Gemini 3 Pro and GPT-5 still fail at complex physics tasks designed for real scientific research
A new physics benchmark called "CritPt" puts leading AI models to the test at the level of early-stage PhD research. The results show that even top systems like Gemini 3 Pro and GPT-5 still fall far short of acting as autonomous scientists.
More than 50 physicists from over 30 institutions built the "CritPt" benchmark to see whether AI can truly help researchers push the boundaries of modern physics. Their goal goes far beyond checking textbook recall. The benchmark asks models to solve original, unpublished research problems that resemble the work of a capable graduate student starting an independent project.
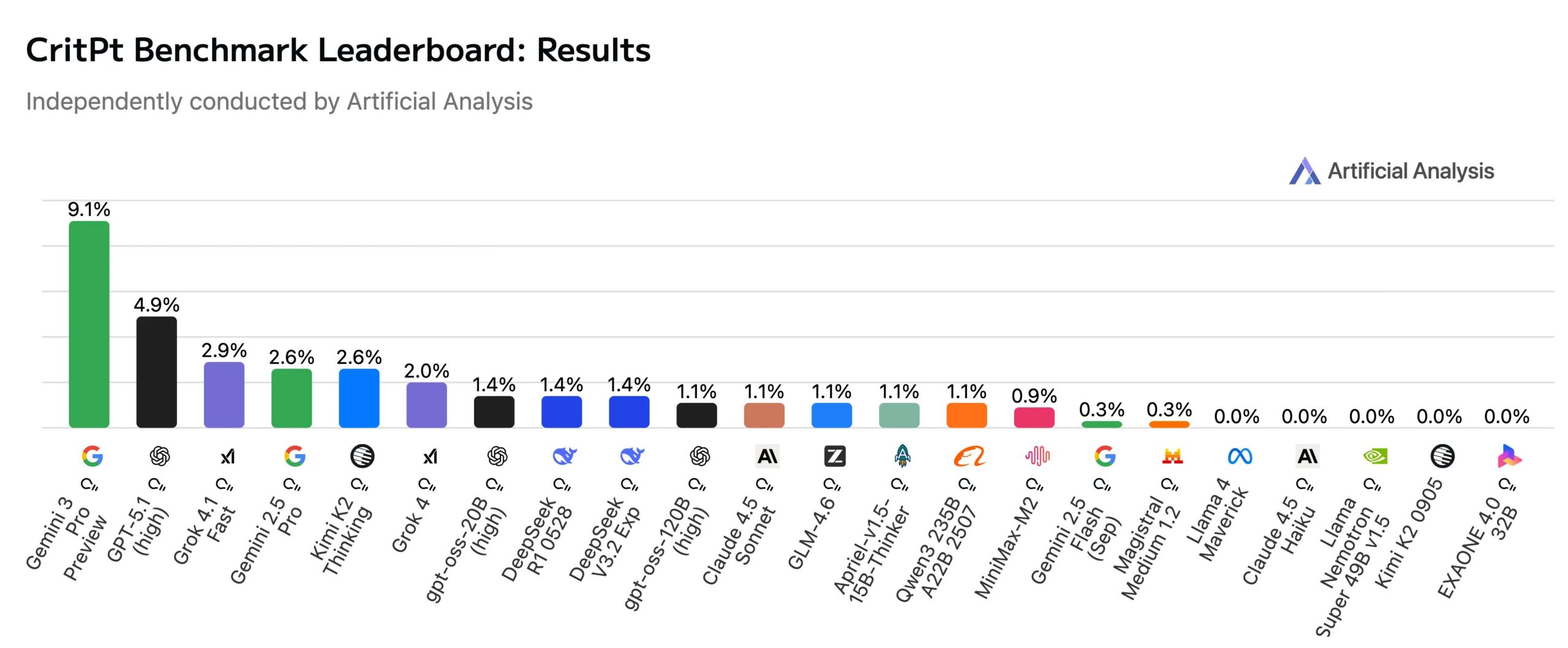
The early results set a sobering baseline. In an independent evaluation by Artificial Analysis, Google's "Gemini 3 Pro Preview" reached just 9.1 percent accuracy while using 10 percent fewer tokens than OpenAI's "GPT-5.1 (high)," which placed second at 4.9 percent. Even at the top of the leaderboard, the systems miss the vast majority of tasks.
Doctoral-level reasoning remains a major hurdle
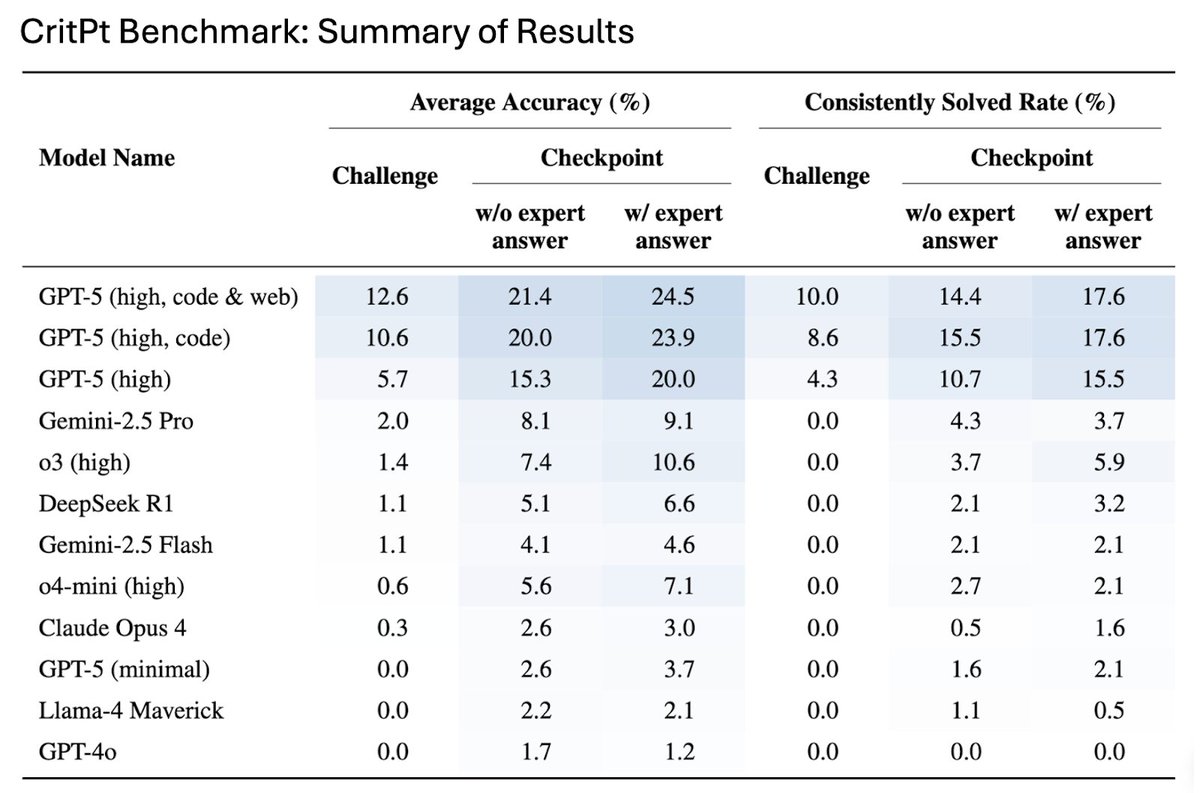
CritPt includes 71 full research challenges from eleven physics fields, such as quantum physics, astrophysics, high-energy physics, and biophysics. To prevent guessing or retrieval, all problems are based on unpublished material. The team also broke each challenge into 190 smaller "checkpoints" to measure partial progress.
The findings offer a reality check: current large language models lack the rigor, creativity, and precision needed to solve open-ended physics problems on their own. Still, the models show measurable improvement on simpler, well-defined subtasks, which suggests that targeted support roles may be more realistic.
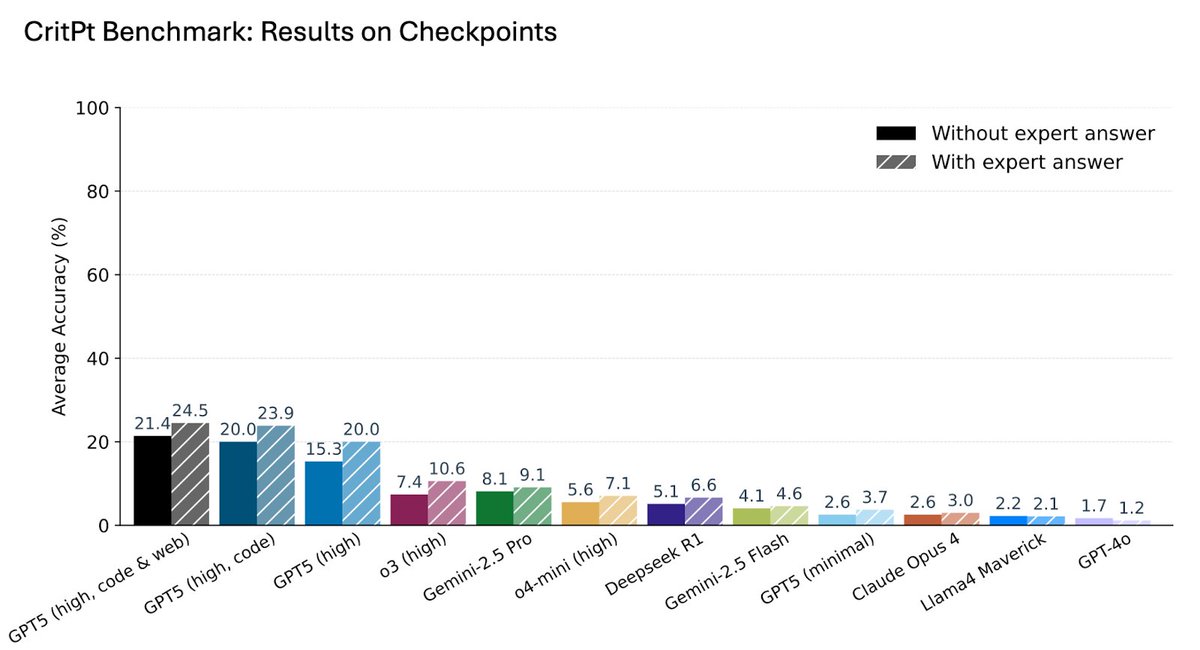
The team also tested consistency using a stricter metric called the "consistently solved rate," which requires a model to give the correct answer four out of five times. Under this requirement, performance collapses across the board, showing how fragile model reasoning remains even on tasks they sometimes solve.
This lack of robustness creates a serious challenge for research workflows. The models often produce answers that look convincing but contain subtle errors that are difficult to catch, which can easily mislead researchers and require time-consuming expert review.
The researchers argue that, for the foreseeable future, the more realistic goal is not an "AI scientist" replacing human experts, but a "research assistant" automating specific workflow steps. This matches current industry plans: OpenAI aims to ship a research intern system by September 2026 and a fully autonomous researcher by March 2028. The company claims that GPT-5 is already saving researchers time.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.