German Commons shows that big AI datasets don’t have to live in copyright limbo

German Commons is now the largest openly licensed German text dataset, offering a foundation for building legally compliant German language models.
Most large language models train on web data with unclear copyright. German Commons takes a different approach: every text comes from institutions with clear, verifiable licensing. The project, led by the University of Kassel, the University of Leipzig, and hessian.AI, relied on the licensing info provided by these sources, without additional verification. According to their study, the team collected 154.56 billion tokens from 35.78 million documents.
The dataset pulls from 41 sources across seven categories: web content, political documents, legal texts, news, business, cultural, and scientific material. Contributors include the German National Library, Austrian National Library, the German Digital Dictionary (DWDS), the Leibniz Institute for the German Language (IDS), and Wikimedia projects.
News and historical texts shape the dataset
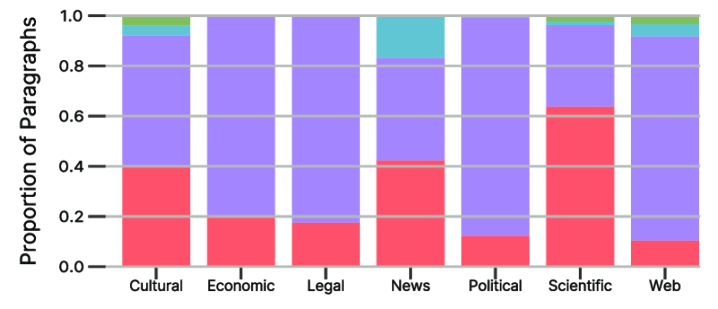
News makes up the largest chunk of the collection, with cultural content coming next. Most of this comes from historical newspaper archives and digitized books from the 1700s to 1900s. Web content is a smaller share, and science and business are underrepresented.
Most texts are public domain, and all licenses allow redistribution, modification, and commercial use.
To get the data ready, the team built a multi-step pipeline for quality filtering, deduplication, and fixing text formatting. Since much of the data is from OCR-scanned documents, they used special filters to catch common conversion errors. German characters like umlauts were especially tricky for the software.
Quality checks cut 46 percent of the original data, mostly non-German texts and very short documents. In the end, 51 percent of the collected data made the cut.
A review of 385,467 text samples found very little toxic content. In categories like violence and discrimination, about 95 percent of texts scored as harmless.
Open source pipeline lets the community build better German AI
The team made their llmdata data processing library open source for full reproducibility. The pipeline is tailored for German and can be expanded by others.
German Commons is free on Hugging Face, making it easier to train German language models without worrying about copyright issues.
This release is part of a broader trend in AI toward open, legally compliant datasets. The Common Pile project from the University of Toronto and EleutherAI recently released an 8 TB English-language dataset built entirely from openly licensed sources. Early results show that models trained on this data are competitive, though they still have some gaps with everyday language.
Earlier, the German OpenGPT-X project used Teuken-7B to show how multilingual European AI models can be built. That 7-billion-parameter model was trained on all 24 official EU languages, but the training data did not go through a full license check.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.