Google adds native image generation to Gemini language models

Gemini's ground-up multimodal training enables direct image generation, potentially offering more precise outputs compared to traditional image models.
Google has enabled native image generation capabilities in its Gemini 2.0 Flash language model for developers. According to a company blog post, developers can now test this feature through Google AI Studio and the Gemini API across all supported regions. The integration process requires minimal code, with Google providing an experimental version of Gemini 2.0 Flash (gemini-2.0-flash-exp) for testing.
Built-in multimodal processing enhances accuracy
What sets Gemini's image generation apart is its multimodal foundation. The Large Multimodal Model (LML) combines text understanding, enhanced reasoning, and multimodal input processing to generate more accurate images than traditional image generation models.
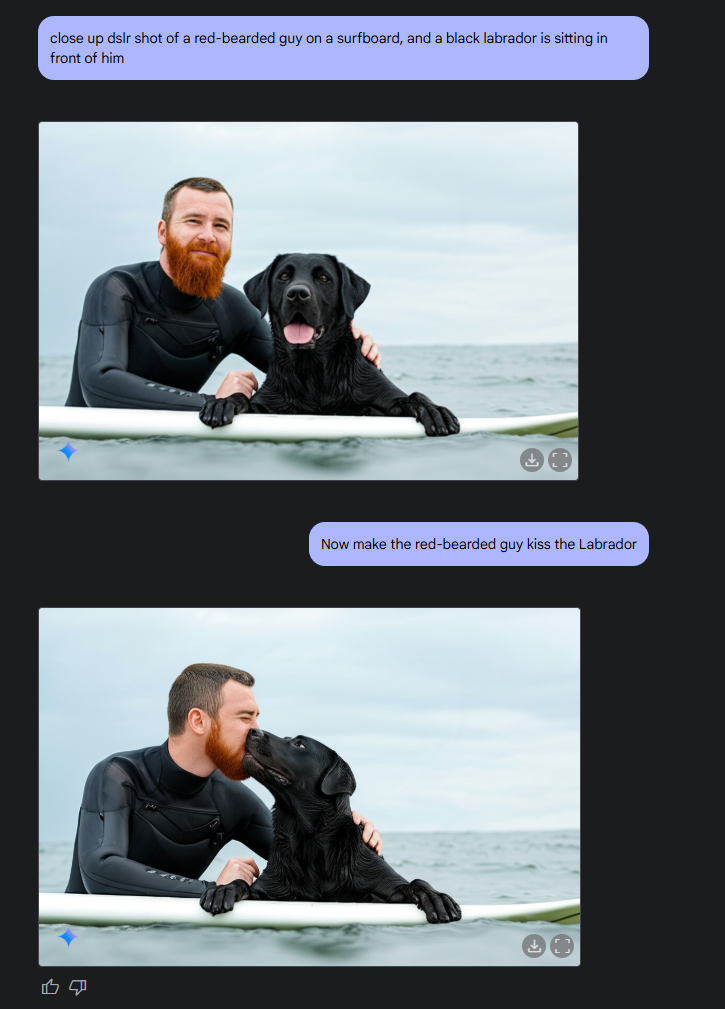
Google says the model can create consistent visual narratives by combining text and images, maintaining character and setting consistency across multiple images. It also enables conversational image editing through multiple dialogue steps, making it particularly useful for iterative improvements while maintaining context throughout the conversation.
Video: via Oriol Vinyals
The model's built-in world knowledge helps create realistic and accurate images, though Google notes this knowledge, while extensive, isn't absolute. The system also excels at incorporating text into images, with internal benchmarks showing superior text integration compared to leading competitor models.
OpenAI rumored to launch multimodal image features in March
OpenAI already showed what's possible in this space with its GPT-4o model back in May 2024. Like Gemini, GPT-4o is built as a native multimodal AI system that can process text, audio, image, and video inputs while generating various outputs including text, audio, and images.
The company demonstrated a range of capabilities, from visual storytelling and detailed character designs to creative typography and realistic 3D rendering. While these features haven't been released to the public yet, industry sources suggest OpenAI will launch them in March 2025 - timing that seems even more likely following Google's announcement. OpenAI employees have also hinted at upcoming image generation features.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.