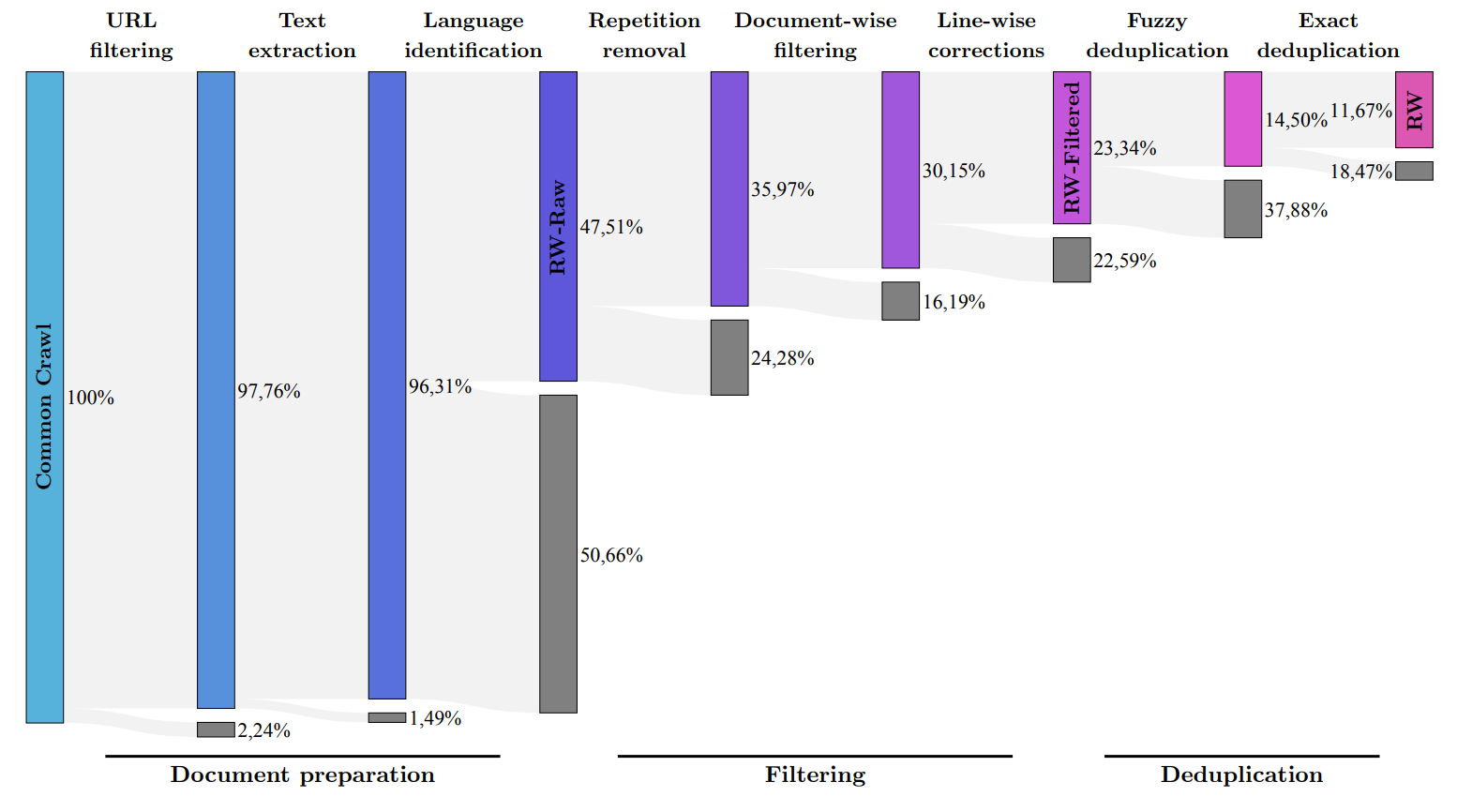
FalconLM with 40 billion parameters was trained with one trillion tokens, the model with 7 billion parameters with 1.5 trillion. Data from the RefinedWeb dataset was enriched with "a few" curated datasets from scientific articles and social media discussions. The best-performing instructional version, the chatbot version, was fine-tuned using the Baize dataset.
The TII also mentions an architecture optimized for performance and efficiency, but does not provide details. The paper is not yet available.
According to the team, the optimized architecture combined with the high-quality dataset resulted in FalconLM requiring only 75 percent of the computational effort of GPT-3 during training, but significantly outperforming the older OpenAI model. Inference costs are said to be one-fifth of GPT-3.
Available as open source, but commercial use can get expensive
TII's use cases for FalconLM include text generation, solving complex problems, using the model as a personal chatbot, or in commercial areas such as customer service or translation.
In commercial applications, however, TII wants to profit from a million dollars in revenue that can be attributed to the language model: Ten percent of revenues are due as royalties. Anyone interested in commercial use should contact TII's sales department. For personal use and research, FalconLM is free.
All versions of the FalconLM models are available for free download from Huggingface. Along with the models, the team is also releasing a portion of the "RefinedWeb" dataset of 600 billion text tokens as open source under an Apache 2.0 license. The dataset is also said to be ready for multimodal extension, as the examples already include links and alt text for images.



