Google expands access to Gemini 2.5 Pro amid strong benchmark results
Google has opened broader access to Gemini 2.5 Pro, its latest AI flagship model, which demonstrates impressive performance in scientific testing while introducing competitive pricing.
According to Alphabet CEO Sundar Pichai, Gemini 2.5 Pro represents Google's "most intelligent model + now our most in demand." Demand has increased by over 80 percent this month alone across both Google AI Studio and the Gemini API. Starting this week, users can access an expanded public preview with higher usage limits, including a free tier option.
Gemini Web Chat users can continue accessing the 2.5 Pro Experimental model, which should deliver equivalent performance. Google plans additional announcements at its Cloud Next '25 conference on April 9.
Competitive pricing
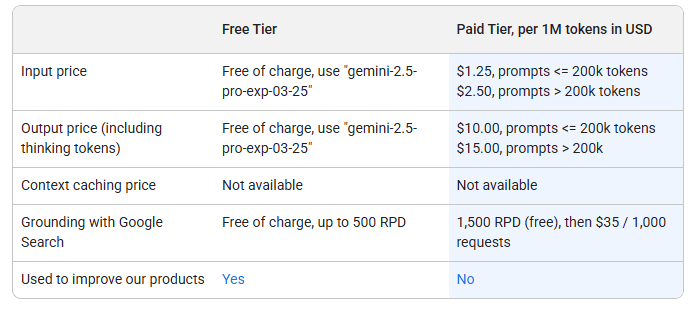
The Gemini 2.5 Pro API follows a tiered pricing model. For prompts up to 200,000 tokens, input costs $1.25 per million tokens, with output at $10. Larger prompts increase to $2.50 and $15 per million tokens respectively. While prompt caching isn't currently available, even in the paid tier, its future implementation could further reduce costs.
Google offers free grounding with Google Search for up to 500 queries per day in the free tier, followed by 1,500 additional free queries in the paid tier. Beyond that, each 1,000 queries costs $35. According to the terms of use, data from the free tier can be used for AI training, while data from the paid tier cannot.
Compared to competing models such as Claude 3.7 Sonnet, Gemini 2.5 Pro is significantly cheaper with the same or better performance. The price-performance battle in the model market therefore continues.
Strong performance in scientific testing
The AI research group EpochAI reports that Gemini 2.5 Pro scored 84% on the GPQA Diamond benchmark - notably higher than human experts' typical 70% score. The benchmark features particularly challenging multiple-choice questions across biology, chemistry, and physics. EpochAI's independent test validates Google's benchmark results.
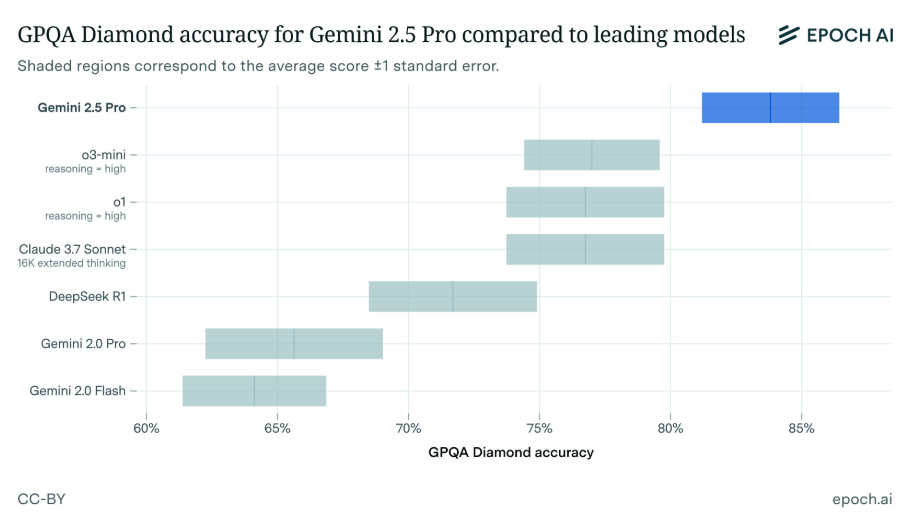
While Google hasn't released technical specifics about the model's architecture, training data, or computational requirements, it's known to be a "reasoning" model similar to OpenAI's o-series. EpochAI notes their testing has been limited by the experimental model's current rate restrictions.
The model's capabilities extend beyond GPQA. On the challenging "Humanity's Last Exam," Gemini 2.5 Pro achieved 18.8% - the highest score among models without additional tools, significantly outperforming competitors like Deepseek-R1's nine percent.
In weekly testing on trackingAI.org, the experimental version demonstrated impressive cognitive abilities, scoring an average IQ of 130 - well above the typical 90-110 range seen in other language models.
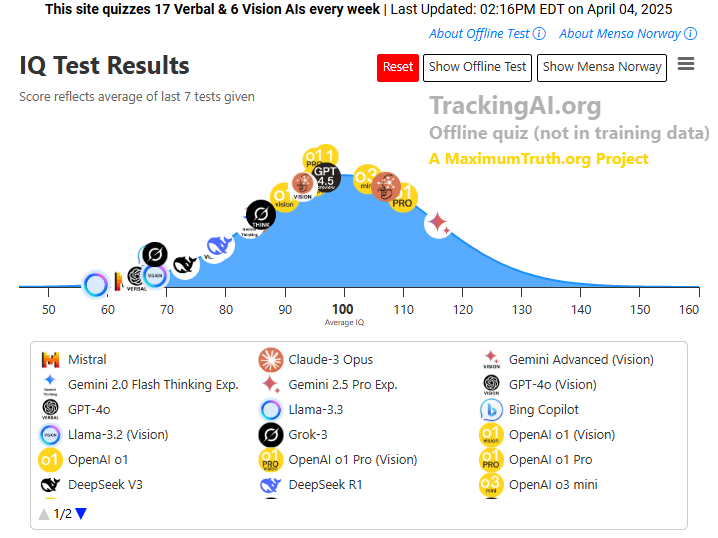
These IQ assessments use text versions of the Norwegian Mensa IQ test, presenting questions verbally rather than visually like traditional vision models. The questions aren't included in training data, and if a model hesitates to answer, it gets up to ten attempts before its last valid response is recorded.
Google's new model has also received consistently positive feedback on X. Computer scientist François Chollet describes Gemini 2.5 Pro as his daily working model. For him, it is the best model for almost all tasks - with the exception of image generation, where it also performs well.
According to investor Martin Casado, he uses it almost exclusively for coding tasks. In his comparison table, Peter Yang rated Gemini 2.5 as currently the best model for programming tasks. Japanese AI researcher Shane Gu praises the model's cost-benefit ratio in particular: Gemini is on the Pareto frontier in all price categories.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.