French AI company Mistral introduced Pixtral-12B, its first multimodal model capable of processing both images and text, at a conference in San Francisco. This open-source model builds on Mistral's text model NeMo-12B, launched earlier this year.
With 12 billion parameters and a size of about 24 GB, Pixtral-12B can answer questions about multiple images provided as URLs or Base64-encoded. Its vision encoder supports image resolutions up to 1,024 x 1,024 pixels.
Benchmark performance
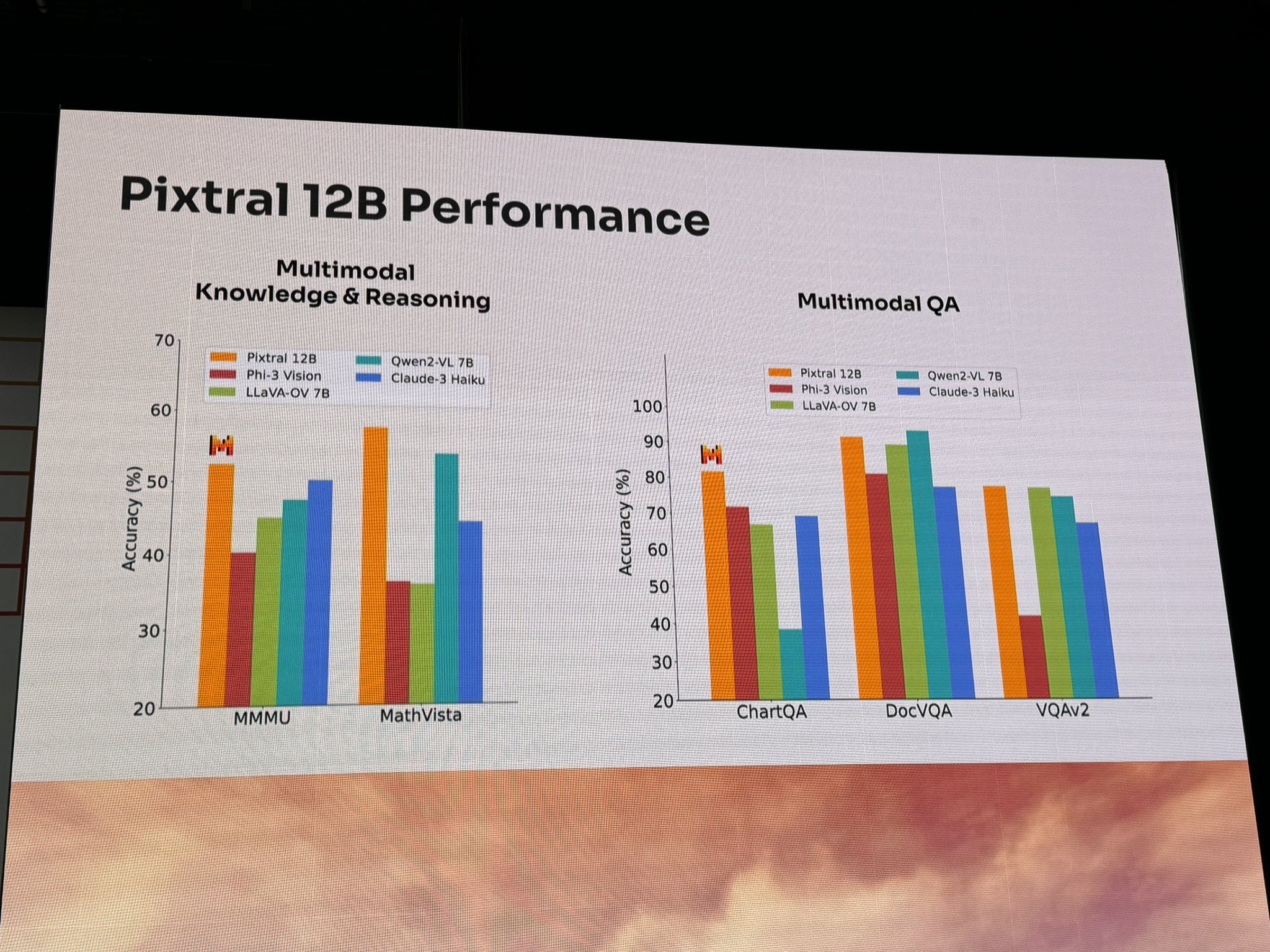
Mistral claims Pixtral-12B outperforms other open-source vision models like Phi 3, Qwen2 VL, and LLaVA in some multimodal capabilities. However, larger closed multimodal models such as Claude 3.5 Sonnet or GPT-4 still show superior image comprehension.
Ad
Image: swyx/X
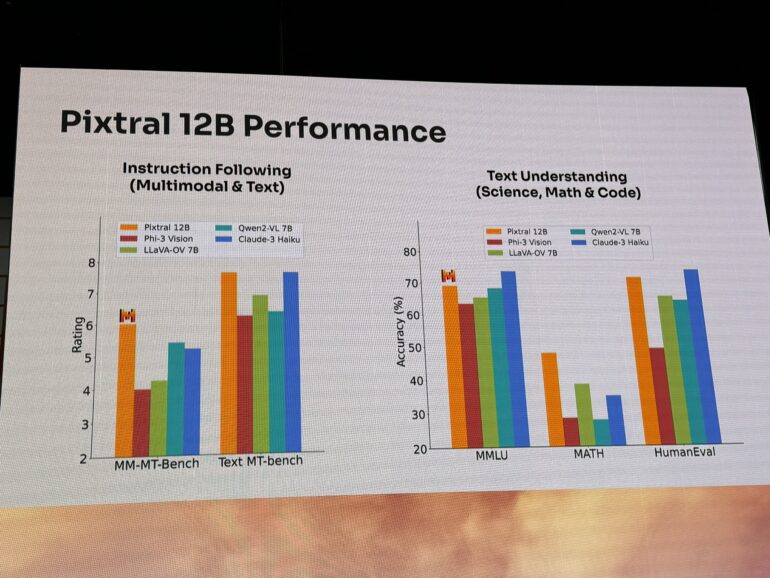
In certain tests, Pixtral-12B shows significant improvements over similar models. For important text comprehension benchmarks like MMLU and HumanEval, it trails slightly behind Anthropic's smallest model, Claude 3 Haiku. Smaller but vision-only models like Qwen2-VL 7B and Phi 3.5 Vision also surpass Pixtral-12B in some vision benchmarks.
Ad
DEC_D_Incontent-1
Image: swyx/X
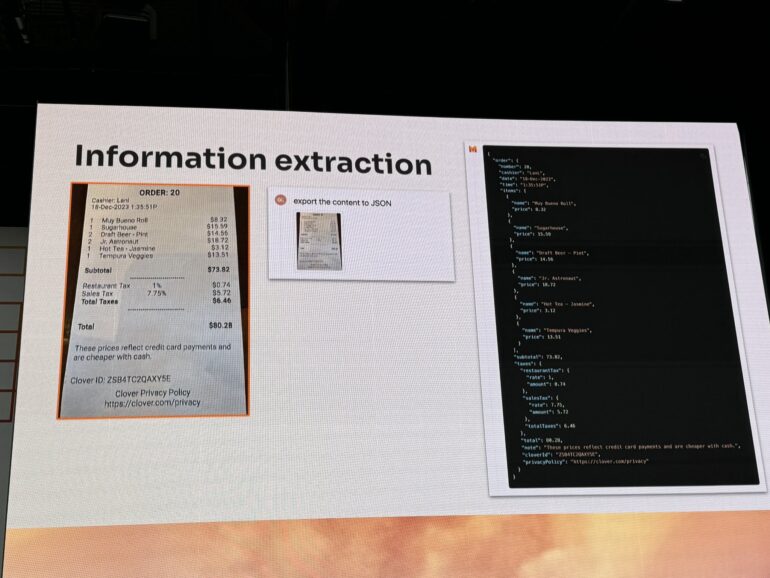
Mistral reports that Pixtral-12B can perform optical character recognition (OCR), analyze diagrams and schemas, and process screenshots. The model also shows promise with satellite imagery. While not yet tested on video frames, its 128,000-token context window suggests potential in this area.
Image: swyx/X
Availability and licensing
Mistral has released Pixtral-12B under an Apache 2.0 license for free use. The model is currently available on GitHub and Hugging Face. Sophia Yang, Head of Developer Relations at Mistral, announced that Pixtral-12B will soon be available for testing on Mistral's platforms Le Chat and La Plateforme.
As with previous releases, Mistral quickly made Pixtral-12B publicly available. However, the company has not provided information about the training data or independent performance evaluations beyond their own benchmarks.
Ad
DEC_D_Incontent-2
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.