FinGPT is an financial AI framework designed to learn from the wisdom of the market

FinGPT is an AI framework designed to facilitate access to optimized language models for financial tasks. It is open source and can be used commercially.
With FinGPT, the research team from Columbia University and New York University (Shanghai) aims to democratize access to language models optimized for financial markets.
Proprietary models such as BloombergGPT would benefit from access to exclusive financial data, the researchers write. In addition, they say, BloombergGPT is too expensive, estimated at five million US dollars for training, and too inflexible.
Instead, FinGPT uses pre-trained language models and fine-tuning using the efficient low-rank adaptation (LoRA) method. The LoRA method can reduce the number of trainable parameters from 6.17 billion to just 3.67 million, according to the team. This makes the fine-tuning process much faster and less computationally intensive, while still allowing the model to efficiently understand and produce financial text.
Focus on high quality data pipeline
The researchers argue that the success of a financial language model depends as much on the capabilities of the language model as it does on the quality of the data. They see FinGPT as a direct response to BloombergGPT, and therefore place a strong emphasis on data quality and preparation.
The team first developed an automated pipeline of curated, high-quality financial data. They draw from established sources such as Yahoo Finance and Bloomberg, as well as content from Twitter, Reddit, and SEC filings. They also pull information from trend barometers like Google Trends and established datasets like AShare and Stocknet.
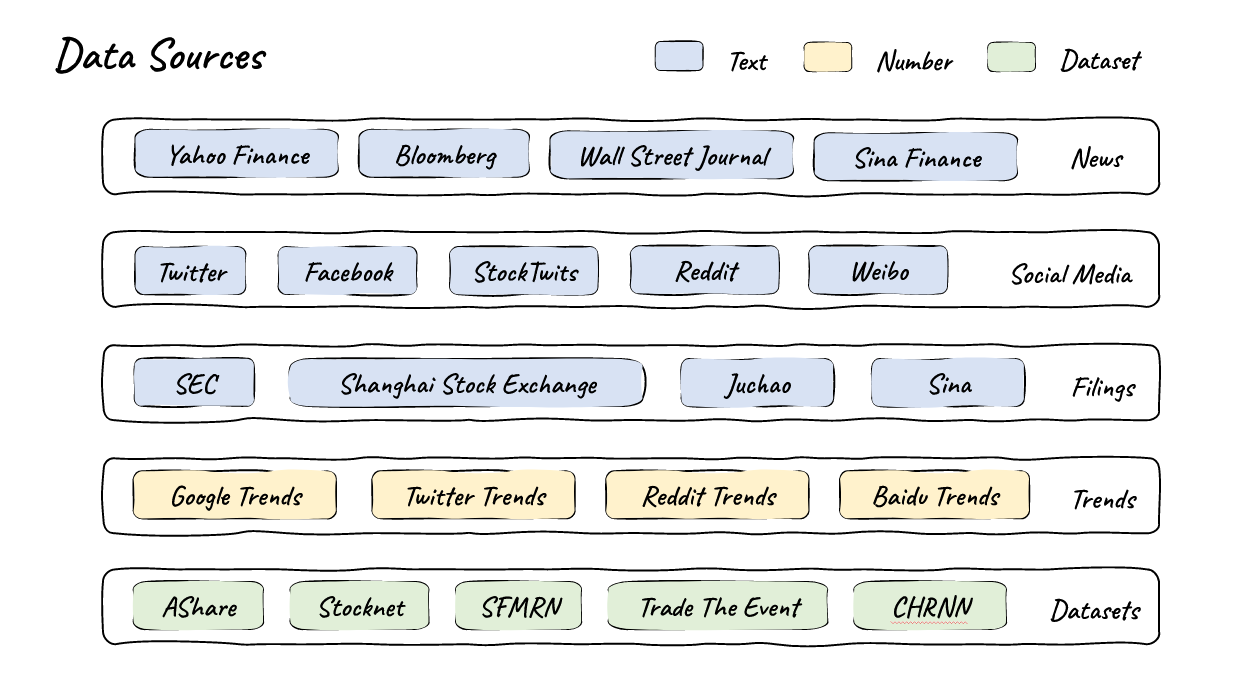
According to the team, this data goes through a thorough cleaning and formatting process to ensure its quality and usability.
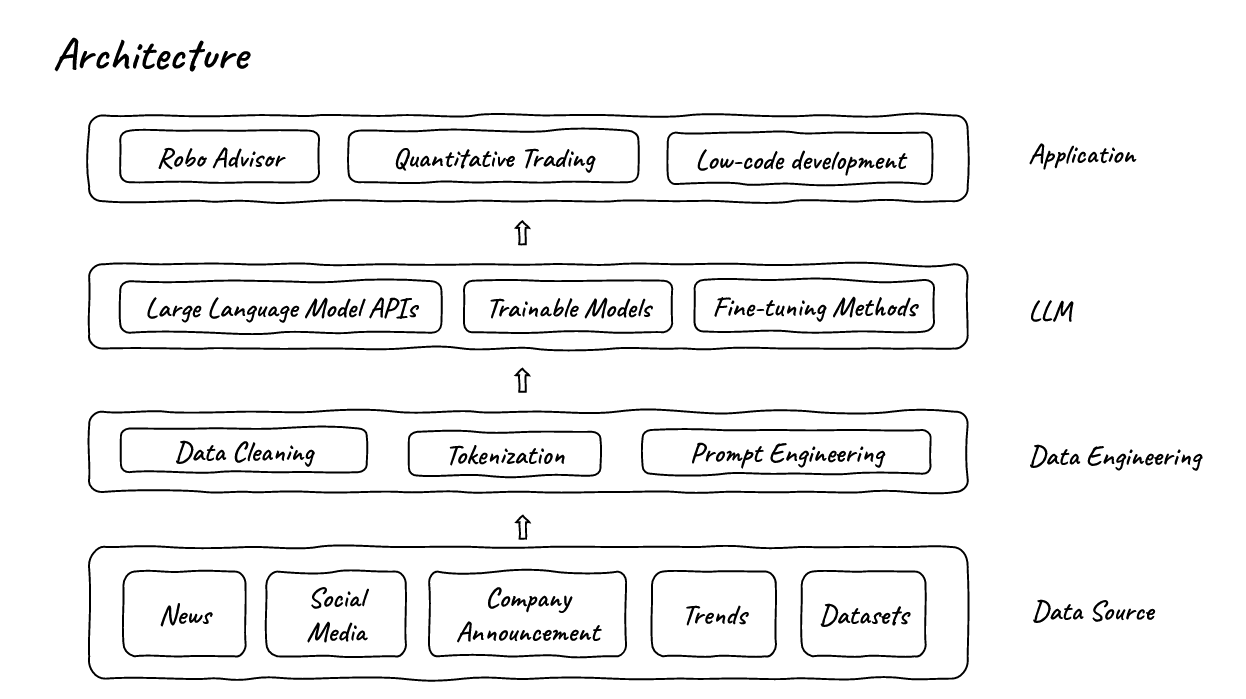
The data is then processed with language models using the FinGPT framework. Depending on the application, LLMs from well-known companies can be used, or trainable or fine-tunable models can be enriched with custom data. Since fine-tuning is faster than fully training a model, FinGPT is said to be more up-to-date and dynamic than BloombergGPT.
Automated human feedback via a detour
Fine-tuning a model typically requires a large amount of high-quality, labeled data. Labeled data means that the data contains additional information from which the model can learn, such as whether a news story is considered good or bad. Such data can be difficult and expensive to obtain, especially in specialized areas such as finance.
That's why the FinGPT team came up with an elegant solution: Instead of manually labeling the data, it uses the stock market's reactions to news as labels. For example, if the stock price rises after a news item, it can be classified as "positive."
The researchers used thresholds for the three sentiments: positive, negative, and neutral. When the model is fine-tuned, it is instructed to select one of the three sentiments - positive, negative, or neutral - as a label for the news.
Following OpenAI's RLHF (Reinforcement Learning with Human Feedback), the researchers call their principle RLSP: Reinforcement Learning on Stock Prices, which in turn could be seen as an indirect form of human feedback. The system is supposed to learn from the "wisdom of the market" to better understand and predict financial markets.
An open-source framework for AI in the financial sector
The team cites robo-advice, quantitative trading, portfolio optimization based on a variety of factors, sentiment analysis in financial markets, risk management, fraud detection, credit scoring, prediction of insolvency or potential acquisitions, analysis of ESG profiles based on public reports and news, low-code development, and financial education as potential applications for the FinGPT framework.
The researchers release FinGPT as open source under the MIT license on Github. Commercial use is permitted. The developers do not guarantee or take responsibility for financial decisions based on the model.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.